




Github Pages + Hexo搭建个人博客
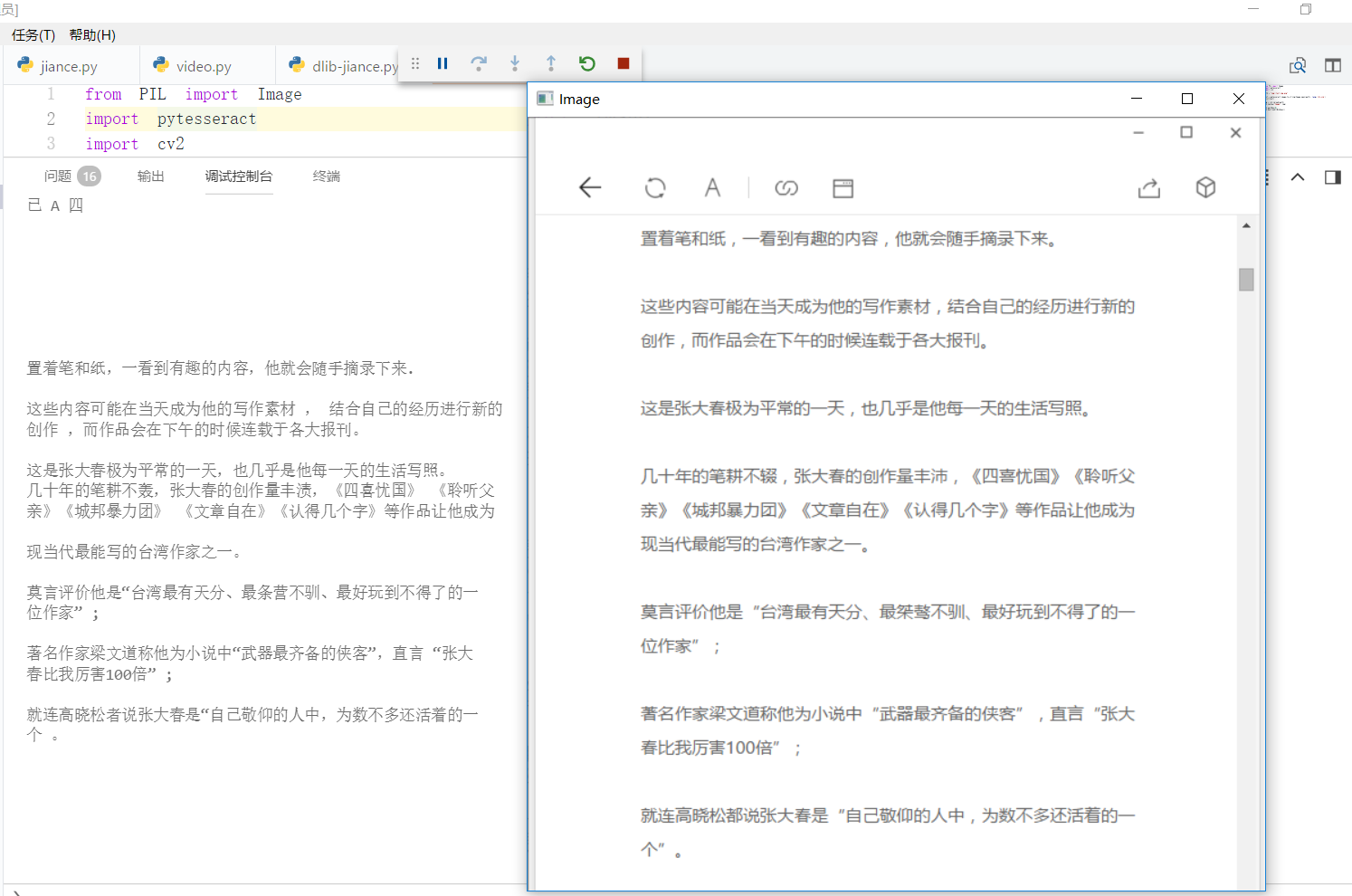
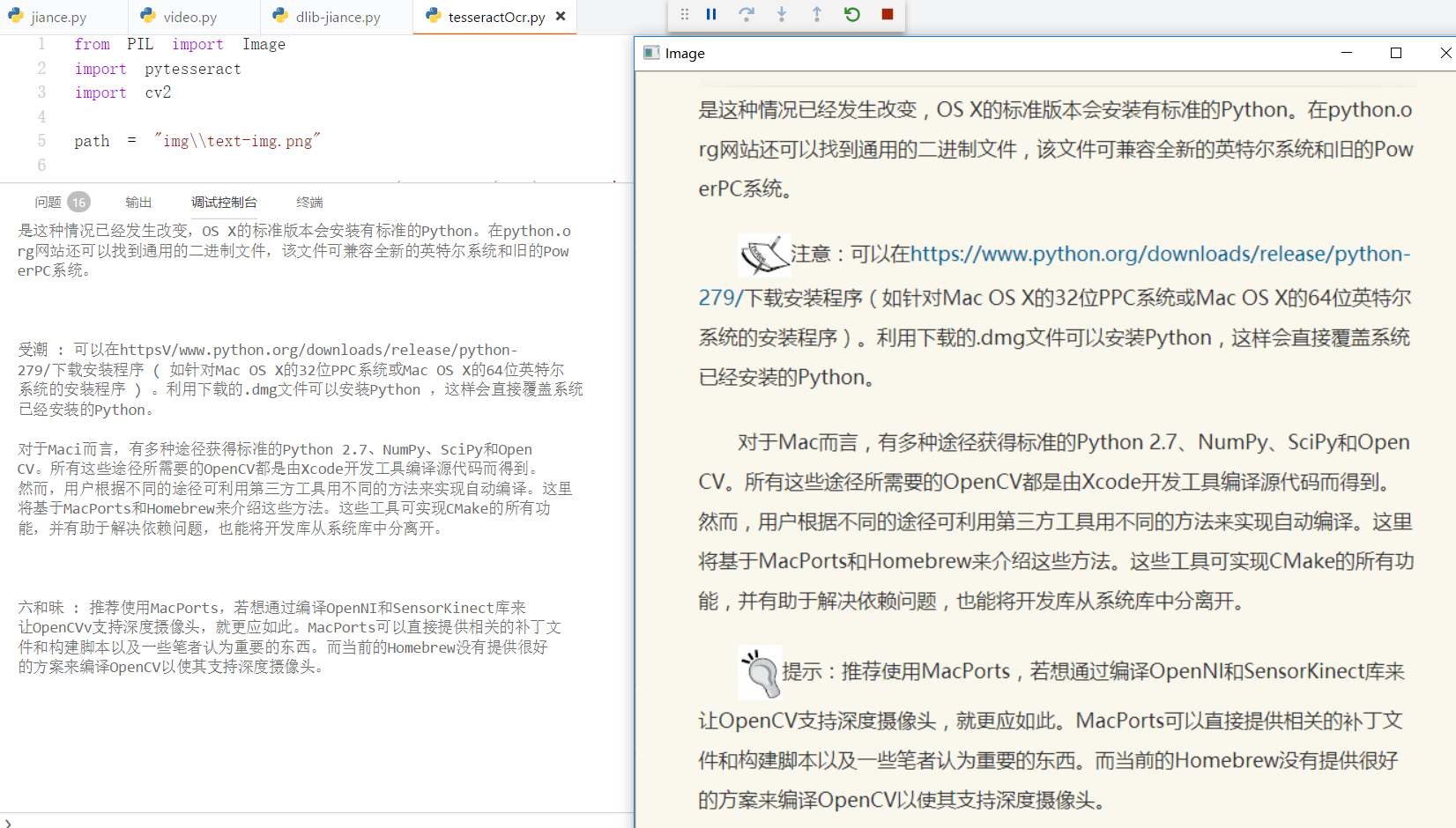
Github Pages +Hexo搭建个人博客 之前在简书上写东西,觉得自己还是太浮躁。本来打算用Flask自己写一个,以为是微框架就比较简单,naive。HTML、CSS、JS等都要学啊,我几乎没有这方面的基础,写到Web表单那儿果断弃了,转向简单的Hexo + Github Pages。不过要想搭建博客的同时巩固Python,Flask确实是一个不错的选择。 获取Github Pages 去Github官网注册账号 新建一个repo,注意名称一定是your_username.github.io这样的格式。 比如你的用户名为zhangsan,Repository name里面就填上zhangsan.github.io 进入刚新建的仓库,点击Setting,一直拖到最下面,选择Automatic Page Generator,随便选个主题然后发布即可。 详细步骤见这个博客 Hexo搭建静态博客 hexo是一款基于Node.js的静态博客框架,Github官方推荐的是Jekyll。对比了下,大多认为hexo比较简单,于是我选择了它。我们需要安装如下软件 Node.js Github f...