记Structured Streaming 2.3.1的OOM排查过程
缘起
最近在使用Structured Streaming开发一套自助配置SQL的来生成流式作业的平台,在测试的过程中发现有些作业长时间运行后会有Executor端的OOM,起初以为是代码的问题,几经review和重构代码,都没有解决,无奈开始了这次OOM的问题排查之路。
干货
出现的问题
Structured Streaming 作业长时间运行后,会出现如下问题
![]()
可以看到spark为我们提供的统计信息,Task的GC时间占到了Task执行时间的70%,起初以为配置的内存不够,但是反复调大内存均出现此问题。
出现这种问题之后,紧接着就会出现Executor和Driver间心跳异常,或者Executor假死的状态,一般出现这类假死、jvm没有响应的问题大都可初步判断为是因为Jvm的Full GC而造成的Stop the World现象。
紧接着再过一段时间之后,在Executor的日志中会出现java.lang.OutOfMemoryError: Java heap space这类异常,导致Executor挂掉。
综上现象,初步推测是因为Executor端出现了内存泄漏。
收集信息
由于作业是从hermes平台提交的,目前的hermes平台还没有提供提交Spark任务打印jvm的gc日志的功能。故决定在线下集群上自己配置一个Spark的客户端,在spark-default.conf里配置driver和executor运行时的jvm参数,使其在进行gc时将gc信息打印出来,配置如下:
spark.executor.extraJavaOptions -verbose:gc -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:OnOutOfMemoryError='kill -9 %p'
spark.driver.extraJavaOptions -verbose:gc -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:OnOutOfMemoryError='kill -9 %p'
这几个参数的意思是配置jvm在发生gc时打印gc的详情信息,当发生OOM异常时,使用kill -9 杀死jvm。
一段GC 日志大概长这样:
0.756: [Full GC (System) 0.756: [CMS: 0K->1696K(204800K), 0.0347096 secs] 11488K->1696K(252608K), [CMS Perm : 10328K->10320K(131072K)], 0.0347949 secs] [Times: user=0.06 sys=0.00, real=0.05 secs]
1.728: [GC 1.728: [ParNew: 38272K->2323K(47808K), 0.0092276 secs] 39968K->4019K(252608K), 0.0093169 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
2.642: [GC 2.643: [ParNew: 40595K->3685K(47808K), 0.0075343 secs] 42291K->5381K(252608K), 0.0075972 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
4.349: [GC 4.349: [ParNew: 41957K->5024K(47808K), 0.0106558 secs] 43653K->6720K(252608K), 0.0107390 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
5.617: [GC 5.617: [ParNew: 43296K->7006K(47808K), 0.0136826 secs] 44992K->8702K(252608K), 0.0137904 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
7.429: [GC 7.429: [ParNew: 45278K->6723K(47808K), 0.0251993 secs] 46974K->10551K(252608K), 0.0252421 secs]
排查过程
等了好久终于又等到Executor假死的现象,通过yarn提供的日志链接,看到这个Executor的GC日志一直在刷,正在进行疯狂的Full GC, 因为Spark是运行在yarn集群上的,所以只能委托公司的OP兄弟,把发生OOM但还没挂掉的Executor的内存镜像保存下来:
jmap -dump:live,format=b,file=dump.hprof $pid
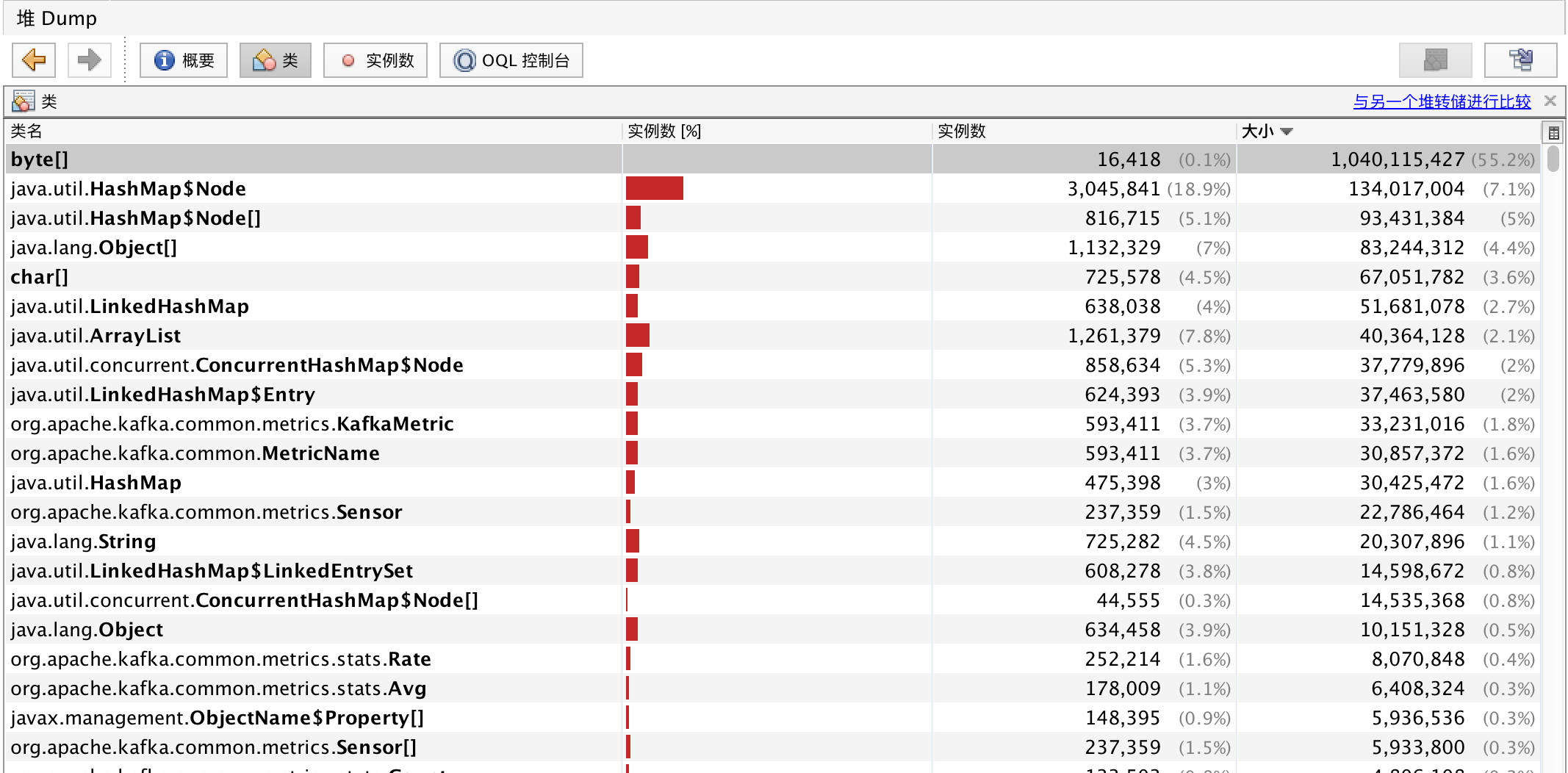
将生成的dump.hprof文件下载到本地,使用java自带的jvisualvm工具打开,将类名根据大小排序,得到如下图:
![]()
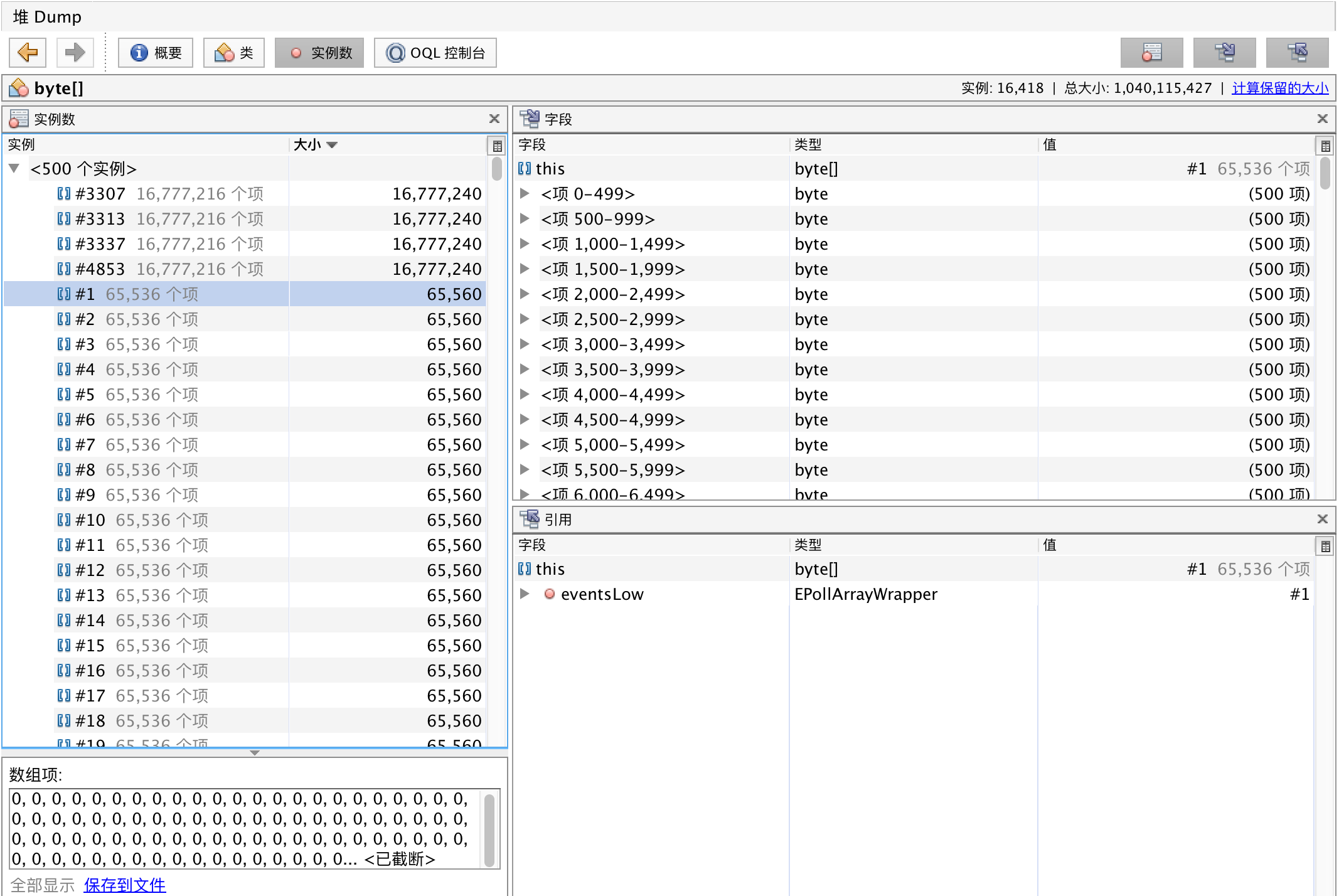
可以看到byte[]类型的对象占了将近1G的内存,明显是发生了内存泄漏。双击这行:
![]()
发现除了绝大多数的字节数组都是65560长度,且内容全为0,而且在右下侧的窗口里发现引用这些字节数组的类都是EPollArrayWrapper类,经过查找发现存在如下类型的类,其数量均为14823,
- sun.nio.ch.EPollArrayWrapper
- sun.nio.ch.EPollSelectorImpl
- sun.nio.ch.SelectorImpl (实现了 java.nio.channels.Selector)
- org.apache.kafka.common.network.Selector
- org.apache.kafka.clients.NetworkClient
- org.apache.kafka.clients.consumer.internals.Fetcher
- org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient
- org.apache.kafka.clients.consumer.internals.ConsumerCoordinator
- org.apache.kafka.common.metrics.Metrics
- org.apache.kafka.common.metrics.JmxReporter
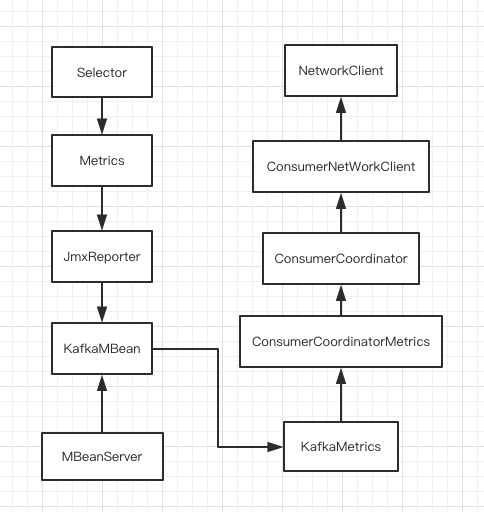
这些都是kafka包里的类,但是名没有发现KafkaConsumer或者KafkaProducer类,而且从日志中看,发现每个批次都会有KafkaConsumer被创建,于是怀疑是KafkaConsumer多次被创建,但是没有回收干净而导致的内存泄漏,查看源码,发现存在如下引用链:
![]()
每次创建KafkaConsumer并进行网络通信后,都会把内部的一些监控信息注册到MBeanServer中,这样在MBeanServer中就存在了如上图的引用链,但是在KafkaConsumer对象被回收的时候,并没有调用其close方法,也就是并没有回收这些对象,这样就造成了内存泄漏。
那么问题来了,为什么会创建如此之多的KafkaConsumer,Structured Streaming没有复用KafkaConsumer的机制么?这显然是不可能的。 所以,我们需要查找在什么情况下会需要额外的创建KafkaConsumer,以及为什么这些创建出来的KafkaConsumer没有被调用close呢。
在Structured Streaming中,整合kafka的代码在
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.3.1</version>
</dependency>
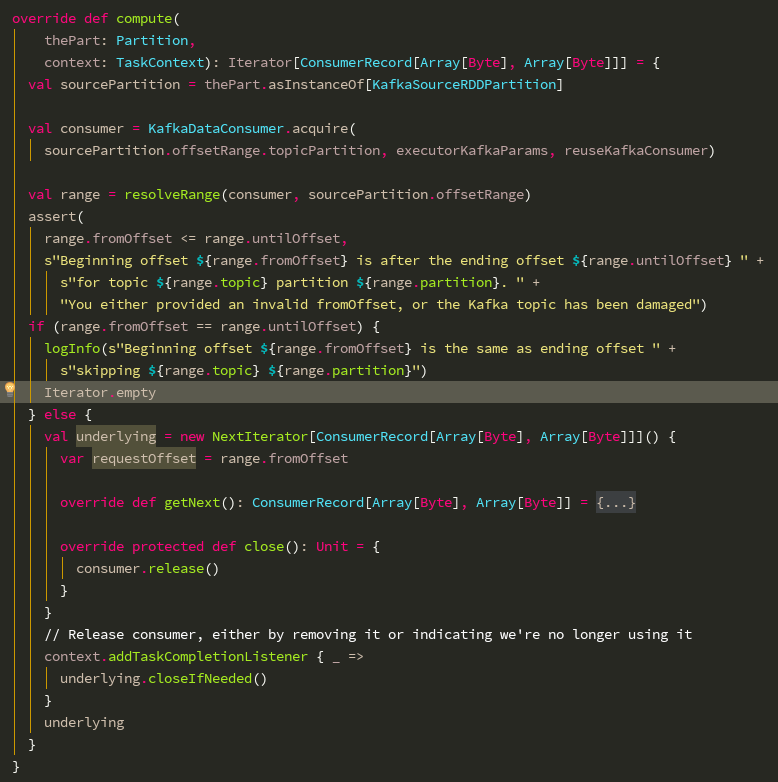
包的KafkaSourceRDD类中,通过添加日志,我们定位到问题代码在compute方法中。
![]()
首先介绍一下KafkaDataConsumer.acquire方法的作用,它会返回一个经过封装的KafkaDataConsumer
def acquire(
topicPartition: TopicPartition,
kafkaParams: ju.Map[String, Object],
useCache: Boolean): KafkaDataConsumer = synchronized {
val key = new CacheKey(topicPartition, kafkaParams)
val existingInternalConsumer = cache.get(key)
lazy val newInternalConsumer = new InternalKafkaConsumer(topicPartition, kafkaParams)
if (TaskContext.get != null && TaskContext.get.attemptNumber >= 1) {
// If this is reattempt at running the task, then invalidate cached consumer if any and
// start with a new one.
if (existingInternalConsumer != null) {
// Consumer exists in cache. If its in use, mark it for closing later, or close it now.
if (existingInternalConsumer.inUse) {
existingInternalConsumer.markedForClose = true
} else {
existingInternalConsumer.close()
}
}
cache.remove(key) // Invalidate the cache in any case
NonCachedKafkaDataConsumer(newInternalConsumer)
} else if (!useCache) {
// If planner asks to not reuse consumers, then do not use it, return a new consumer
NonCachedKafkaDataConsumer(newInternalConsumer)
} else if (existingInternalConsumer == null) {
// If consumer is not already cached, then put a new in the cache and return it
cache.put(key, newInternalConsumer)
newInternalConsumer.inUse = true
CachedKafkaDataConsumer(newInternalConsumer)
} else if (existingInternalConsumer.inUse) {
// If consumer is already cached but is currently in use, then return a new consumer
NonCachedKafkaDataConsumer(newInternalConsumer)
} else {
// If consumer is already cached and is currently not in use, then return that consumer
existingInternalConsumer.inUse = true
CachedKafkaDataConsumer(existingInternalConsumer)
}
}
代码中的useCache参数为true,所以我们只看下面的三个分支就可以了:
- 看cache里是否有指定分区的KafkaConsumer,没有的话会创建一个,放到缓存中,并标记位正在使用的状态
- 如果有的话,但是是正在被使用的状态,会创建一个新的,不被缓存的
- 存在且为可用状态,直接标记为正在使用
我们在compute方法中看到,在下面的else分支里,当任务完成是,会回调迭代器的closeIfNeed方法,底层会调用到KafkaDataConsumer.release方法,针对被缓存的KafkaDataConsumer,将其状态标记位可被使用的状态,而针对不被缓存的KafkaDataConsumer,直接调用其close方法。这个逻辑在compute方法的else分支里是没有问题的。
问题出在compute的if(range.fromOffset == range.untilOffset)的时候,这里直接返回了一个空的迭代器,而并没有将上面获取到的consumer关闭,这就造成了KafkaConsumer内对象的泄漏。
之后在github上找到了修复相关问题的提交: https://github.com/apache/spark/commit/14b50d7fee58d56cb8843994b1a423a6b475dcb5
修复了这个问题,修复的方法就是在返回空的迭代器之前将之前获取到的consumer关闭即可。 但是修复的代码是要发布在2.3.2版本中的,所以我们只能将spark-sql-kafka的源码包下载,集成到项目中来修复这个bug。