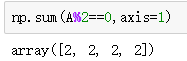numpy是python的一个支持矩阵、向量运算的库,由于python自带的list不仅效率低,也不会将数组看作矩阵或者向量,因此在机器学习中,使用numpy来作为操作数组及矩阵的工具
numpy生成数组或矩阵
numpy.array([i for i in range(10)])numpy.dtypenumpy.zeros(10,dtype=int //该参数可选)numpy.zeros((3,5))numpy.ones(shape=(3,5))numpy.full(shape=(3,5),fill_value=66.0)numpy.arange(10)-
numpy.arange(0,1,0.2) arange函数生成步长相等的数列
-
numpy.linspace(0,20,10) linspace函数生成个数一定的数列
随机数
-
numpy.random.randomint(0,10) 生成[0,10)这个区间的一个随机整数
-
numpy.random.randomint(0,10,size=10) 十个随机整数
-
numpy.random.randonint(0,10,(4,5)) 4*5矩阵的随机整数
-
numpy.random.seed(123) 设置伪随机数种子,在每次random调用前使用相同的种子可得到相同的随机数序列
-
numpy.random.normal() 生成均值为0,方差为1的分布的随机浮点数
-
numpy.random.noraml(5,10,(3,5)) 均值为5,方差为10的3*5矩阵
矩阵属性
x=numpy.arange(10,(3,5))
x.ndim //x的维度
x.shape //x的各维度长度
x.size //x的总元素数量
使用X=x[:2,:2]获取的x的子矩阵,当修改X时同样会改变x的值,修改x也会改变X的值
因此我们如果我们想获得一个和x无关的x的子矩阵,需要使用X=x[:2,:2].copy()
使用y=x.reshape(5,3)可以将3*5的x矩阵改变为5*3的y矩阵,x的值不变
y=x.reshape(5,-1)可以自动帮我们计算出,要将x转换为5行,所需要的列数y依然变为5*3的矩阵
数据合并分割
numpy.concatenate([A,B],axis=1)numpy.vstack(A,B)numpy.hstack(A,B)numpy.split(A,[2],axis=1)numpy.vsplit(A,[2])numpy.hsplit(A,[2])
矩阵运算
矩阵间所有直接使用运算符的运算都只会进行相应元素间的运算
例如
因此如果我们想要进行正常的矩阵运算,需要调用numpy支持的函数,例如乘法
A.dot(B)
-
numpy.linalg.inv(A) 求A矩阵的逆
-
numpy.linalg.pinv(A) 求A矩阵的伪逆矩阵
聚合运算
np.sum(A)-
np.sum(A,axis=0) 沿着维度为0的轴进行求和运算
-
np.prod(A) 对A矩阵求所有元素乘积
-
np.mean(A) 求均值
-
np.median(A) 求中位数
-
np.percentile(A,50) 求第五十个百分位点的数值
-
np.var(A) 求方差
-
np.std(A) 求标准差
索引与排序
-
np.argmin(A) 求A中最小值的索引值
np.argmax(A)-
np.random.shuffle(x) 对x进行乱序处理
-
np.argsort(x) 索引排序
-
np.partition(x,3) 以3为基准线排序
np.argpartition(x,3)
Fancy Indexing
numpy支持将数组作为索引来查询array里的值
查询的数组甚至可以是布尔数组
num.array的比较
该比较方法可以推广到所有比较符以及矩阵
-
np.any(判断条件) 只要变量中有一个元素满足判断条件,返回True
-
np.all(判断条件) 只有所有变量元素满足判断条件,返回Ture
-
np.sum(X%2==0,axis=1) 该命令查看矩阵X沿列方向有多少偶数
-
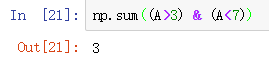
np.sum((x<3) & (x>7)) 计算x中大于3,小于7的元素个数,在该运算中,只使用了一个&符号,也就是说,这里并非条件运算&&,而是位运算&(与运算)