前言
最近WWDC2017刚刚过去两周,作为iOS客户端开发的我,看到了苹果高逼格的Core ML,决定花两天研究研究。
其实机器学习在移动端应用已经有了一定的支持了,Caffe2 已经支持iOS、Android移动端上的应了,但今年iOS11中的Core ML将大大降低了机器学习的门槛。因此,写一篇自己的学习笔记,以及分享下关于深度学习相关的理解,如有不足之处,还请大家多多指正。
Core ML简介
iOS 11的Core ML 大大降低了开发者在苹果设备上使用机器学习技术预测模型的门槛和成本。苹果制定了自己的模型文件格式,统一的格式和全新的 API 设计使得 Core ML 支持苹果生态下多个平台。Core ML 的核心是加速在 iPhone、iPad、Apple Watch 上的人工智能任务,支持深度神经网络、循环神经网络、卷积神经网络、支持向量机、树集成、线性模型等

demo演示
示例在模拟器上运行,读取相册图片,使用Core ML 进行图像识别

可以将经过Caffe框架训练后生成的 .caffemodel 使用coremltools转换工具转成 .mlmodel文件.只需要给定模型的输入,就能得到模型的预测结果。使用了Core ML之后只需要很少的代码就可以构建起一个机器学习的应用。咱们只需要关注模型的预测输出就可以,而避免了关注复杂的模型网络层次。.mlmodel 文件包含了权重和模型结构等信息,并可以自动生成相关的代码,节省开发者大量时间。

Demo实践
- 本demo是以Caffe框架训练出的 .caffemodel模型转换为 .mlmodel 需要以下几个文件:

环境需求:
- 需求: python 2.7 (mac默认的python环境),如果没有,请安装指定环境的python:brew install python==2.7
- 需求: CoreMLTools点击下载页面上的whl文件, 这是转换工具,备用,
- 安装pip ,在 pip 下安装numpy (1.12.1+) , protobuf (3.1.0+) ,six ,setuptools ,wheel,coremltools ,virtualenv
创建:
- 新建文件夹 convert-test , 在文件夹下放入以下文件: bvlc_alexnet.caffemodel , deploy.prototxt ,synset_words.txt , 新建一个python文件,coremlconvert.py如下:
#!/usr/bin/python
import coremltools
coreml_model = coremltools.converters.caffe.convert(
('bvlc_reference_caffenet.caffemodel','deploy.prototxt'),
image_input_names='data',
class_labels = 'synset_words.txt',
)
coreml_model.author = 'Yi Xie'
coreml_model.licence = 'Unknown'
coreml_model.short_description = 'number recogation model'
coreml_model.input_description['data'] ='Input image to be classified'
coreml_model.output_description['prob'] ='Probability of each category'
coreml_model.output_description['classLabel'] ='Most likely image category'
coreml_model.save('BVLC.mlmodel')
转换
- virtualenv -p /usr/bin/python2.7 env
- source env/bin/activate
- pip install coremltools
- python coremlconvert.py
然后就在目录下生成对应的.mlmodel 文件

把.mlmodel 文件拖拽到 Xcode 工程中后,勾选对应的 target,这样 Xcode9生成对应的代码。生成的类名就是 .mlmodel文件,输入和输出的变量名和类型也可以在 Xcode 中查看:

- 同时也会生成相应的头文件: BVLC.h 包含了:BVLCInput、BVLCOutput 以提供测试图片输入和预测结果输出
数据格式处理
由于.mlmodel 输入的数据格式是 CVPixelBufferRef,因此以BLVC为例,我们需要将227*227的RGB的UIImage转换为CVPixelBufferRef数据输入
- (CVPixelBufferRef)pixelBufferFromCGImage:(UIImage *)originImage {
CGImageRef image = originImage.CGImage;
NSDictionary *options = [NSDictionary dictionaryWithObjectsAndKeys:
[NSNumber numberWithBool:YES], kCVPixelBufferCGImageCompatibilityKey,
[NSNumber numberWithBool:YES], kCVPixelBufferCGBitmapContextCompatibilityKey,
nil];
CVPixelBufferRef pxbuffer = NULL;
CGFloat frameWidth = CGImageGetWidth(image);
CGFloat frameHeight = CGImageGetHeight(image);
CVReturn status = CVPixelBufferCreate(kCFAllocatorDefault,
frameWidth,
frameHeight,
kCVPixelFormatType_32ARGB,
(__bridge CFDictionaryRef) options,
&pxbuffer);
NSParameterAssert(status == kCVReturnSuccess && pxbuffer != NULL);
CVPixelBufferLockBaseAddress(pxbuffer, 0);
void *pxdata = CVPixelBufferGetBaseAddress(pxbuffer);
NSParameterAssert(pxdata != NULL);
CGColorSpaceRef rgbColorSpace = CGColorSpaceCreateDeviceRGB();
CGContextRef context = CGBitmapContextCreate(pxdata,
frameWidth,
frameHeight,
8,
CVPixelBufferGetBytesPerRow(pxbuffer),
rgbColorSpace,
(CGBitmapInfo)kCGImageAlphaNoneSkipFirst);
NSParameterAssert(context);
CGContextConcatCTM(context, CGAffineTransformIdentity);
CGContextDrawImage(context, CGRectMake(0,
0,
frameWidth,
frameHeight),
image);
CGColorSpaceRelease(rgbColorSpace);
CGContextRelease(context);
CVPixelBufferUnlockBaseAddress(pxbuffer, 0);
return pxbuffer;
}
模型调用
- (NSString*)result:(UIImage *)image {
BVLC *model = [[BVLC alloc] init];
NSError *error;
UIImage *scaledImage = [image scaleToSize:CGSizeMake(227, 227)];//调整输入图片尺寸
CVPixelBufferRef buffer = [image pixelBufferFromCGImage:scaledImage];
BVLCInput *input = [[catInput alloc] initWithData:buffer];
BVLCOutput *output = [model predictionFromFeatures:input error:&error];
return output.classLabel;//预测结果输出
}
小结
使用了 Core ML之后使得model集成更加的简洁,其支持多种的数据类型,使得模型转化更加的广泛
,同时其支持了硬件的优化,适配了主流的机器学习框架。
附录1 Caffe简单入门
caffe 简介
Caffe 是伯克利视觉和学习中心开发的基于C++/CUDA/phthon实现的卷积神经网络框架,提供了面向命令、Matlab、Python的接口。该框架实现了CNN架构,速度快、由于其利用了MKL、OpenBLAS、cuBLAS等计算库,支持GPU加速。并且他适合做图像特征的提取。Caffe 还提供了一套模型训练、预测、微调、发布、数据预处理、自动化测试的工具,比较适合初学者入门。另外比较常用的还有Google的TensorFlow,微软的Theano.
caffe 环境配置
下载
安装
- brew install -vd snappy leveldb gflags glog szip lmdb
添加science源来安装 OpenCV 和 hdf5
brew tap homebrew/sciencebrew install hdf5 opencv
使用Anaconda Python这个工具包含了大量的Python工具包来解决以上依赖问题而且安装新的软件包也特别容易。如果用Anaconda Python的话HDF5已经包含其中了 可以略过。并且opencv这里有两行需要改一下:
-DPYTHON_LIBRARY=#{py_prefix}/lib/libpython2.7.dylib
-DPYTHON_INCLUDE_DIR=#{py_prefix}/include/python2.7
然后是BOOST和BOOST-Python 安装这个主要是为了之后Python接口的编译
brew install --build-from-source --with-python -vd protobuf
brew install --build-from-source -vd boost boost-python
接着安装Python依赖
for req in $(cat requirements.txt);
do pip install $req;
done
首先mv Makefile.config.example Makefile.config
在编译之前我们需要修改make.config 的几个地方然后 CPU_ONLY := 1 的注释去掉(删除#),
然后就是后面的Python路径,用Anaconda Python的话将下面的注释去掉:
ANACONDA_HOME := $(HOME)/anaconda
PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
$(ANACONDA_HOME)/include/python2.7 \
$(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include\
然后就可以在caffe文件夹下执行make了:
make all
make test
make runtest
make pycaffe
如果出现错误提示为:`fatal error: caffe/proto/caffe.pb.h: No such file or directory`
解决方式:
- protoc src/caffe/proto/caffe.proto --cpp_out=.
- sudo mkdir include/caffe/proto
- sudo mv src/caffe/proto/caffe.pb.h include/caffe/proto
注意:在训练之前需要,确认修改脚本中所引用的.prototxt文件,将最后一行改为solver_mode:CPU
##附录2 Caffe 示例 Mnist
以最经典的Mnist作为介绍:
- 下载Mnist数据集合,可以在Caffe源码框架的data/mnist使用get_mnist.sh进行下载,得到二进制的测试和训练集,caffe 也可以直接以图片集的形式作为输入。
- cd data/minist/
- ./get_mnist.sh
- 转换格式
下载到的原始数据为二进制文件,需要转换为LEVELDB或者LMDB才能被Caffe识别。
执行脚本:`./examples/mnist/create_mnist.sh`
此时在目录下会生成两个目录,每个包含两个文件data.mdb 和 lock.mdb

- 启动Caffe训练
运行:`examples/mnist/train_lenet.sh`
####测试自己图片
- ./build/tools/caffe.bin test -model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel
- ./build/examples/cpp_classification/classification.bin examples/mnist/deploy.prototxt
examples/mnist/lenet_iter_10000.caffemodel examples/mnist/mean.binaryproto examples/mnist/synset_words.txt examples/images/3.jpg
##附录3 卷积神经网路(CNN)
###概述
参考了网上一些博客,总结一下对于CNN的一些理解。**图像分类本质上是对输入图像的操作,最终输出一组最好地描述了图像内容的分类或分类的概率**。想要让计算机能够区分开不同类别的图片,以及各自的特征,这是人大脑自动进行着的过程。当我们看到一幅狗的图片时,如果有诸如爪子或四条腿之类的明显特征,我们便能将它归类为狗。同样地,**计算机也可以通过寻找诸如边缘和曲线之类的低级特点来分类图片,继而通过一系列卷积层级建构出更为抽象的概念。**
卷积神经网络,会联想到神经科学或生物学。CNN是从视觉皮层的生物学上获得启发的。因为在视觉皮层有小部分细胞对特定部分的视觉区域敏感。由于大脑中的一些个体神经细胞只有在特定方向的边缘存在时才能做出反应。**例如,一些神经元只对垂直边缘兴奋,另一些对水平或对角边缘兴奋。所有这些神经元都以柱状结构的形式进行排列,而且一起工作才能产生视觉感知。这种一个系统中的特定组件有特定任务的观点(视觉皮层的神经元细胞寻找特定特征)在机器中同样适用,这就是 CNN 的基础。**
CNN卷积网络的核心思想是将:局部互联、权值共享以及降采样这三种结构思想结合起来获得了某种程度的位移、尺度、形变鲁棒性,以达到图像降维的特征学习与分类
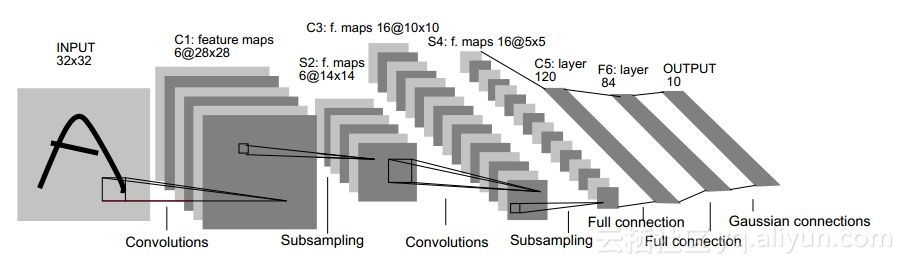
###图像的卷积
####微观角度:
如上图:一张 32 * 32 的图片作为输入,经过卷积得到**C1**的6张 28 * 28的特征图,这个过程称为特征映射。**每层都有多个特征图,对于每个的特征图是由前一层通过卷积运算得来,卷积的运算的作用实质上是对特征的一种提取,同时也是忽略一些无关噪声因素。**对于上图,**C1**的6张特征图是由多个5 * 5的卷积核与输入图像,卷积运算得来,其目的就是为提取原始图像的多种特征。
####宏观角度:
每个滤波器可以被看成是特征标识符。这里的特征指的是例如直边缘、原色、曲线之类的东西。所有的图像都共有的一些最基本的特征。
**知乎上“机器之心”的例子**:一组滤波器是 7 x 7 曲线检测器,作为曲线过滤器,它将有一个像素结构,在曲线形状旁时会产生更高的数值,以提取出图像的中局部的曲线特征。
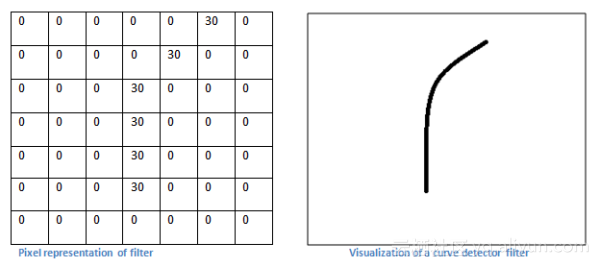
左图:滤波器的像素表示;右图:曲线检测器可视化;对比两图可以看到数值和形状的对应
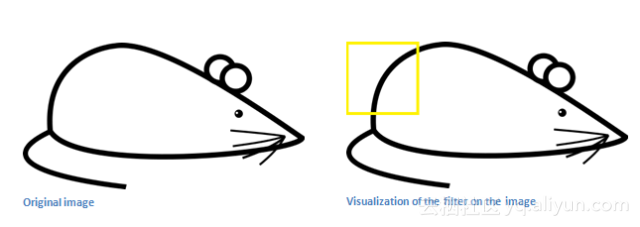
从数学的角度来看,当我们将过滤器置于输入内容的左上角时,它将计算滤波器和这一区域像素值之间的点积。

如果输入图像上某个形状看起来很像过滤器表示的曲线,那么所有点积加在一起将会得出一个很大的值!

在滤波器滑动的过程中,如果没有检测到曲线,这时该卷积得到的值就很小。这是因为图像的这一部分和曲线检测器相似性较小。这本质上卷积层的输出就是一个激活映射。因此,在这个曲线检测器的例子里,激活映射将会显示出图像里最像曲线的区域。过滤器越多,检测的图片特定特征也越多,激活映射的深度越大,对输入的特征也就越多。

**上图是,对输入图像上进行第一次卷积运算得到的特征映射图**
**S2**层是降采样层,根据图像的局部相关特性,对图像进行降采样,减少了参数量,这就是CNN中的稀疏链接。降采样层得到的就是6张14 * 14 的图片,相当于在2 * 2的点阵中取一个点,可以设置取点的规则。
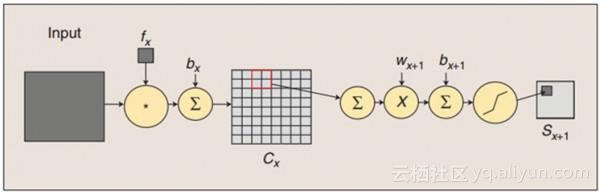
####如上如所示卷积和下采样过程:
- 卷积:用一个可训练的滤波器fx去卷积一个输入的图像(只有输入是图像,之后面的每一层经过就是卷积、采样得到只是图片的特征,相当于每一层的运算,在降低参数量的同时也在提取上一层的特征),然后加一个偏置bx,得到卷积层Cx。
- 降采样:每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个Sigmoid激活函数,产生一个大概缩小四倍的特征映射图Sx+1。 所以从一个平面到下一个平面的映射可以看作是作卷积运算,S-层可看作是模糊滤波器,起到二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。
- 注:深度神经网络中还存在一个问题就是梯度消失,使用Sigmoid、tanh等饱和激活函数时,在神经网络进行误差反向传播时,各个层都要乘以激活函数的一阶导,梯度会衰减,当网络层数过多时,甚至会导致梯度消失。这就使得训练收敛变慢,因此我们会使用ReLU这种非饱和激活函数,以保证收敛速度。(《21天实战Caffe》有详细介绍)
###CNN 相比于ANN优势在于
####局部感受野:
通过感受野和权值共享减少了神经网络需要训练的参数的个数,假设有1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话(每个隐层神经元都连接图像的每一个像素点),就有1000x1000x1000000=10^12个连接,也就是10^12个权值参数。然而图像的空间联系是局部的,就像人是通过一个局部的感受野去感受外界图像一样,每一个神经元都不需要对全局图像做感受,每个神经元只感受局部的图像区域,然后在更高层,将这些感受不同局部的神经元综合起来就可以得到全局的信息了。这样就减少连接的数目,也就是减少神经网络需要训练的权值参数的个数了。如下图右:假如局部感受野是10x10,隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。比原来减少了四个数量级。

####权值共享:
假设隐含层的每一个神经元都连接10x10个图像区域,也就是说每一个神经元存在10x10=100个连接权值参数。如果我们每个神经元这100个参数是相同。也就是说每个神经元用的是同一个卷积核去卷积图像。这样我们就只有100个参数。不管你隐层的神经元个数有多少,两层间的连接我只有100个参数。
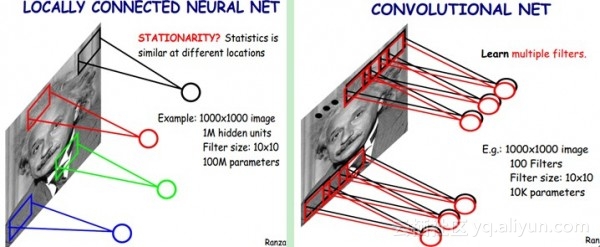
如果仅仅只依靠这100个参数,提取特征,不能很好的提取图像的全部特征。一种卷积核就相当是提出图像的一种特征,例如某个方向的边缘。如果需要提取不同的特征,就要多加几种卷积核。假设有100种滤波器,每种滤波器的参数不一样,表示提取输入图像的不同特征。这样每种滤波器去卷积图像就得到对图像的不同特征的放映,我们称之为特征图。所以100种卷积核就有100个特征图。这100个特征图就组成了一层神经元。一层有参数个数 = 100种卷积核x每种卷积核共享100个参数=100x100=10K。也就是说,隐层的参数个数和隐层的神经元个数无关,只和滤波器的大小和滤波器种类的多少有关。
###CNN 进一步理解
当进入下一层卷积层时,第一层的输入是原始图像,而第二卷积层的输入正是第一层输出的激活映射。也就是说,这一层的输入大体描绘了低级特征在原始图片中的位置。在此基础上再采用一组滤波器(让它通过第 2 个卷积层),输出将是表示了更高级的特征的激活映射。**随着网络越深和经过更多卷积层后,将得到更为复杂特征的激活映射。越深入网络,过滤器的感受野越大,意味着它们能够处理更大范围的原始输入内容(或者说它们可以对更大区域的像素空间产生反应)。**
检测高级特征之后,最后就是完全连接层,**这一层处理输入内容(该输入可能是卷积层、ReLU 层或是池化层的输出)后会输出一个 N 维向量,N 是该程序必须选择的分类数量。**例如,如果你想得到一个数字分类程序,像Mnist那样对手写数字进行分类,10个数字,N 就等于10。这个 N 维向量中的每一数字都代表某一特定类别的概率。
针对于某一个数字分类结果矢量是: [0 0 .2 0 .55 0 0 .2 0 .05],这就意味着该图片有 20% 的概率是 2、55% 的概率是 4、20% 的概率是 7、还有 5% 的概率是 9。完全连接层观察上一层的输出(其表示了更高级特征的激活映射)并确定这些特征与哪一分类最为吻合。如果像本例demo中可以检测山地车、飞机、手机等日常物体的程序。当预测某一图像的内容为山地车时,那么激活映射中的高数值便会代表一些车轮或脚踏板之类的特征。同理,如预测某一图片的内容为飞机,激活映射中的高数值便会代表诸如机翼等高级特征。完全连接层观察高级特征和哪一分类最为吻合和拥有怎样的特定权重,因此当计算出权重与先前层之间的点积后,你将得到不同分类的正确概率。






