千问宣布正式开源发布 Qwen-AgentWorld —— 首个原生语言世界模型(Language World Model, LWM),能够在七大领域中模拟智能体交互环境:
- 原生世界建模: 环境建模从继续预训练(CPT)阶段起即为训练目标,贯穿 CPT → SFT → RL 全流程,而非对通用大语言模型的事后适配。
- 七大领域,一个模型:单一模型同时覆盖文本类环境(MCP、Search、Terminal、SWE)与 GUI 类环境(Web、OS、Android),实现跨领域知识迁移。
具体来说,团队首先构建了智能体环境模拟的基础模型:Qwen-AgentWorld 是首个在单一模型中覆盖七大智能体交互领域(MCP、Search、Terminal、SWE、Web、OS、Android)的语言世界模型,基于超过 1000 万条真实环境交互轨迹,经由 CPT → SFT → RL 三阶段训练而成。
其次是探讨世界建模在智能体训练中的作用,并通过两种互补范式加以验证:作为解耦的环境模拟器,它为智能体强化学习提供了更优的可扩展性与可控性——可控的模拟 RL 能够以真实环境无法实现的方式塑造智能体行为,且显著优于仅在真实环境中训练的 RL;作为统一的智能体基础模型,LWM 预热训练可有效迁移至涵盖七个基准(其中三个完全未出现在训练集中)的多轮智能体任务,且无需在智能体任务上进行任何 RL 微调,初步验证了语言世界模型能够作为构建更强智能体模型的基础。
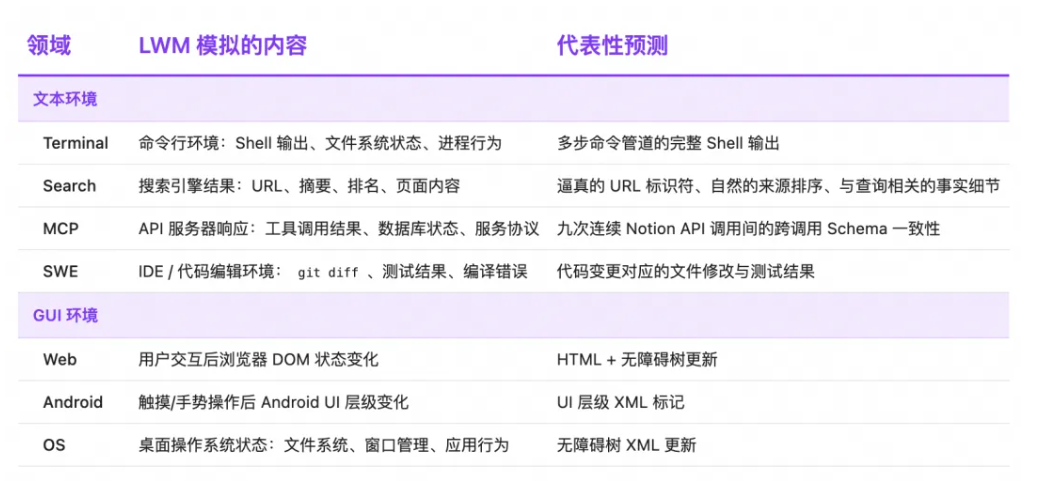
同步发布的还有一个覆盖七大领域的语言世界模型评测基准 AgentWorldBench,每条测试样本均配备真实环境执行所得的真实环境观测数据。
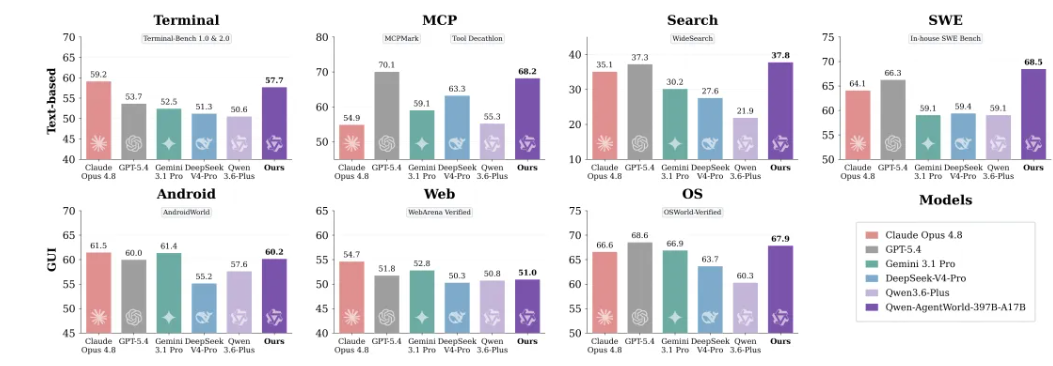
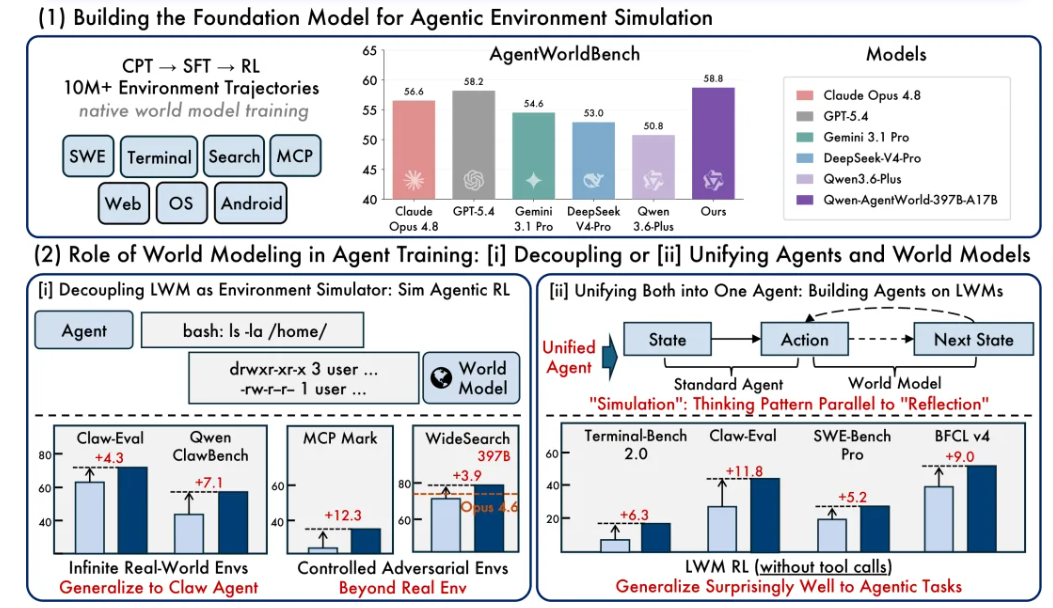
Qwen-AgentWorld-397B-A17B 在 AgentWorldBench 上取得最高的整体均分(58.71),超越 GPT-5.4(58.25)及所有其他前沿模型。优势在 Terminal 和 SWE 两个领域最为显著,这两个领域的预测需要准确建模代码执行状态和工具 API 行为。
在 35B-A3B 规模上,三阶段训练流水线将整体均分提升了 +8.66(47.73 → 56.39),使 Qwen-AgentWorld-35B-A3B 超过 Claude Sonnet 4.6(56.04)。这一提升在文本类和 GUI 类领域上均保持一致。
