2026 年 6 月 22 日,东京 AI 公司 Sakana AI 正式发布了 Fugu——"用一个模型指挥所有模型"的多 Agent 编排系统。Fugu 的核心赌注是一个越来越被 AI 产业认真对待的命题:AI 能力的下一步提升不会来自造出更大的单一模型,而是来自让多个已有模型协同工作。为了实现这个赌注,Sakana AI 将两篇 ICLR 2026 论文——TRINITY 和 Conductor 的研究成果打包成一个 OpenAI 兼容的 API 端点。对调用者来说,它就是一个模型;但在 Fugu 内部,一个轻量级协调器正在动态挑选 Thinking、Working、Verifying 三种角色的 Agent,将任务拆分、委托、验证、整合,最后把结果返回给用户——整个过程对用户不可见,也不可配置。
Sakana AI 是一家值得认真对待的公司。2023 年 7 月在东京成立,三位联合创始人各代表一个稀缺的能力维度:CEO David Ha 是前 Google Brain 研究科学家,曾领导 Stability AI 的研究团队;CTO Llion Jones 是那篇改变了整个 AI 产业走向的论文《Attention Is All You Need》的合著者之一,Transformer 架构正是出自这个研究小组;COO Ren Ito 曾任职于日本外务省,为公司提供了在政府关系和地缘政治维度上的判断力。这家公司在 2024 年 9 月完成约 2 亿美元的 A 轮融资后成为日本估值最高的 AI 独角兽,2025 年 11 月又以约 26 亿美元的估值完成了 1.35 亿美元的 B 轮融资,投资者包括 Khosla Ventures、Lux Capital、NEA、NVIDIA、三菱 UFJ 金融集团和三井住友银行。它的核心研究路线是"从自然界获取灵感的可持续 AI"——不追求最大的参数规模,而是研究如何让较小的模型通过进化和集体智能的方式达到超越单体模型的效果。

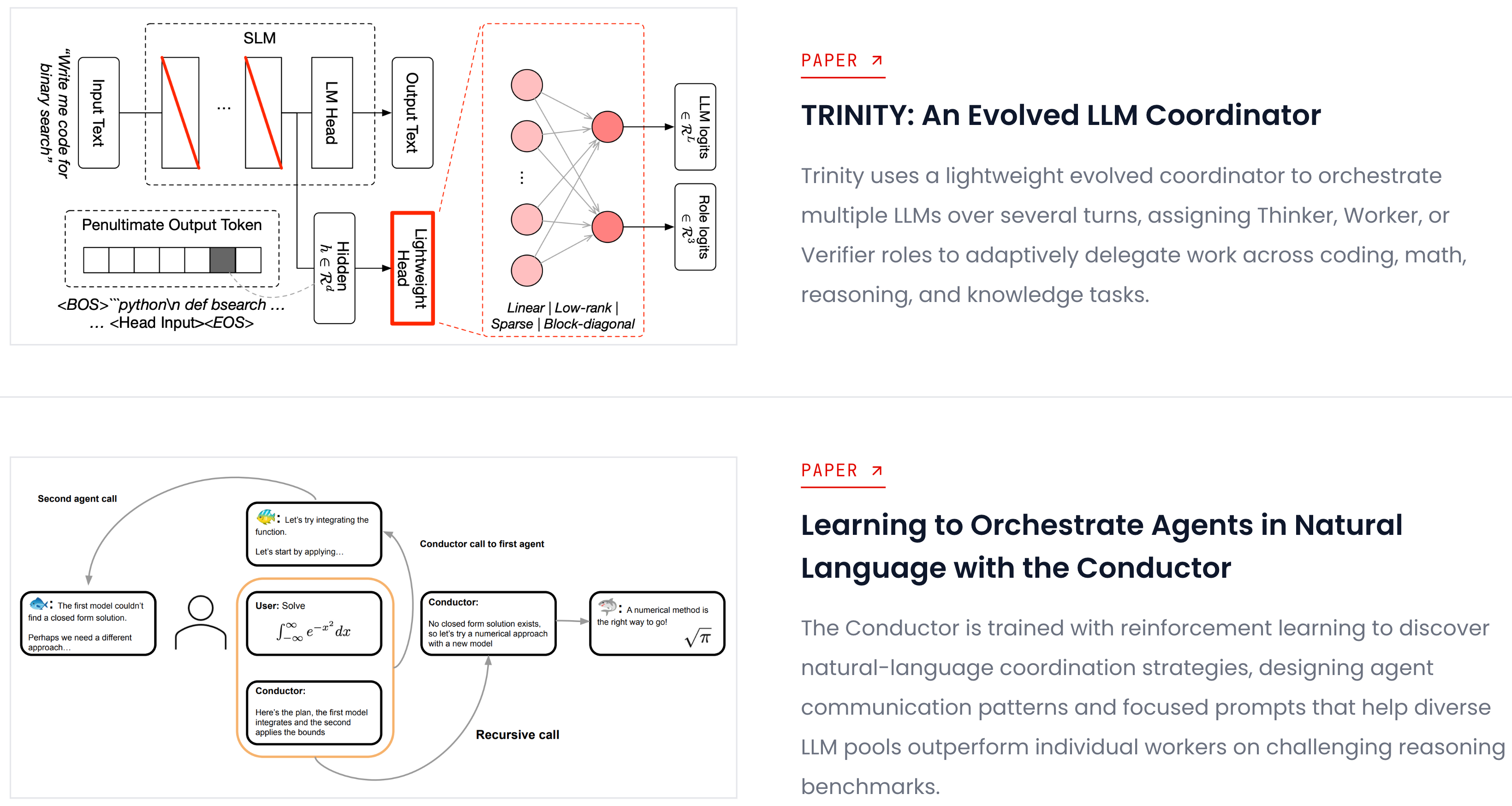
Fugu 的架构本质上是一个学习出来的协调系统,而不是人工设计的路由规则。TRINITY 论文的核心贡献是一个经过进化算法训练的轻量级协调器,它能在多个推理轮次中动态为 LLM 分配 Thinker、Worker 或 Verifier 角色。Conductor 论文则更进一步——通过强化学习训练协调器自动发现自然语言的 Agent 通信模式和提示策略,使得不同能力的 LLM 池在推理任务上的集体表现超过其中任何个体模型。换句话说,Fugu 的协调策略不是工程师手写的,而是机器自己在大量实验中摸索出来的最优协作模式。这也解释了为什么 Sakana AI 刻意不公开 Fugu 内部使用的具体模型列表和路由策略——这套协调模式本身就是核心竞争力,暴露它等于暴露配方。
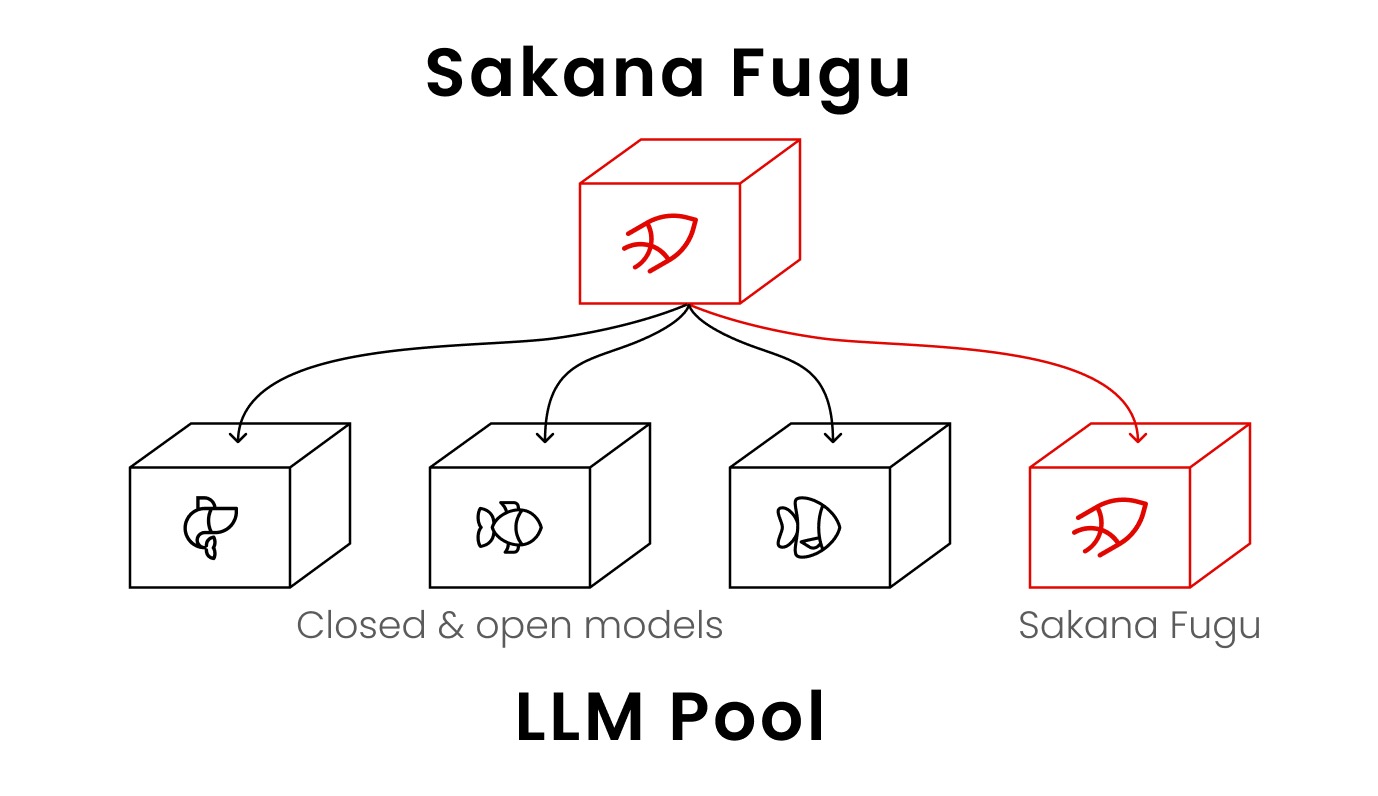
Sakana AI 将 Fugu 分为两个变体。Fugu 在性能和延迟之间取平衡,面向日常编码、分析和聊天场景;Fugu Ultra 使用更深更大的 Agent 池,固定参与模型不可由用户剔除,目标是将答案质量推到最高——这意味着一次 Fugu Ultra 调用可能在内部并行触发多次推理、相互验证、最终合成,耗时和 Token 消耗都显著高于 Fugu。在定价上,Sakana AI 做了一个值得注意的设计决定:当 Fugu Ultra 内部多个 Agent 同时工作时,计费基于参与模型的最高一档费率,而不是逐个 Agent 叠加。这个"不叠加计费"的策略降低了开发者对多 Agent 系统隐性成本的恐惧——你不必因为系统在内部做了更多思考而被惩罚性收费。
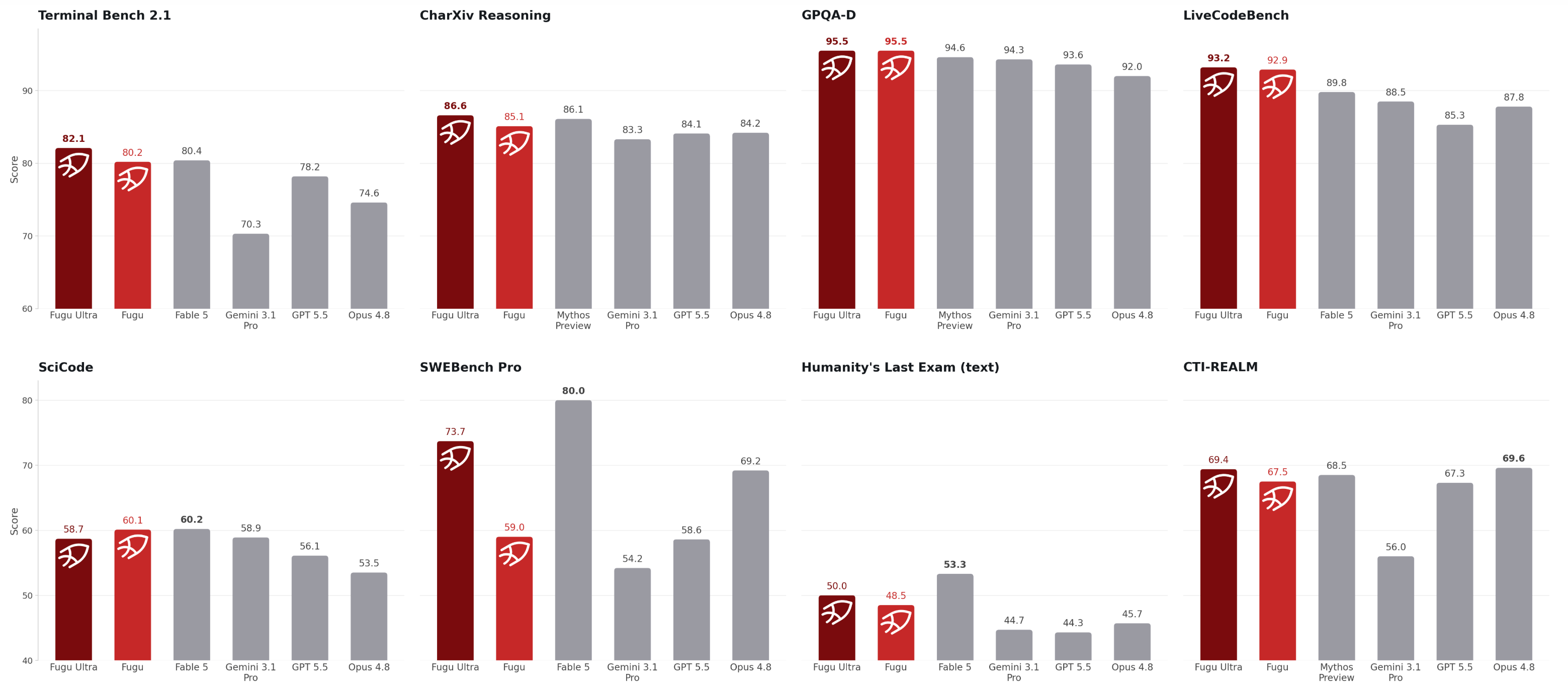
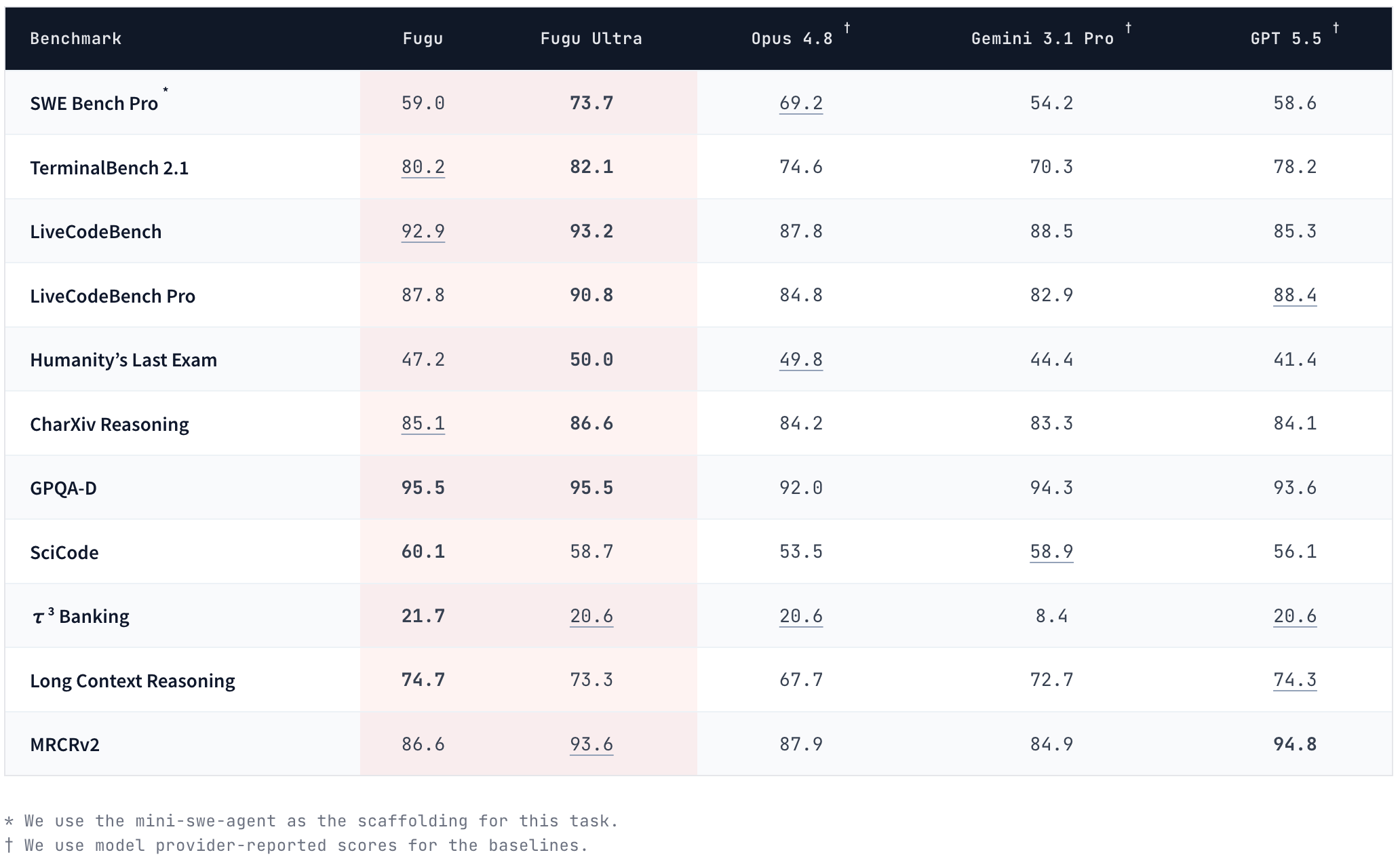
Fugu Ultra 的基准测试数据足够有说服力。在 SWE Bench Pro 上,Fugu Ultra 以 73.7 的得分超越 Opus 4.8 的 69.2 和 GPT-5.5 的 58.6,仅次于——但 Sakana AI 特别声明不在 Agent 池中使用的——Anthropic 的 Fable 5 和 Mythos Preview。在 TerminalBench 2.1 上,Fugu Ultra 得分 82.1,超过 Fable 5。在 LiveCodeBench Pro 上得分 90.8,在 GPQA-D 上拿到 95.5,在 Humanity's Last Exam 上以 50.0 与 Fable 5 持平。这些数据建立在一个关键限制之上:Fugu Ultra 没有使用 Anthropic 的最新模型作为底层 Agent,因为它根本没有权限访问它们——Anthropic 的模型在 Fugu 的 Agent 池之外。Sakana AI 用这个对比试图证明:一个有良好协调能力的多模型系统,即使不包含最强的单一模型,也能在整体表现上追平甚至超越它。
定性展示部分同样值得关注。在六个演示案例中,Fugu Ultra 在完全自主模式下进行了约 14 小时、123 次实验,在一个 BPB 优化任务上将损失从 Agent A 的 0.9822 压缩至 0.9774;在盲棋对弈中,Fugu 连续击败三个前沿模型和一个 Elo 2100 的 Stockfish 引擎,全程没有棋盘显示;在 CAD 机械光圈设计中,Fugu Ultra 产出了唯一能正常工作的曲柄连杆机构;在交易模拟中,Fugu Ultra 实现了 19.43% 的累计收益,而所有对比模型均低于 15%。这些案例的共同特质是:它们都是多步骤、需要多轮验证和修正才可能完成的任务——恰好是单模型容易在中间某步出错后一路漂移的场景。
早期用户的口碑给出了更具体的画面。一位软件工程师在代码审查中报告 Fugu Ultra"比 GPT-5.5 明显更好",在其他模型发现约三个问题时 Fugu Ultra 发现了超过二十个。一位平台架构负责人强调 Fugu 在长会话中的"人设稳定性"异常出色——其他前沿模型在长对话中容易出现的身份漂移在 Fugu 上几乎没有。一位安全工程师用一条指令驱动 Fugu 完成了从信息收集、XSS 和 SQL 注入检测、到认证审查和报告生成的完整安全评估流程。一位研究人员报告 Fugu 自主运行了近四个小时——阅读论文、实现代码、训练模型、评估结果——几乎没有人类干预。
Fugu 的发布时机本身就带有地缘政治意味。Sakana AI 在公告中明确提到了 Anthropic 模型近期的出口管制事件,将其定性为"单供应商依赖是一种实质性的脆弱性"。Fugu 的设计直接回应了这个风险:Agent 池完全可替换,一旦某个供应商限制访问,Fugu 可以动态绕过该模型继续工作。Sakana AI 将这个能力标签为"AI 主权"——对于一个总部设在东京、主要投资者包括日本三大金融集团的公司来说,这个叙事在亚太市场有明确的受众。美国 AI 公司对尖端模型的出口限制正在为日本、韩国和欧洲的替代方案创造市场空间,Fugu 精准地站到了这个缺口上。
Fugu 的定价结构分为两轨。订阅轨面向个人和团队:Standard 每月 20 美元,Pro 100 美元(约为 Standard 的 10 倍用量),Max 200 美元(约 20 倍用量),所有订阅均可同时使用 Fugu 和 Fugu Ultra。企业按量付费轨中,Fugu 按底层模型的公开费率计费,Fugu Ultra 的输入价格为每百万 Token 5 美元(上下文超过 272K 时翻倍至 10 美元),输出价格为每百万 Token 30 美元(超长上下文时 45 美元),缓存输入为 0.50 美元。六月订阅可获第二个月免费。公司声明企业 Token 的优先级高于订阅用户的 Token。目前 Fugu 在欧盟和欧洲经济区不可用,公司正在推进 GDPR 合规工作。
Fugu 代表的是 AI 产业发展方向中的一个有意义的转折信号。从 2023 年到 2025 年,行业的共识是"更大的模型 = 更好的结果",Scaling Law 统治一切。但 2026 年上半年的几个事件——Anthropic 出口管制、模型能力增长趋缓的广泛讨论、以及企业客户对单一供应商依赖的焦虑——正在推动一个新的共识形成:下一个前沿不是训练一个更大的模型,而是学习如何让现有模型以更聪明的方式协作。Fugu 是这个新共识下第一个封装为标准化 API 产品的答卷。它是否真的能持续超越它所编排的模型中的最佳者,还需要更多独立验证;但它已经把一个此前只存在于学术界的概念——通过学习而非手工规则来编排多 Agent 系统——变成了一个任何人都可以调用的服务。剩下的问题是:开发者愿意为一个"黑箱协调器"支付溢价吗?这个问题的答案将在接下来几个月的实际使用数据中逐渐浮现。
参考来源:
