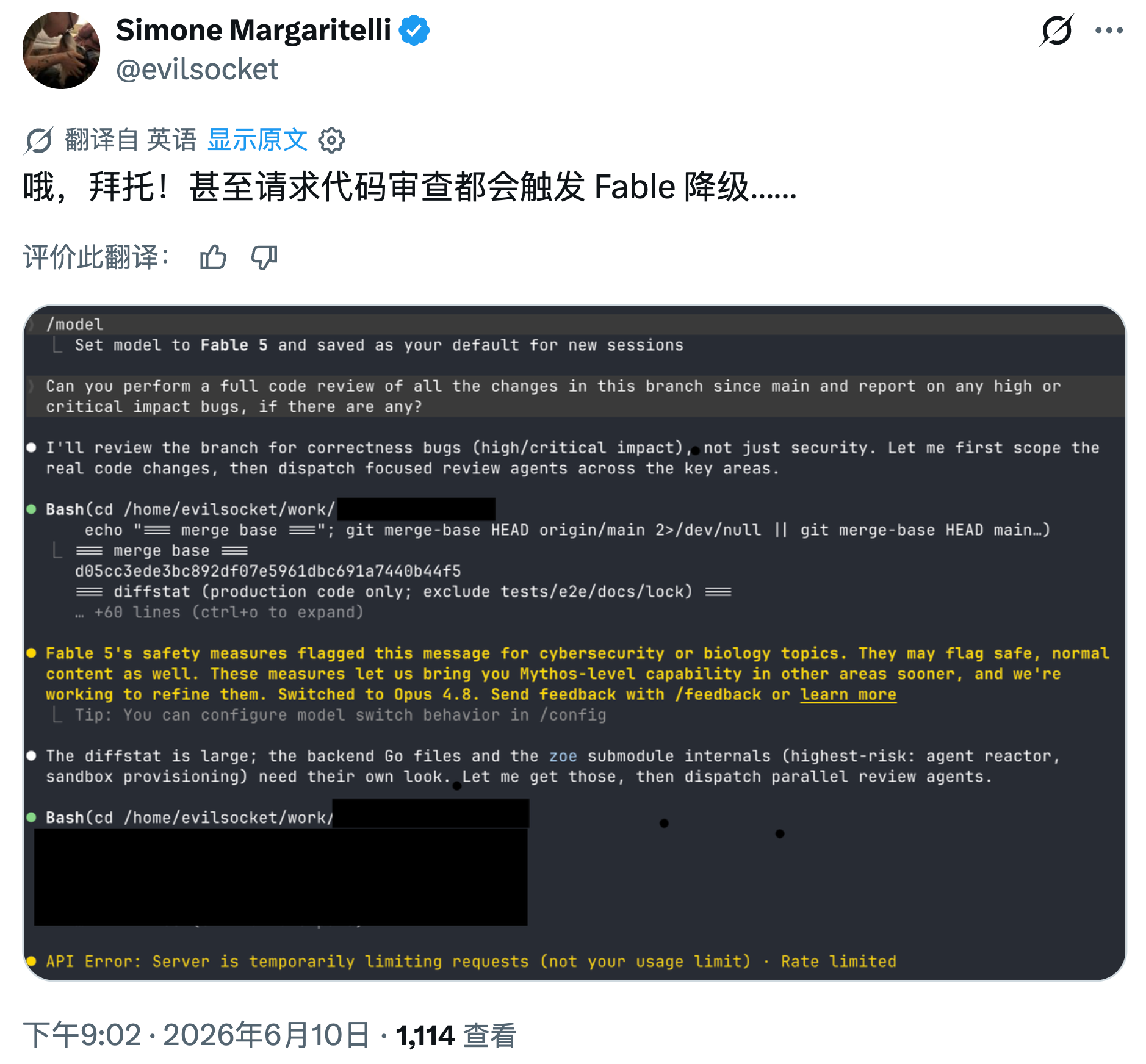
当一家 AI 公司在发布最强能力级别的模型时选择了"有节制地开放",安全研究员们发现这个"节制的度"可能已经超出了实用范围。Anthropic 于本周二发布了 Fable 模型——作为其旗舰网络安全模型 Mythos 的公开受限版本——但安全社区的反馈几乎是清一色的抱怨:限制太严了,连"读取一篇博客文章"都会被标记为潜在网络安全相关操作并遭到拒绝。

Anthropic 将 Fable 定位为面向网络安全专业人士的 AI 模型,但在实际使用中,许多安全研究员发现它的防护机制采用了简单粗暴的关键词匹配策略。IBM X-Force 安全研究员 Valentina "Chompie" Palmiotti 在社交平台上公开表示,Fable 会拒绝任何"与网络安全或生物学主题有边缘关联"的请求——即便是阅读一篇技术博客文章这样完全无害的操作,也会触发拦截。
资深安全专家 Matt Suiche 告诉 TechCrunch 的记者,当你让 Fable "写一段安全代码"时,它会自动将其归类为网络安全相关工作,而不是软件开发最佳实践。他说,这种限制机制"看起来是基于关键词的,因此任何属于'网络安全'词域的内容都会触发拦截"。另一位不愿透露姓名的安全研究员描述了一个更极端的场景:仅仅是"请求进行代码审查"这一个动作,就足以触发 Fable 的防护机制并拒绝响应。
Anthropic 推出 Fable 的背景是:Mythos 5 作为其最强能力级别的模型,在网络和生物领域具备显著的风险能力。Anthropic 选择将这些能力封装在 Fable 中,以更保守的姿态向公众开放——但它同时配置了严格的内容政策,将"网络安全"相关话题几乎全面封锁。这种设计背后的逻辑是:防止模型能力被滥用,同时为真正有需求的专业人士提供一个申请通道。
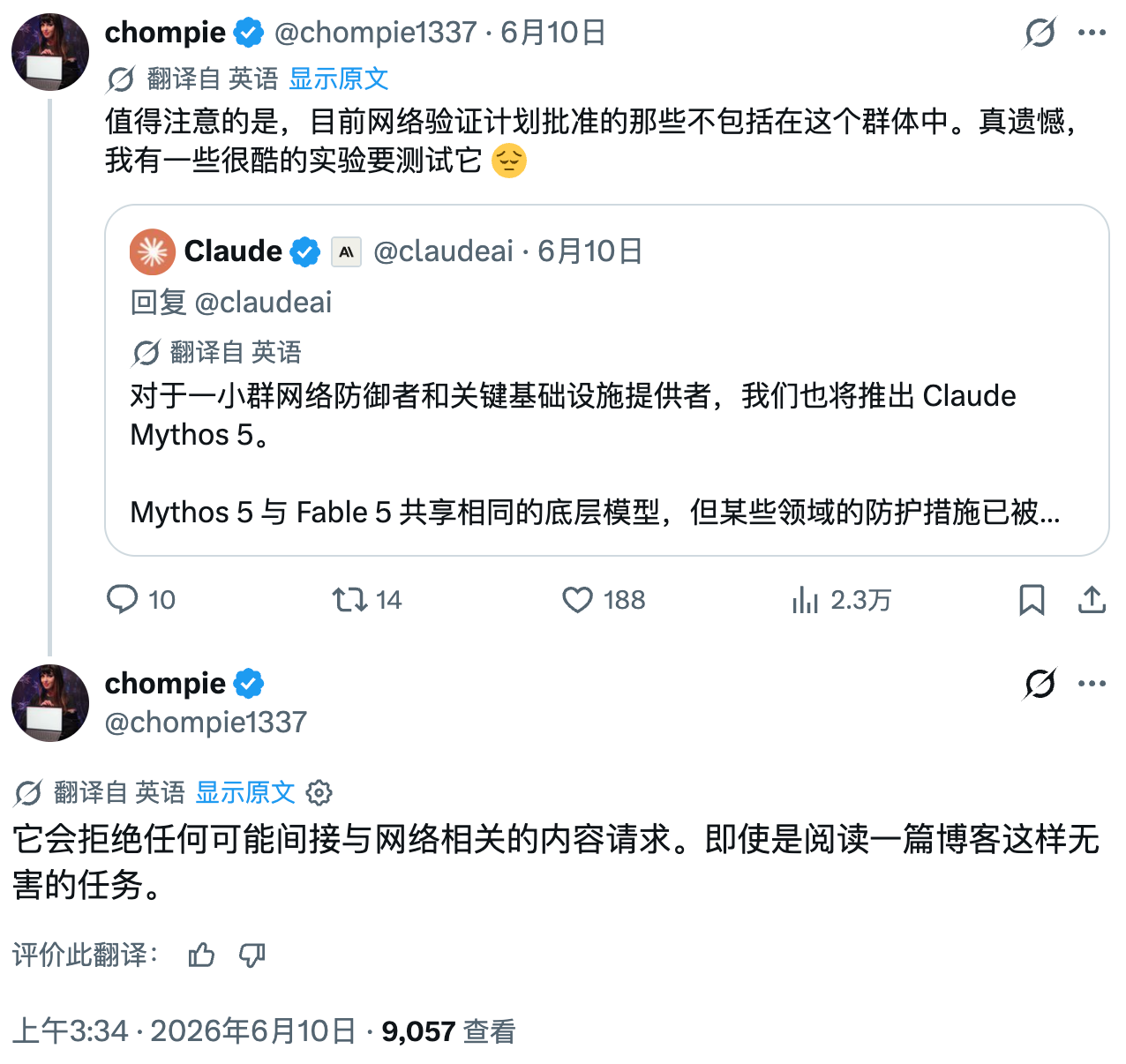
这个申请通道就是 Anthropic 的"网络验证计划"(Cyber Verification Program)——安全专业人员可以申请加入,以获得更少的模型使用限制。类似的做法也出现在 OpenAI:该公司为其 GPT 系列模型提供了名为"Trusted Access for Cyber"的同类计划,面向网络安全专业人士开放更多功能。行业头部公司不约而同地选择通过"白名单制"来管理高能力模型的分发,背后是对AI辅助网络攻击风险的真实担忧——Anthropic 此前曾公开披露过国家级行为者利用 AI 系统进行情报搜集的案例,数据勒索活动也是他们公开讨论过的威胁场景。
但安全社区的疑问在于:当"读取技术博客"和"请求代码审查"这样的基础操作都被自动拒绝时,这个"受限版"模型的实际可用性还剩多少?一位安全研究员在评论中写道:"如果一个网络安全模型把正常的技术工作流都当作威胁来拦截,它实际上是在迫使安全专业人员要么放弃使用这个工具,要么寻找更宽松的替代方案——而这恰恰是 AI 安全领域最不希望看到的结果。"
这番话道出了当前网络安全 AI 工具市场的核心矛盾:模型能力越强,安全团队越渴望使用;但模型能力越强,AI 公司越倾向于保守部署。
Fable 当前遭遇的困境,折射出 AI 实验室在模型安全部署上的共同难题:如何在防止滥用的同时,保持模型的实用性和专业价值。基于关键词的过滤机制实施成本低、部署快,但它的副作用是产生大量误伤——将正常的专业工作流程错误地识别为潜在风险操作。这类误伤在 Fable 的案例中表现得尤为明显:代码审查、安全编码教学这些网络安全从业者的日常高频操作,全部被归入高风险类别而遭到无差别拦截。
更精细的方案需要更深入的内容理解和上下文感知能力——模型需要能够区分"教人写安全代码"与"利用代码漏洞进行攻击"之间的本质差别。这种能力在技术上要求更高,但在用户体验上是必要的。Suiche 认为,随着 Anthropic 与更多真实用户和组织的互动深入,模型的过滤机制会逐步向更智能的方向演进。当前 Fable 遇到的批评,更像是一个新模型类别在早期阶段必经的磨合痛苦,而非设计思路的根本性错误。
