Anthropic工程团队最近发布了一篇文章,详细披露了他们在三款产品中构建AI Agent安全隔离系统的经验和教训。这三款产品分别面向不同的使用场景:面向普通用户的claude.ai、面向开发者的Claude Code,以及面向企业协作的Claude Cowork。每款产品的风险模型和隔离策略各不相同,但都遵循同一个核心原则:环境层隔离优先,模型层引导其次。
在面向用户的claude.ai产品中,Anthropic采用了临时性的容器方案。每个会话启动时,服务器端会创建基于gVisor的容器,会话结束后立即销毁。这种设计的逻辑是:用户与AI的交互本身是短暂的,不需要持久化任何状态,因此可以采用最小化的隔离策略——容器内资源受限,能访问的能力也受到严格限制。一旦发生风险事件,爆炸半径被控制在单次会话范围内。
Claude Code的隔离方案则针对开发工作流进行了优化。开发者需要在工作目录中读写文件,但不能默认访问网络。Anthropic使用操作系统级的沙箱机制——macOS上的Seatbelt和Linux上的bubblewrap——来实现这一隔离。这种设计的精妙之处在于,它在安全和便利之间取得了平衡:默认情况下禁止网络访问,减少了权限提示的弹出频率,据披露这一优化使权限提示减少了84%。当开发者真正需要网络访问时,可以在明确授权后临时开放。
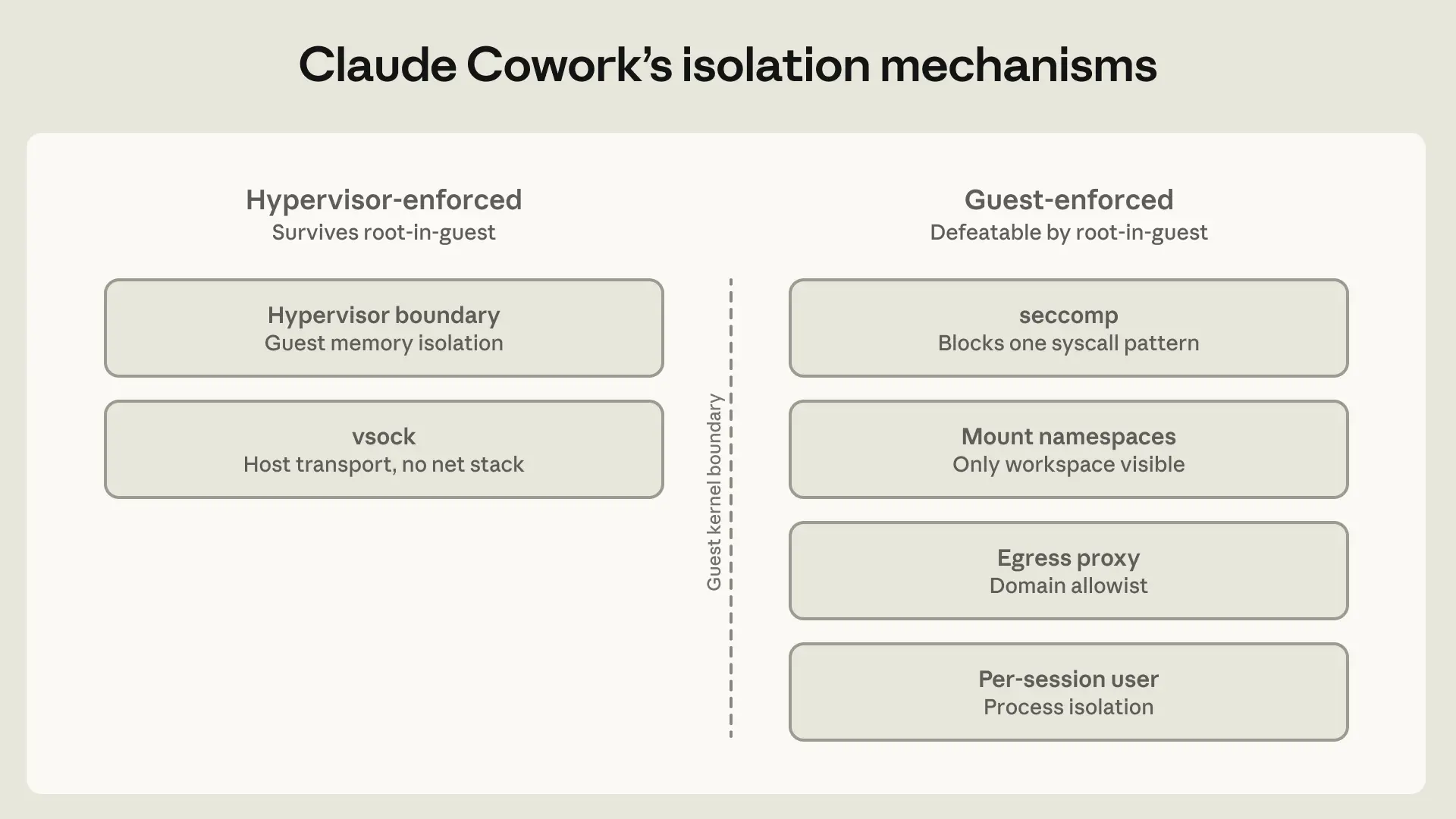
对于安全要求最高的企业协作场景Claude Cowork,Anthropic采用了虚拟机级别的隔离方案。使用苹果的Virtualization框架在macOS上实现,或在Windows上使用HCS(Hypervisor Code Segmentation),将Claude与宿主机系统完全隔离开来。这种方案的安全性最高,但也意味着与宿主系统的集成能力最弱。VM层面的隔离意味着安全工具无法看到VM内部的活动,这在某些场景下反而成为了新的盲点。
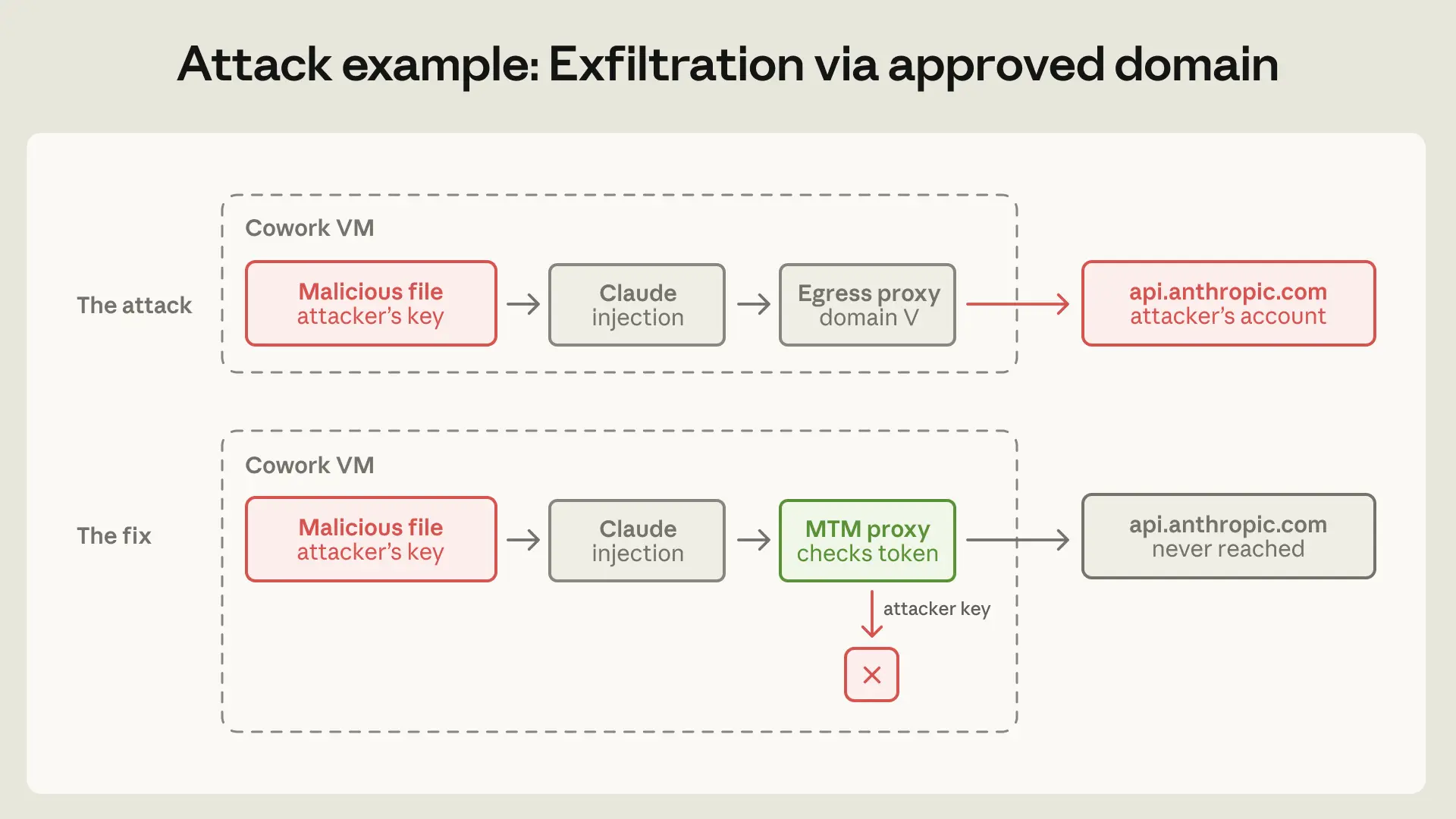
文章还披露了Anthropic在实践中发现的几起值得关注的安全事件。其中最引人注目的是通过钓鱼攻击实现的直接提示词注入——在24次测试中有25次成功窃取信息,成功率高达96%。此外还有通过预授权钩子在用户确认信任对话框之前就执行代码、通过攻击者控制的API密钥从已批准域名 egress数据等问题。这些发现帮助Anthropic不断迭代他们的安全架构。
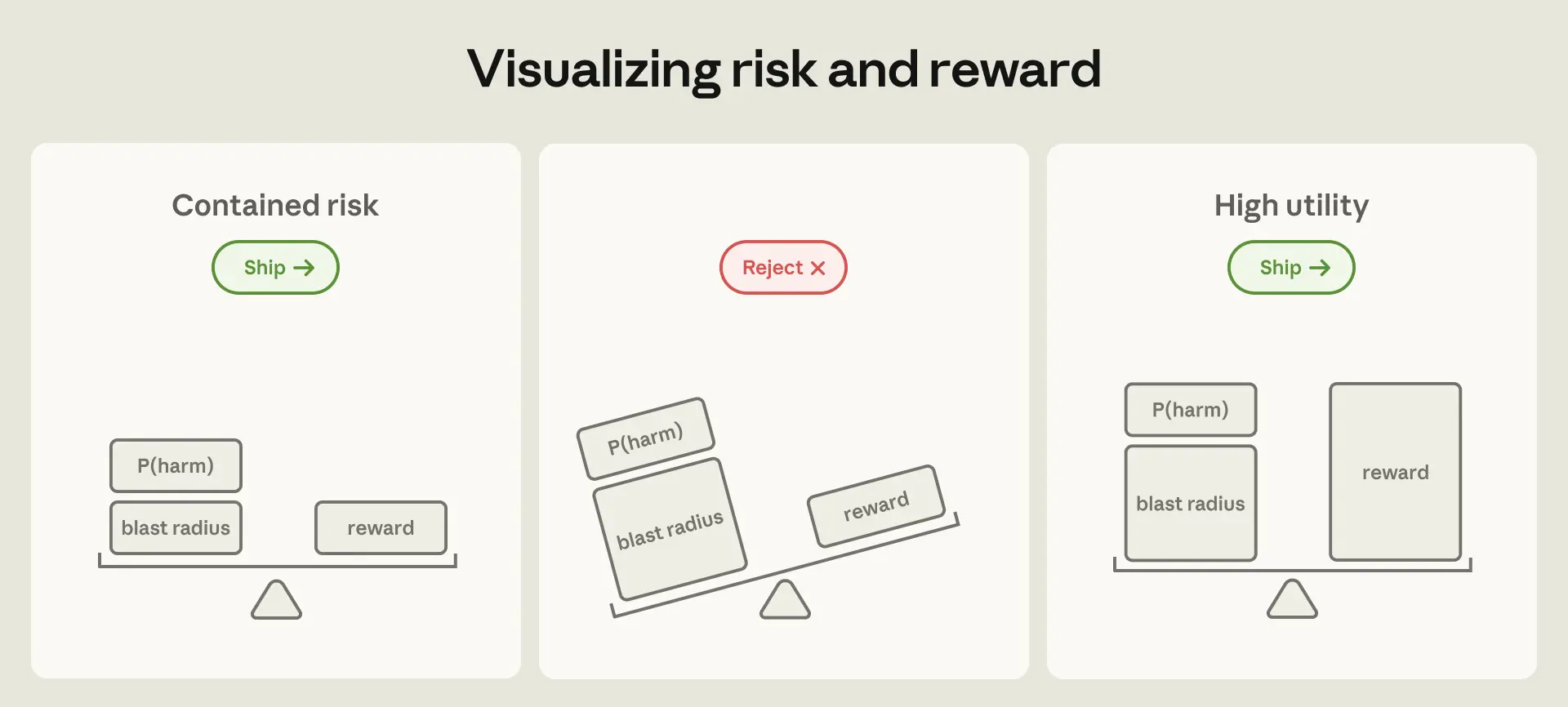
Anthropic在文章中总结了三条关键原则。首先是"环境层隔离优先,模型层引导其次",这意味着在设计系统时,应该首先依靠技术手段限制AI的能力边界,而不是完全依赖模型自身的"听话"程度。其次是"隔离强度要与用户监督能力相匹配"——不同用户群体需要不同级别的隔离,企业用户可能需要更严格的控制,而高级用户可能需要更多灵活性。第三条原则是"警惕自定义组件",Anthropic发现标准的隔离原语(如虚拟机管理程序、系统调用过滤器)比他们自己开发的安全Agent表现更好,这个发现对整个行业都具有警示意义。
参考来源:https://www.anthropic.com/engineering/how-we-contain-claude
