微软工程师在实践中发现了一个困扰许多团队的问题:AI Agent的质量改进陷入了"测量容易修复难"的困境。当团队能够追踪和评估Agent的表现时,却发现即使知道问题所在,也很难在不引入回归的情况下完成修复。针对这个挑战,微软Vivek Bhaduria、Luis Quintanilla和Saket Sathe组成的团队提出了一个新的解决思路——将Agent质量改进重新定义为一个搜索问题,而非传统意义上的调试。
这个解决方案被称为"Agent优化循环",包含四个核心步骤。第一步是生成候选修改方案,团队使用一个专门的"反思者"模型来分析失败的追踪记录,并提出有针对性的修改建议。第二步是对所有候选方案进行评分和排序,确保它们在同一个评估标准和基线版本上进行对比。第三步是开发者审核,这是一个必要的人工把关环节,确保自动生成的修改方案在进入生产环境前经过人类确认。第四步是部署获胜方案,由于采用了版本化管理,任何修改都可以回滚。
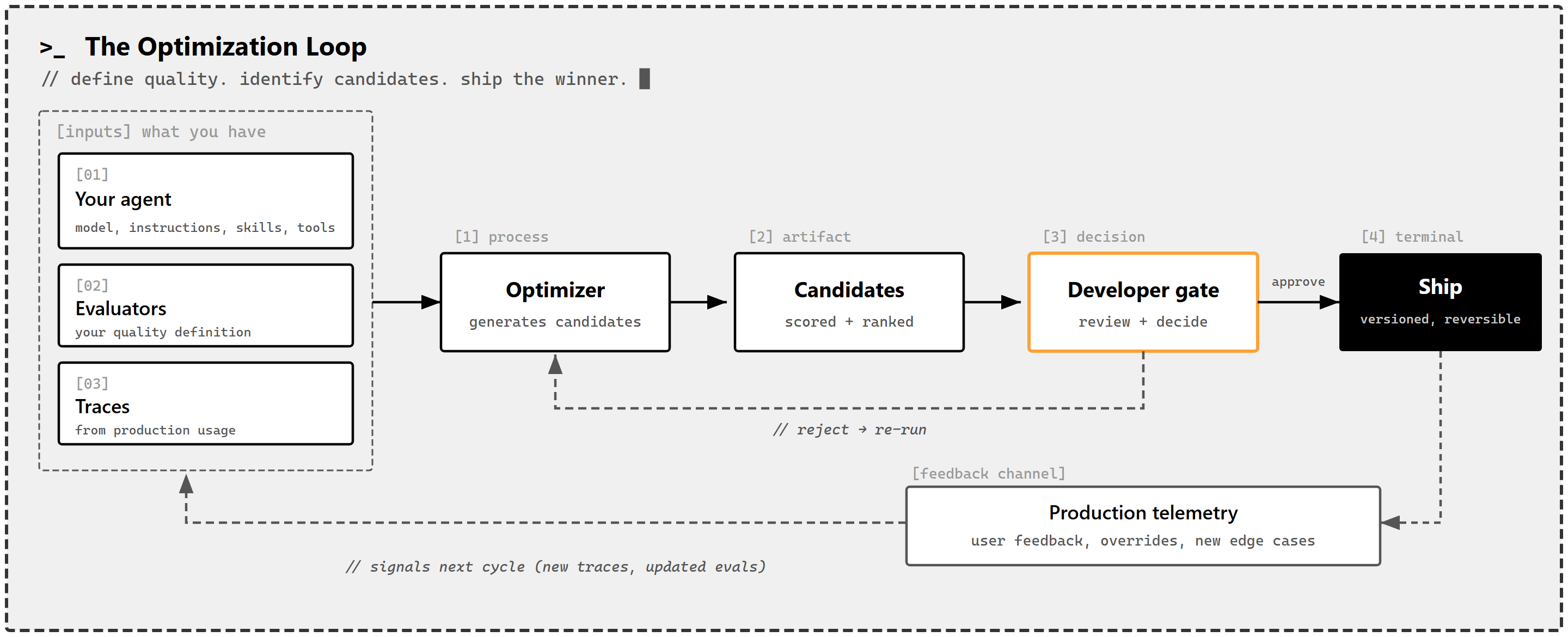
这个系统的核心理念在于反思模型的质量比执行Agent的模型本身影响更大。团队在实践中发现,一个更好的诊断模型所带来的产出质量提升,远远超过提升执行模型本身。这引出了一个重要原则:更好的诊断胜过更好的执行。这个洞察直接影响了整个系统的设计思路——与其在执行端堆砌更强大的模型,不如在诊断端投入更多资源。
从工程实现角度看,这套系统已经被打包成Microsoft Foundry Agent Service中的Agent Optimizer功能,通过azd CLI对外提供。开发者可以使用azd ai agent eval init初始化评估流程,用azd ai agent eval run运行测试,用azd ai agent optimize启动优化,用azd ai agent optimize apply --candidate <id>应用候选修改,最后用azd deploy完成部署。整个流程与传统的CI/CD pipeline高度一致,团队可以像管理代码版本一样管理Agent配置。
不过这个工具也有明确的适用边界。它最适合处理跨领域的质量问题、大规模运营中的系统性配置失败(包括指令、技能、工具和模型的配置问题),而不是早期开发阶段、基础设施问题、单点失败模式,或者需要通过升级模型来解决的任务。团队也特别强调了"自动化without oversight会放大错误"这一警示——人工审核环节是不可或缺的。
参考来源:https://commandline.microsoft.com/the-agent-optimization-loop-and-how-we-built-it-in-foundry/
