一
四月初的某个晚上,Andrej Karpathy 在 GitHub Gists 上发了一份文档。
没有发布会。没有官网。没有 Twitter 推广。他只是把它传上去,标题写了两个字:LLM Wiki。
四十八小时之内,转推过万。一个礼拜之内,GitHub 上多出了至少 9 个项目,名字全都叫 llm-wiki 或者 llmwiki,每一个都在抢着实现他描述的那个东西。
OpenAI 联合创始人、前特斯拉 AI 主管、nanoGPT 和 llm.c 的作者,在 2026 年说了一句话——整个 AI 圈集体停下来,重新想了一个问题。
二、他到底说了什么
Karpathy 那份 Gist 只有几百行字。核心论点用一句话能说完:
你给 AI 喂的资料,不应该是查询的时候才被翻一遍的向量碎片。AI 应该在你扔进去的那一刻,读完它、理解它、写成一本结构化的、有内部链接的、活的 wiki——以后所有问题,从这本「写出来的书」里答,而不是再从一堆 PDF 里现找。
听起来像是常识。但它戳破了 RAG 范式两年来最大的盲点——
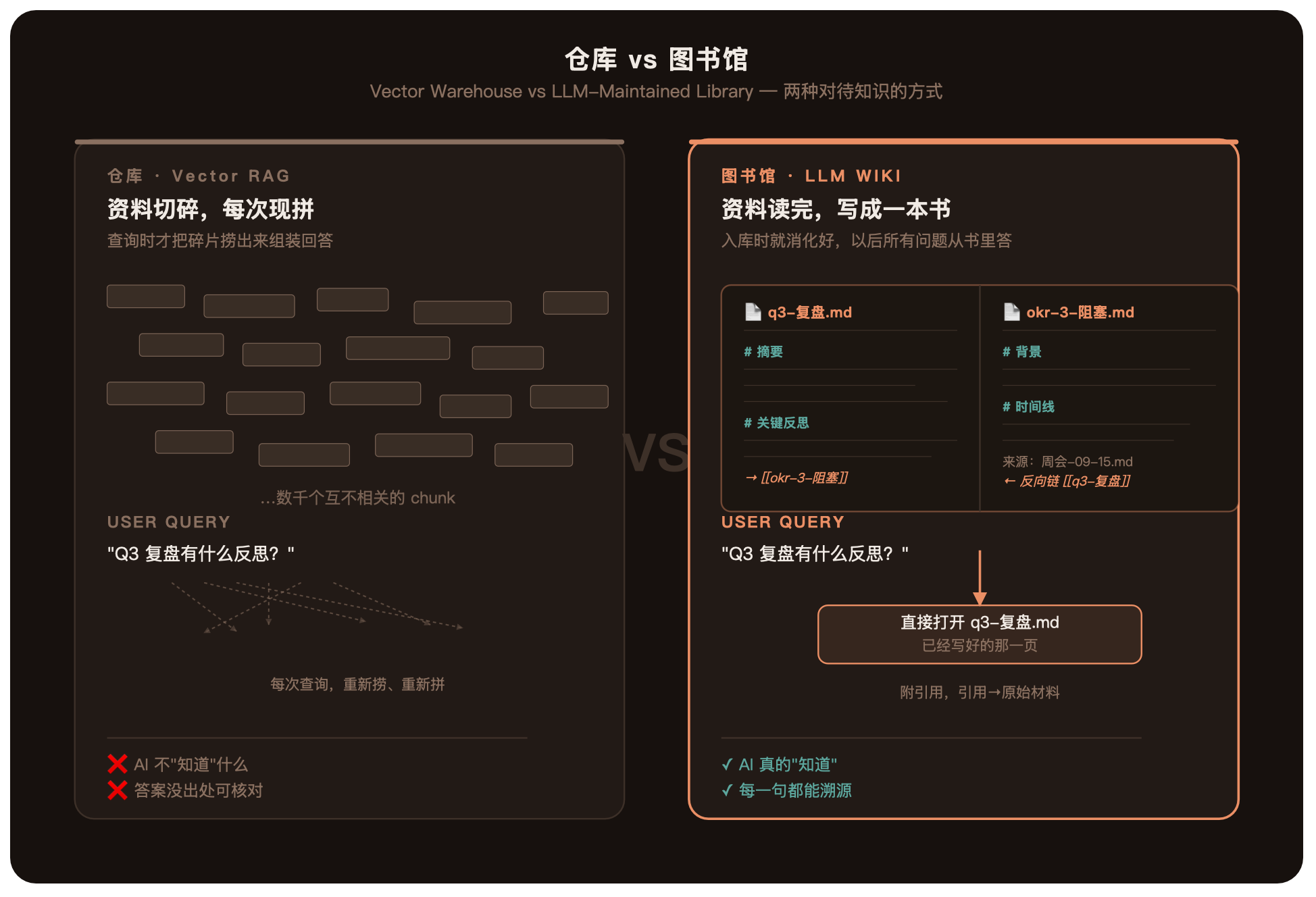
我们一直在让 AI 当「仓库管理员」——你来一个问题,它跑进仓库捞几个箱子,拼一段答案给你。下一次同一个问题,它再跑一遍。它从来没有真的「读懂」过你的资料。
Karpathy 说的是另一种 AI——「图书管理员」。它一次性读完所有书,写好分类目录,建好索引,链好相关条目。下次有人问问题,它直接走到对应的那一页,把答案给你,附引用。
这是一个简单到让人不好意思没早想到的反转。
三、然后世界开始抄
四月中旬的 GitHub 趋势榜上,挤满了 LLM Wiki 的实现。
每一个都是一两百行 Python 或者 TypeScript 脚本。每一个都跑得动。每一个都做对了 Karpathy 说的那件事——
喂资料 → AI 读完 → 写出 wiki
到这一步为止,他们做得都不错。
但是然后呢?
然后那本书就静静地躺在你硬盘的某个目录里。等你下一次想起它。等你下一次手动打开它。等你下一次手动让 AI 去读它。
这不是 Karpathy 那条 Gist 想讲的故事。那是只完成了一半的故事。
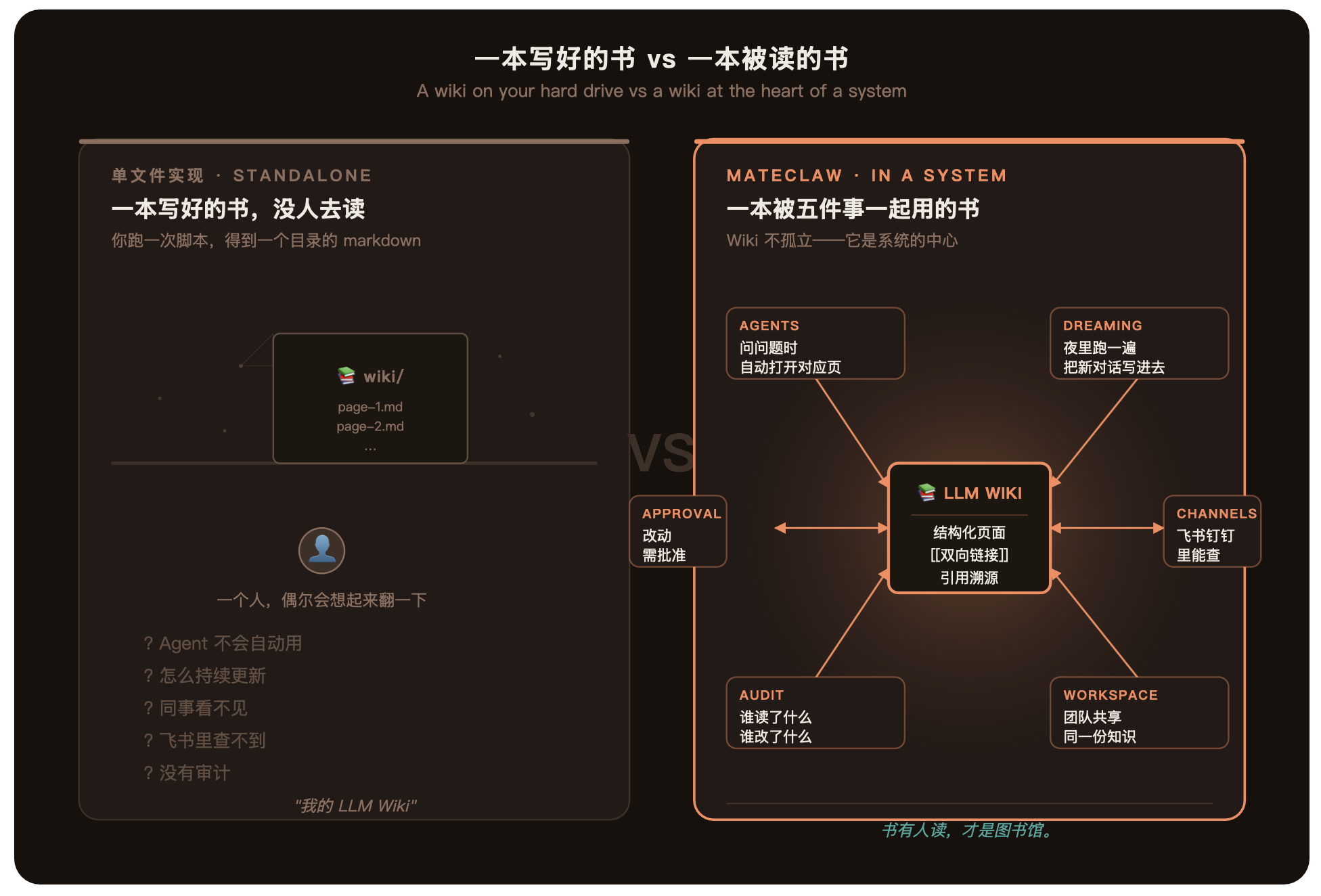
四、一本没人读的书,不是图书馆
世界上最伟大的图书馆,不是因为它有最多的书。是因为它的书被读、被引用、被借走、被还回来、被讨论、被更新。
一本写得再好的 wiki,如果没人去读它,它就不是一本书——它是一份昂贵的草稿。
那 9 个 LLM Wiki 实现,全部停在「写出来」那一步。它们没有回答下面五个问题:
-
Agent 怎么自动用这本 wiki?——你问问题的时候,它怎么知道该翻哪一页?
-
wiki 怎么持续更新?——你又录了一场会、又发了一封邮件,wiki 怎么把这些写进去?
-
团队怎么共享?——这本 wiki 在你电脑上。你同事看不见。
-
从你工作的地方怎么访问?——你的工作 80% 在飞书 / 钉钉 / Slack 里。wiki 不在那里。
-
谁能改?谁改了什么?——一本被多人维护的 wiki,没有审计,是定时炸弹。
这五件事,是 LLM Wiki 从「概念」走到「真能用」必须跨过的桥。
那 9 个实现都没建这座桥。
五、我们建好了
我们叫它 MateClaw。在 Karpathy 那个 Gist 出来之前,我们已经把这个事情想完,做完,上线了。
不是因为我们比 Karpathy 聪明。是因为我们从一个不同的方向走到了同一个结论——
我们不是在做「一个会写 wiki 的脚本」。我们在做一个完整的 AI 操作系统。当我们设计「AI 怎么用知识」这一层的时候,从第一天起就清楚:写出 wiki 只是开始,把它装进系统才是关键。
所以在 MateClaw 里,LLM Wiki 长这样——
1. Agent 自动打开对应的页。
你问「Q3 销售复盘的反思」,Agent 不去做向量检索拼答案。它直接打开两个月前自己写好的那一页 wiki,从那一页的结论给你。回答附引用,引用点进去是当时的会议纪要原文。
2. Wiki 在你睡觉的时候被更新。
每天晚上,MateClaw 跑一个叫 Dreaming 的调度任务——它把当天所有新对话过一遍,把和现有 wiki 页面相关的新内容自动 merge 进去。第二天早上,wiki 比昨晚更新、更准、更全。
3. Wiki 在你的飞书里能查。
你在飞书群里 @ 一下 Agent,问「我们公司怎么做绩效复盘」——Agent 回答的不是它训练数据里的通用答案,是它自己写的那一页《绩效复盘流程》wiki,是这个团队两年里沉淀的真实做法。
4. 整个团队共享同一本 wiki。
不是 Alice 一本、Bob 一本。是一个工作空间,三十个人,一本 wiki,三十个人的对话都在更新它。新人入职第一天打开飞书问 AI,得到的就是这家公司的真实知识。
5. 每一次改动都进审计。
Agent 想改 wiki 里关键页的结论?停下来,发审批通知到主负责人手机上,等批准。mate_tool_guard_audit_log 表里记下来:谁、什么时候、改了哪一行、有没有人批准。
六、一个具体的周一
九点零五分,老板在飞书群里发了一句话:
「@小贺,准备一下今天下午 sales review 的材料。重点:Q3 复盘里我们说要解决的那三个阻塞,进展怎么样了。」
你正在地铁上。你打开飞书,没有去翻 Q3 的 50 多个文档。你只发了一句话:
「@MateClaw 帮我准备」
12 秒之后,群里多了一条 Agent 的回复——
✓ 三个阻塞的当前状态:
1. OKR-3 数据接口跨部门权限
状态:✅ 已解决(10/15 上线)
当时记录:[[okr-3-阻塞]]
解决方案落地证据:[[2025-10-15-发布记录]]
2. 销售线索追踪准确性
状态:⚠️ 部分解决(CTR 提升 18%,但归因仍有 ~12% 缺口)
当时记录:[[lead-attribution-gap]]
后续工作:[[Q4-attribution-fix-plan]]
3. 客户成功团队人手缺口
状态:❌ 未解决
当时记录:[[cs-team-staffing]]
阻塞原因:[[hr-headcount-freeze-2025-Q4]]
📎 我已经把这三条整理成一份 PPT 草稿,5 张片:[查看]
每一个 [[...]] 都是 Agent 自己两个月前写的 wiki 页面。每一条状态都附引用。整份 PPT 在它打字的同时已经写好了。
你下了地铁,打开 PPT,调了两处措辞。下午两点,sales review 开始。
整个过程,你没打开过 MateClaw 的网页。
七、所以我们在感谢 Karpathy
Karpathy 没有发明 LLM Wiki。这个想法在 RAG 圈里隐约存在了一年多——「能不能让 AI 提前消化资料,而不是每次现拼?」很多人模糊地想过。
Karpathy 做的事是:他给了它一个名字。
一个名字让一千个工程师在同一个礼拜停下来,思考同一个问题。一个名字让原本散落在论文里、会议讨论里、Twitter 线程里的隐约直觉,凝成了一个可以被实现、可以被讨论、可以被超越的具体形状。
这是名人最有价值的贡献——他用他的名字,把一个常识变成了一个共识。
我们不是在反对 Karpathy。我们是在感谢他。因为他的 Gist 帮我们解释清楚了我们已经在做的事是什么——
Karpathy 给了世界一个名字。Gist 是名字的容器。我们给了这个名字一个家——一个会用它的系统。
八、什么时候你需要这种东西
不需要的时候:
-
你只是想给自己的 obsidian 笔记加个 AI 助手——拿那 9 个开源实现里任何一个,跑跑就行
-
你的资料只有十几个文件,记忆和检索都不是问题——继续用 ChatGPT
-
你只有一个人用,没有团队、没有合规、没有跨设备——别折腾系统级的东西
需要的时候:
-
你的公司有几年累积的会议纪要、PRD、复盘、客户记录——它们在 Notion 里、在 Confluence 里、在飞书云盘里、在某个共享盘里——而你想让 AI 真的「知道」这些东西
-
你的团队 5-50 人,每个人和 AI 各自零散对话,沉淀不下来集体记忆
-
你的工作真正发生在飞书 / 钉钉 / 企业微信 / Slack 里,AI 必须出现在那里
-
你的法务说「数据不能出去」,你的 IT 说「这个东西必须可审计」
MateClaw 就是为这种场景做的。
九、v1.1.137 · 今天发布
我们今天发布的版本,不只是 LLM Wiki。
LLM Wiki 是它的知识层。它还有:
-
多智能体编排(拆解任务、相互委派、动态重规划)
-
Dreaming 记忆生命周期(每晚把对话整合成对你的理解)
-
多渠道触达(同一个大脑出现在 8 个聊天软件)
-
主动型 cron + IM 推送(AI 自己找上你,不是你找 AI)
-
Tool Guard + 审批流(敏感操作问你一句)
-
14+ 模型供应商热切换(OpenAI 挂了你的用户没看到一秒)
但是只有一件事重要:这一切,跑在你自己的机器上。一个 JAR 包。数据不出门。Apache 2.0。
十
一份写好的 wiki 躺在硬盘里,是一份草稿。
一份被读的 wiki 躺在系统里,才是图书馆。
MateClaw v1.1.137 · 今天发布
Apache 2.0 开源 · 跑在你自己的机器上 · 60 秒上手
github.com/matevip/mateclaw · gitee.com/mateos/mateclaw