小米大模型宣布正式发布 MiMo-V2.5-TTS Series 与 MiMo-V2.5-ASR —— 一套面向 Agent 时代的全链路语音模型系列,覆盖识别与合成两大核心能力,让语音的输入与输出都可以被语言自由调度。
-
MiMo-V2.5-TTS Series 包含三款模型,现已登陆小米 MiMo 开放平台,并且限时免费。三者共享统一的风格指令遵循、音频标签控制与文本理解能力,让声音表现可以被语言精细调度,分别覆盖三种典型创作需求:
-
MiMo-V2.5-TTS:内置多款高质量精品音色,支持语速、情绪、语气等精细化控制,开箱即用,满足多场景表达。
-
MiMo-V2.5-TTS-VoiceDesign:一句话快速定义并生成全新音色,让音色创作更直观、更高效。
-
MiMo-V2.5-TTS-VoiceClone:少量样本高保真复刻目标音色,同时保持稳定的风格指令遵循与音频标签控制能力。
-
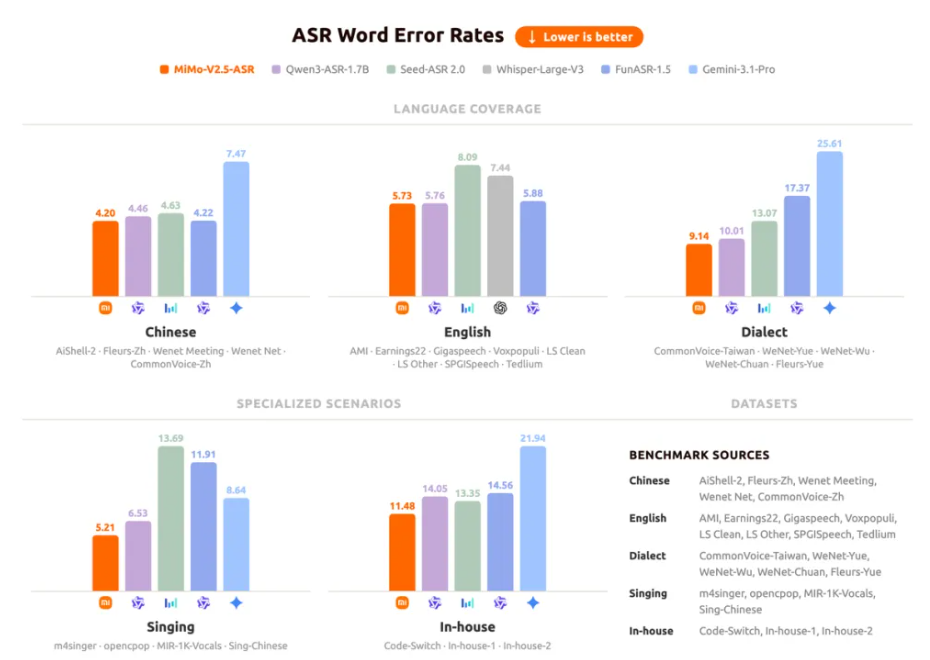
MiMo-V2.5-ASR 正式开源。模型在中英双语、中文方言、Code-Switch、强噪音、多说话人等复杂真实场景下的语音识别性能达到业界领先水平,为 Agent 提供清晰可靠的语音转写,确保每一次交互都建立在精准的理解之上。
MiMo-V2.5-ASR 作为全链路语音模型系列的听觉基座,在中英双语、中文方言、Code-Switch、强噪音、多说话人、高知识密度等复杂真实场景下均达到业界领先水平。它不只是为了把清晰的语音转成文字,更是让 Agent 在嘈杂的真实声音里,抓住每一个值得被理解的字词。
核心特点
- 中文方言:支持吴语、粤语、闽南语、四川话等方言
- 英文复杂场景:在 AMI 等复杂英文场景 Open ASR Leaderboard 上达到领先水平
- Code-Switch:中英 Code-Switch 语音转录自由流畅,无需预设语种标签
- 歌曲识别:中英文歌曲歌词识别,在伴奏与人声混合场景下保持高精度
- 强噪音场景:在高噪音、远场拾音等复杂声学环境中保持鲁棒识别
- 多说话人:支持多人交叉对话场景的准确转录,如会议场景
- 强知识关联:古诗词、专业术语、人名、地名等知识密集型内容的精准识别
- 原生标点:结合语音韵律与语义原生输出标点,转写结果即拿即用,无需后处理