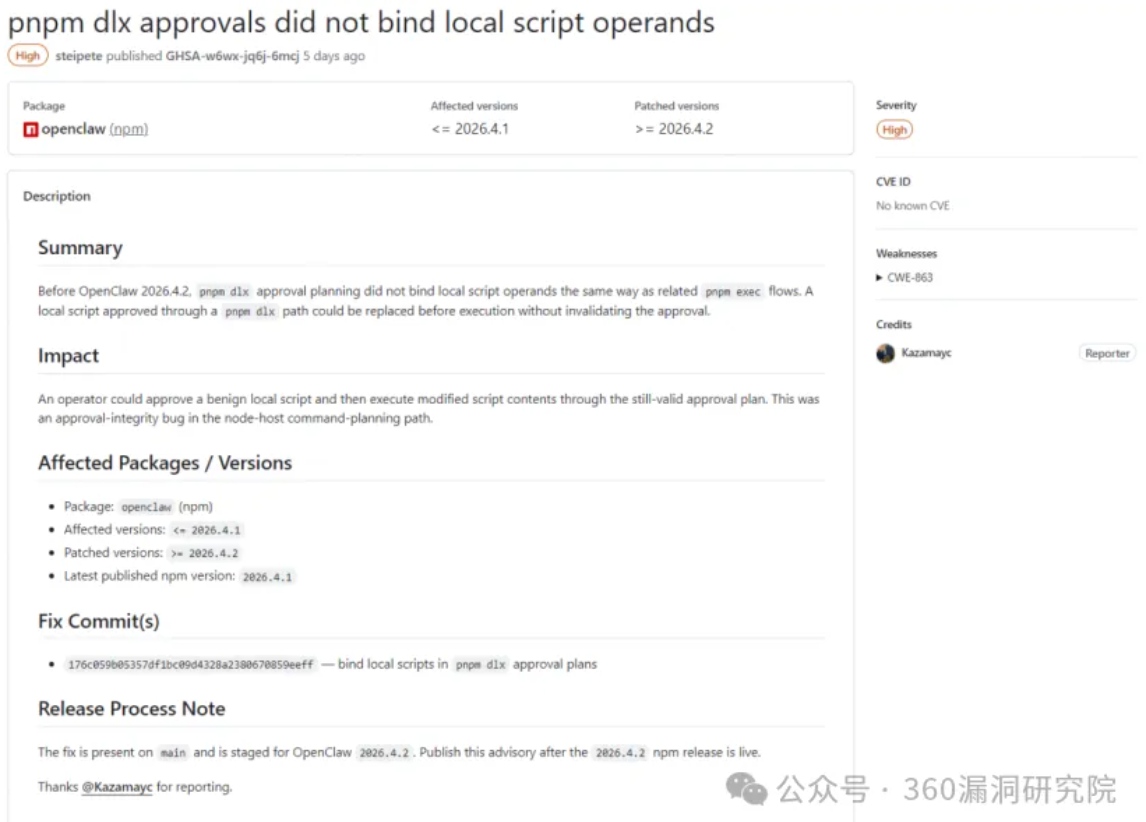
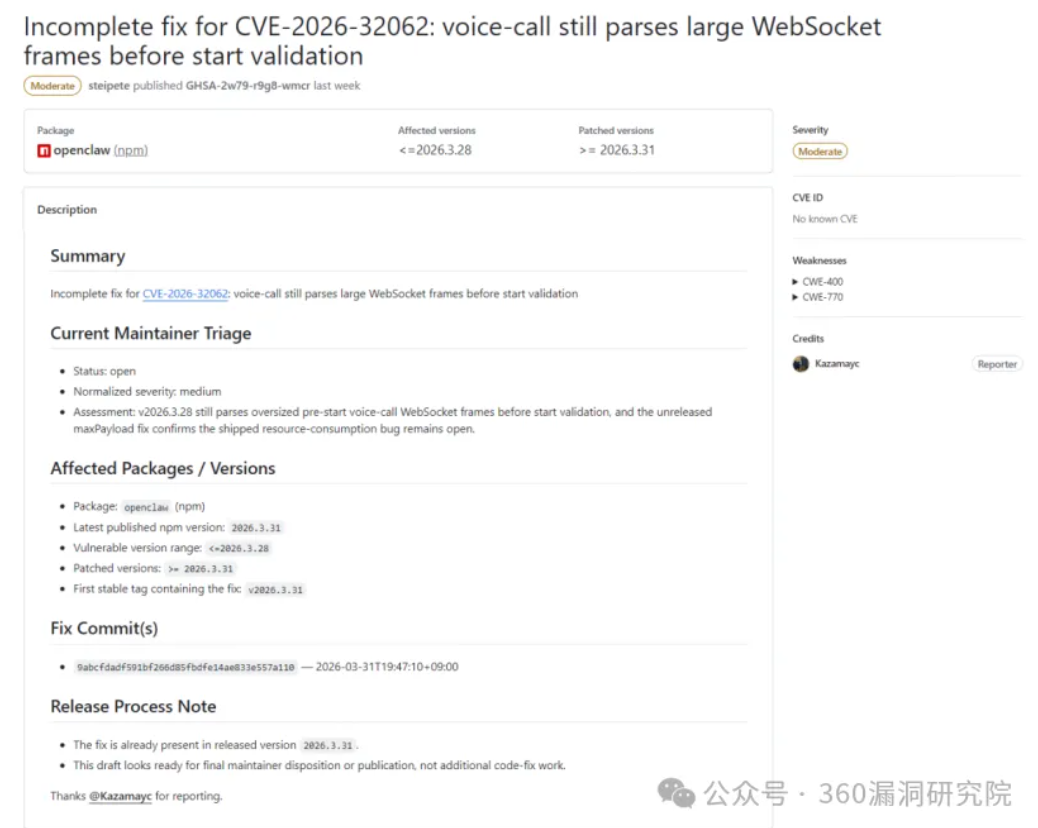
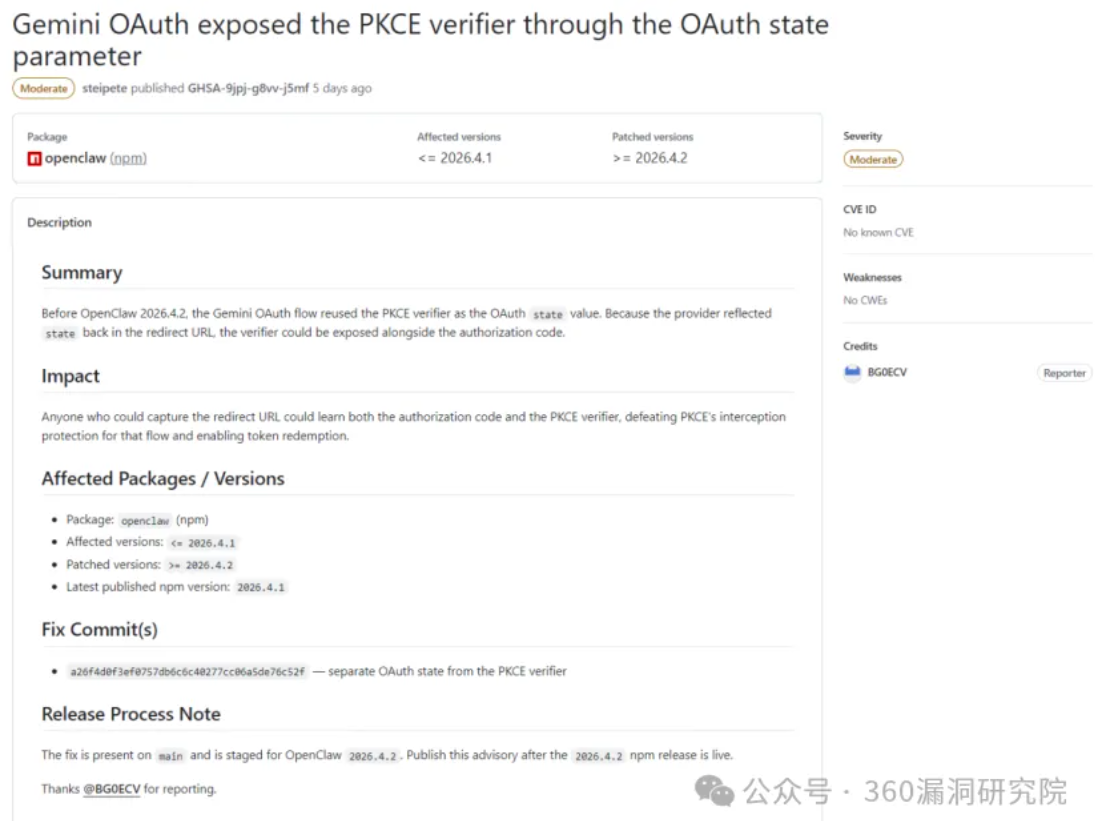

Claude Code 出 BUG 狂吞 token!赶紧试试谷歌新模型 Gemma 4 尝试替代
Claude Code 最近被曝出 BUG 导致 token 消耗膨胀 10-20 倍,正好 3 月 31 日 Google 新发布了 Gemma 4,赶紧本地部署试试能不能替代 —— 结果踩了一路的坑。 测试环境 硬件:Mac Studio M4 Max / 128GB 统一内存 / 16 核 CPU / 40 核 GPU 模型:google/gemma-4-26b-a4b(Q4_K_M 量化,17.99 GB) 推理框架:LM Studio 0.4.9(Metal 加速,GPU 卸载 30/30 层满载) 2026 年 3 月 31 日,Google 发布了 Gemma 4 系列,包含 E2B、E4B、31B 和 26B A4B 四个版本。其中 26B A4B 采用 MoE(混合专家)架构,26B 总参数中每次推理只激活约 4B,理论上兼顾了性能和速度,是本地部署的热门选择。 速度实测:令人失望 场景 生成速度 Prompt 处理 体验 短对话(< 2K token) ~30-40 tok/s 1-2 秒 ✅ 流畅 中等对话(~8K token) ~20-30 tok/s 5...