腾讯和清华大学人机语音交互实验室联合研发的音乐基础模型 SongGeneration 2 已正式推出。公告称,其核心优越性在于对底层架构和训练策略的全面升级,赋予了 SongGeneration 2 突破性的三大优势:
- 高音乐性:不仅旋律优美连贯,更能处理复杂的多轨编曲与空间层次。
- 高歌词准确性:大幅降低幻觉,实现清晰、准确的多语种咬字跟唱。
- 优秀的可控能力:精准遵循文本描述、音频提示等多种指令,深度控制音乐风格。
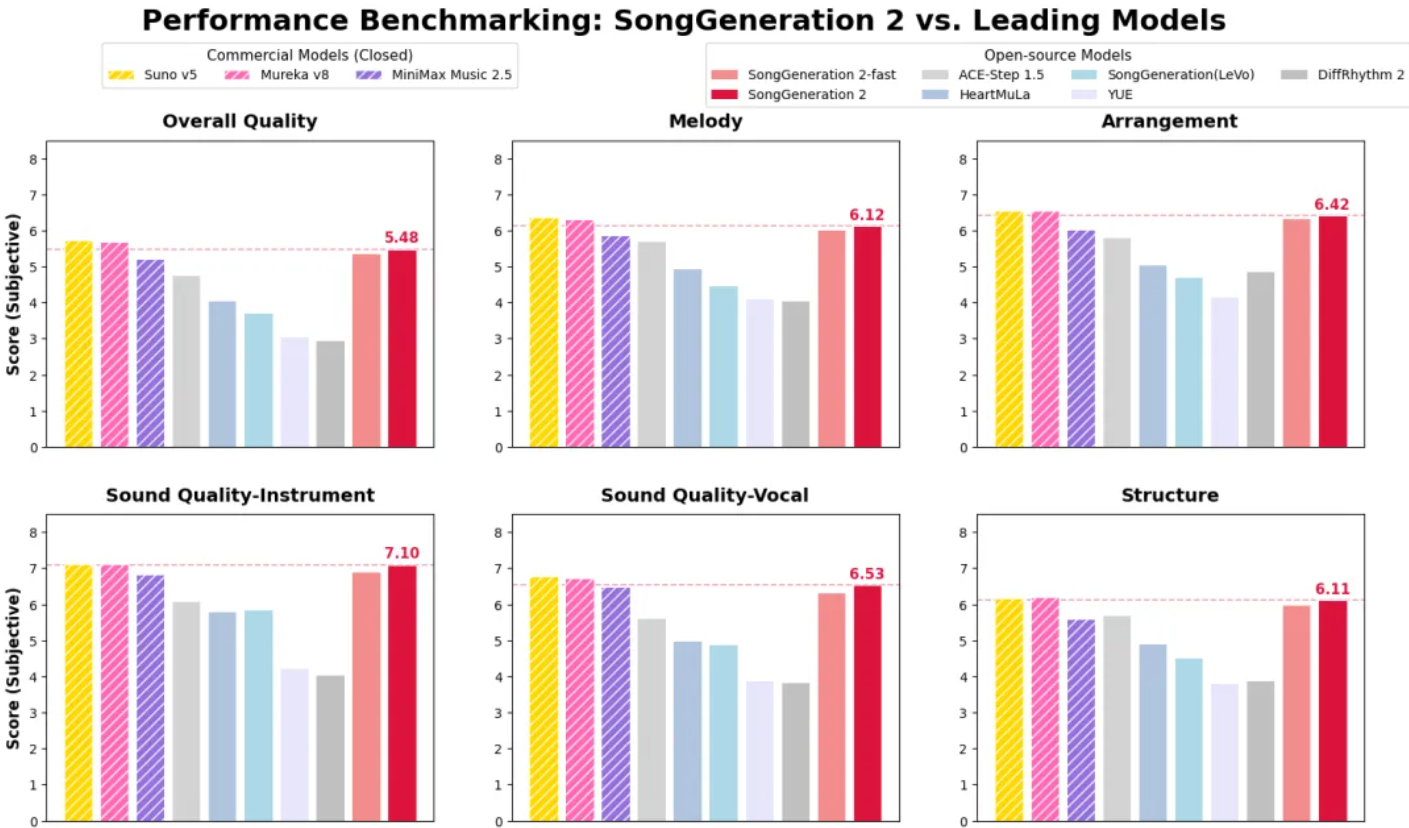
评估结果表明,在整体质量(Overall Quality)、旋律(Melody)、编曲 (Arrangement)、乐器音质(Sound Quality-Instrument)、人声音质(Sound Quality-Vocal) 以及结构(Structure) 这6 个评价维度中,SongGeneration 2 均呈现出断崖式领先,显著超越了包括 ACE-Step 1.5、HeartMula、YUE、LeVo以及DiffRhythm 2在内的所有主流开源模型。
实验数据显示,SongGeneration 2 的整体生成质量已成功对齐商业级能力。在整体质量、旋律、编曲等多个维度上,SongGeneration 2 的表现甚至超过了MiniMax 2.5。
除了质量与旋律的提升,评估还证明了模型具有出色的歌词遵循能力。SongGeneration 2的音素错误率(PER)仅为8.55%,仅次于MiniMax 2.5 (7.8%),显著优于顶尖商业模型Suno v5 (12.4%)和 Mureka v8 (9.96%),并在曲风、情绪、乐器三大维度的控制上逼近了商业顶级水平。
![]()
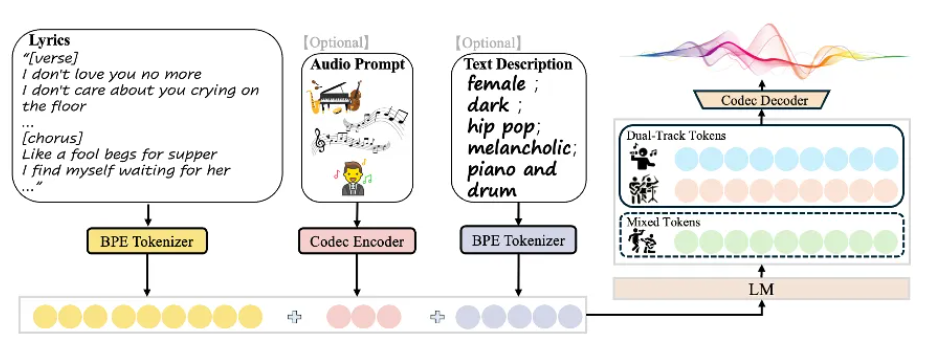
SongGeneration 2 基于混合式 LLM-扩散架构:
![]()
- “双核”分工协作:语言模型(LeLM)作为“作曲大脑”,负责统筹全局的音乐结构与演奏细节(解决如何演唱与演奏的问题);而扩散模型(Diffusion)则担任“高保真渲染器”,在语言模型的隐式指导下,合成极其复杂的声学细节 。
- 首创分层表征结构:为了兼顾音乐性、稳定性与音质,语言模型采用了并行建模的设计 :
- 混合表征(Mixed Tokens):用于指导模型捕捉高层级的旋律、结构等核心语义信息 。
- 多轨表征(Dual-Track Tokens):分别代表人声和伴奏轨道,在语义信息的基础上进一步确定不同轨道局部的细粒度声学变化。
目前,包含4B参数的SongGeneration-v2-large模型已正式开源 。它支持中英文等多语种生成,并通过文本描述、音频提示和风格预设提供多样化的控制方式。该模型可在配备22GB显存的消费级硬件上本地流畅运行,实现约0.82的RTF。
为了实现即时体验,项目团队同步在HuggingFace Space平台提供SongGeneration-v2-Fast版本,该版本牺牲了一定的音质但换来了较快的生成速度 (可以在一分钟内生成一首完整歌曲)。
接下来其还将推出支持12G显存、RTF约为0.69的Medium 模型,并逐步开源自动化评估框架等核心组件。