欢迎来到天工造物开源社区!作为具身智能领域的协作枢纽,我们致力于开源开放核心技术,与全球开发者并肩同行,用代码加速通用智能的落地。
面对每天爆发式增长的具身智能 arXiv 论文和行业动态,如何才能不掉队?为了帮你打破信息茧房、过滤无效噪音,我们特别推出全新专栏活动 ------「具身智能半月谈」。每天一期硬核技术文章,不仅深度拆解顶会上的明星论文,更会为你剖析最前沿的具身技术原理。和我们一起"啃"透前沿算法,每天几分钟,精准把握学术与产业的最新风向!
导读
在具身智能与机器人操作领域,如何让机器人学到的技能泛化到未见过、极具挑战的真实场景中一直是一大难题。传统的做法往往需要花费巨大人力物力去收集海量数据,或者依赖极为完美的上游图像识别系统。
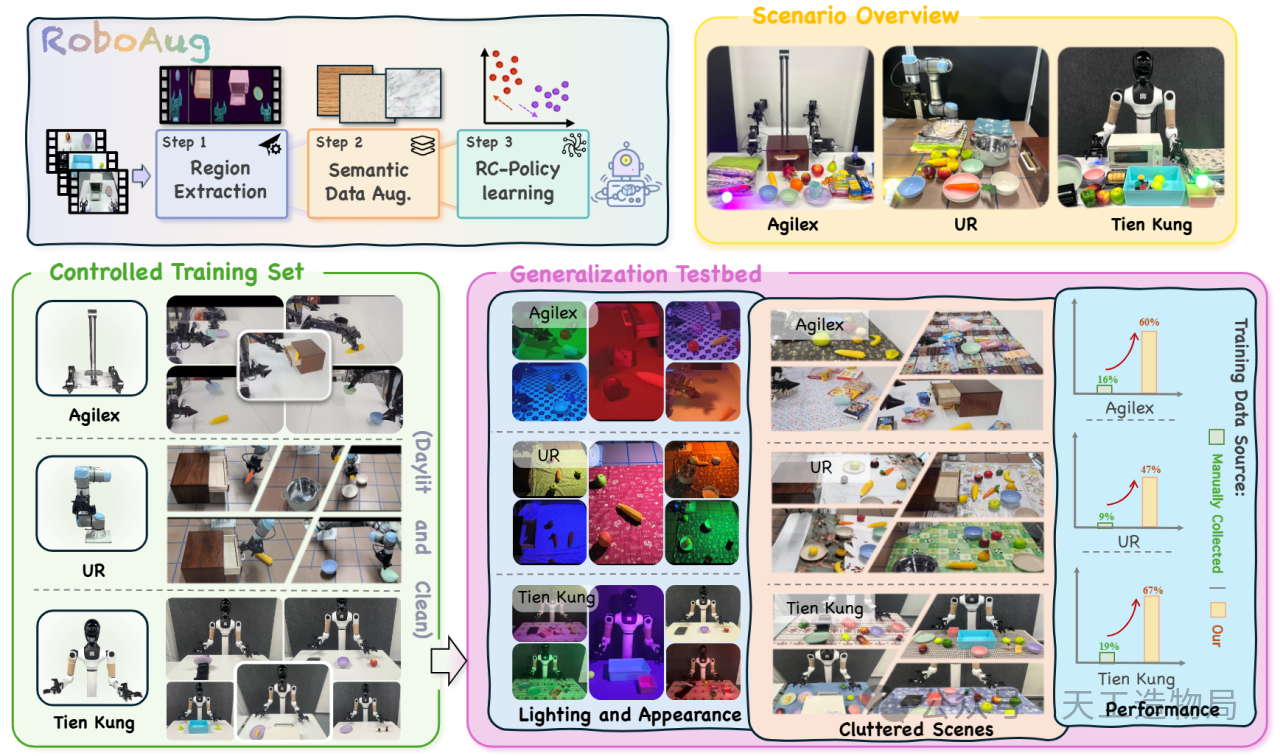
近日,由北京人形机器人创新中心联合慕尼黑工业大学、北京大学、北京航空航天大学等顶尖机构的研究团队,提出了一种全新的区域对比数据增强框架------RoboAug。该框架打破了传统数据收集的瓶颈,仅需对单张图像进行简单的边界框标注,即可让机器人操作策略泛化到数百个未见过的全新场景!
![a6bbb0b22ec8e8987ffd7d94cc4397f3.png]()
领域瓶颈:面向分布外(ODD)环境的灾难性策略崩溃
长期以来,基于端到端模仿学习(End-to-End Imitation Learning)或视觉-语言-动作模型(VLA)训练的运动控制策略在独立、封闭环境内展现出优异的拟合能力。
然而,受限于有限的离线演示分布,策略很容易对局部视觉快捷特征(Visual Shortcuts)发生过拟合。一旦将其部署于结构或光照产生时变偏移(Distribution Shift)的新环境中(例如背景的域偏差、阴影和多重光源和高强度的外置视觉干扰物聚集),其动作推断的正确率(Zero-Shot Generalization)呈现出灾难性的坍塌失效。
为了克服协变量偏移的问题,工业界主流皆是依赖海量跨实施例(Cross-Embodiment)数据的堆积(如 Open X-Embodiment 等)。但这面临着难以逾越的数据采集和人工遥操作标注壁垒;而现有的基于图像增强技术的语义变换又高度依赖场景内完美的特征隔离和目标检测后处理能力,这使得系统在发生强遮挡或精巧交互的环境中几乎无法实际运行。
范式跃迁:RoboAug 的"化繁为简"与对比范式重塑
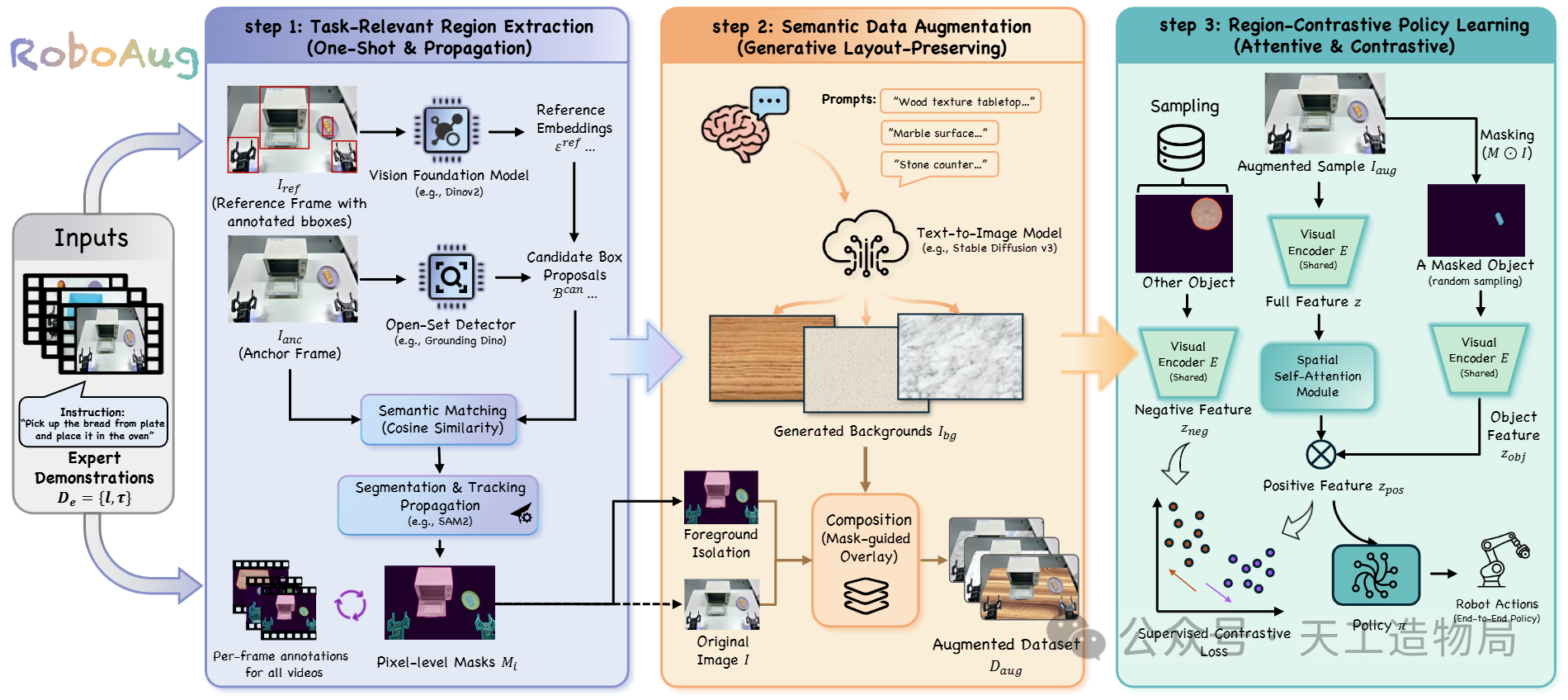
为彻底打破具身感知领域这一僵局,RoboAug 创新性地引入了生成式 AI 结合区域对比表征的端到端管线式框架。它以最精简的用户交互介入范式,利用下游自动化的区域提取技术构建具有高语义信息量且几何拓扑守恒的高保真扩增图集。
![758144eaa81b3e714a5de6275e509c5e.png]()
RoboAug 整个框架主要包含三个极具创新性的阶段:
1、零门槛的区域提取 (Task-Relevant Region Extraction)
传统方法往往依赖繁琐的逐帧标注或高昂的检测器重训练成本,而 RoboAug 提出了一种"免训练(training-free)"的单样本匹配与传播机制。研究人员只需在单张参考图像(Anchor Frame)提供边界框(Bounding Box),系统即调用视觉基础模型(如 GroundingDINO)生成候选框,并基于 DINOv2 提取的特征向量进行余弦相似度匹配,实现高精度的零样本目标重识别。
随后,引入时空一致的分割追踪范式(如 SAM2),将稀疏的包围盒先验转化为稠密的像素级掩码(Pixel-level Masks),并在整段演示轨迹的时间戳上实现自动化传播与对齐。
2、移花接木的语义数据增强 (Semantic Data Augmentation)
传统的基于图像修复(Inpainting)的语义增强方法在遮挡处理上往往会引入几何形变和严重的视觉掩模伪影(Visual Artifacts)。RoboAug 抛弃了该技术路线,而是利用大语言模型(如 ChatGPT)自动扩充了数百个背景描述提示词模板(包含木材质58%、石材质35%及合成材质7%等)。
通过引导 Text-to-Image 生成模型(如 Stable Diffusion)合成高分辨率、多样性的全景背景纹理。最终将预先提取的与任务相关的前景掩码以像素级精度无缝融合(Composite)到新生成的结构背景中,在实现数据规模指数级扩充的同时,零损耗地保护了核心操作对象的物理几何拓扑与位姿。
3、火眼金睛的区域对比策略学习 (Region-Contrastive Policy Learning)
为弥合数据增强与策略优化之间的语义鸿沟,RoboAug 创新性地引入了即插即用的区域对比损失(Region-Contrastive Loss, RCL)。在每次训练迭代中,一方面通过二进制掩码对原图像进行逐元素乘法(Element-wise Product)提取物体级特征(Object-centric Feature);另一方面利用全局特征向量,配合空间自注意力机制(Spatial Self-Attention)弱化掩码黑色遮挡区域引发的无效激活。
通过在同一类别的局部特征间构造正样本对,跨类别特征间构造负样本对,该框架显式地优化了视觉编码器的表征聚类空间。在不改变原始 Backbone 架构的前提下,实现了抑制视觉干扰、聚焦任务关键实体的本质能力提升。
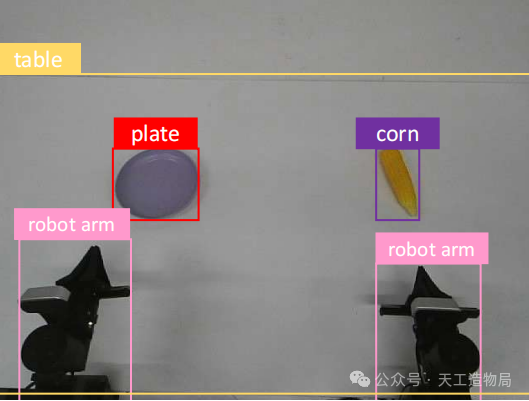
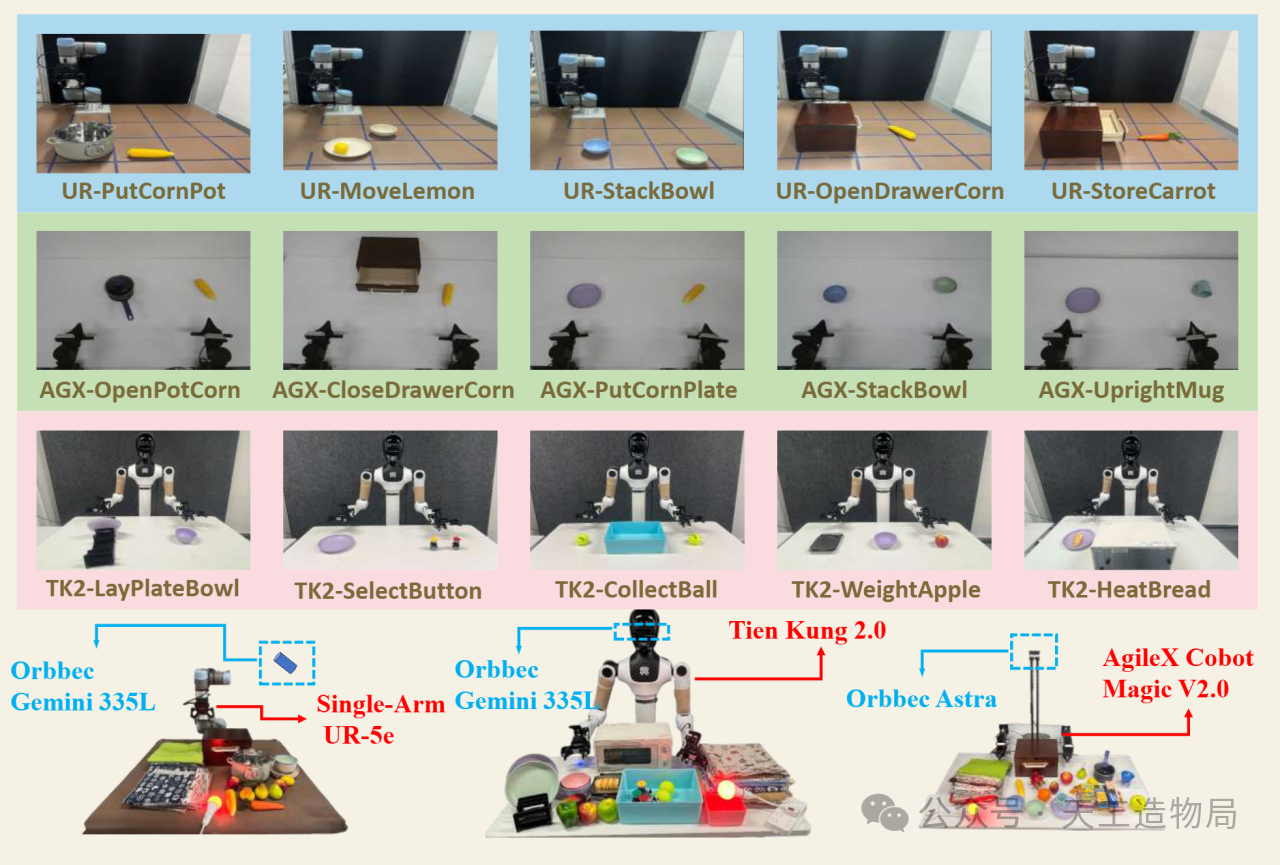
RoboAug-D:以机器人第一视角打造的大规模数据集
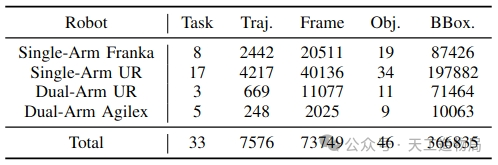
这是一个覆盖多种机器人物理平台(涵盖 Single-Arm Franka, Single-Arm/Dual-Arm UR 以及双臂全向底盘平台 AgileX)的第一视角大规模目标检测数据集,提供了极其精细的目标级监督信号:
- 33 种不同的跨平台操作任务(囊括单臂精细装配到双臂协同动作);依托多视角的连续时间序列,总计采集了 73,749 个有效高维观测帧;
- 覆盖 46 个具身场景物体类别,并提供了多达 366,835 个高质量 2D 边界框(Bounding Box)标注!
![c06248d9ea36ec80374d69df187b0e1f.png]()
![72cd297292bf204165876d855e8f2080.png]()
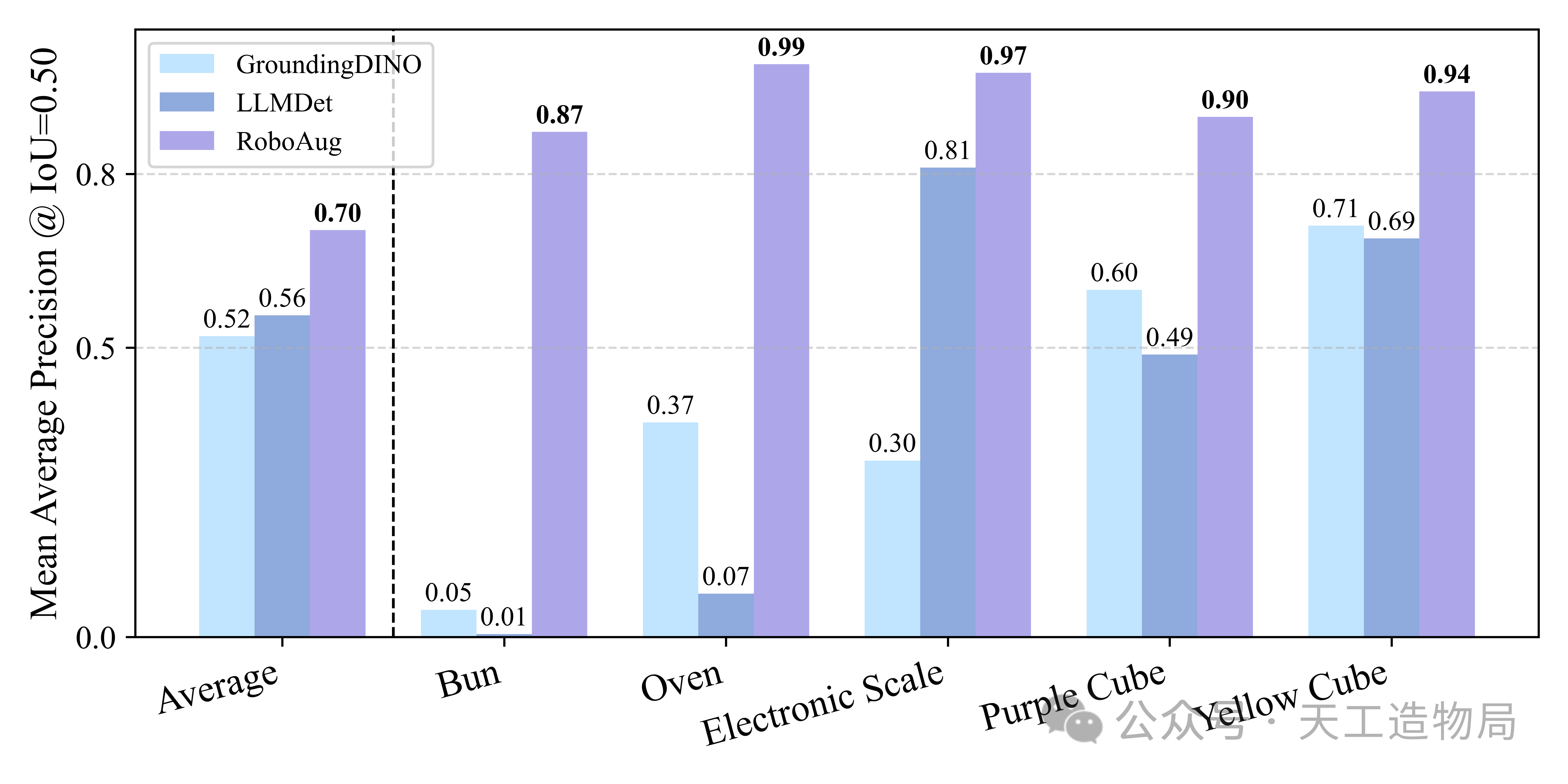
不仅如此,考虑到开源视觉基础模型(VFM)在具身智能特殊视角分布下的固有的端侧部署局限与精度盲区,研究团队还在 RoboAug-D 测试集上全方位评估了各领域最新大模型的零样本(Zero-Shot)定位性能。
通过采用 mAP@0.5 严谨的评价指标,横向对比了 GroundingDINO、LLMDet 等主流开箱即用的感知方案,深刻揭示了这些模型在应对夹爪遮挡、视角形变与动态交互过程中的失效机制,从而为未来用于 Robot-MIND 的闭环多模态大语言模型(VLA)与视觉感知组件提供了一套高规格的泛化能力 Benchmark 靶场。
![9f1e797601dfca277f5c959d77b7b90f.png]()
惊艳的表现:3.5万次真实测试,成功率飙升!
理论必须经过现实的检验,研究团队在三个不同的真实硬件平台上进行了规模宏大的部署实验:
- 单臂协作机器人 (UR-5e)
- 移动复合机器人 (AgileX Cobot Magic 2.0)
- 人形机器人 (天工 2.0 / Tien Kung 2.0)
实验覆盖了包括单臂抓放、抽屉开关、以及高难度的精细双臂协作等多种任务,累计执行了超过 35,000 次真实的物理交互评估!
![cda9fa86c5cc3f7db18a078e69b67810.png]()
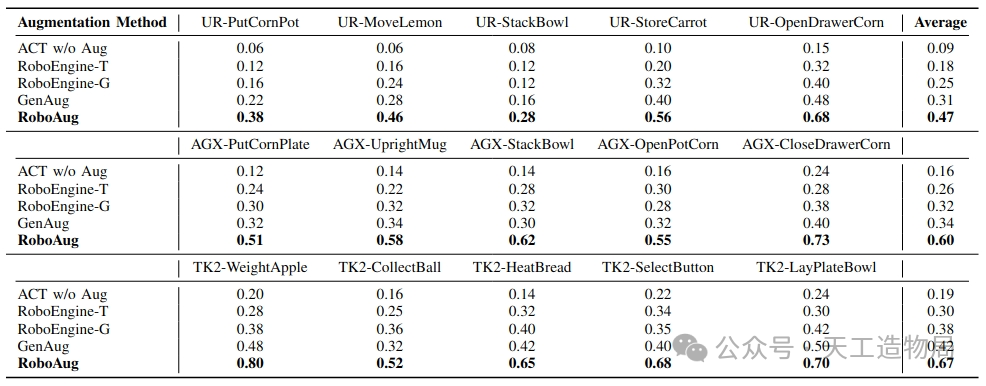
团队在高度非结构化的、严苛地解耦了环境变量扰动的多模态评测基座上进行了评估实验。针对分布外(OOD)的数据漂移特征------即完全未知的场景纹理、高达20种强弱突变复杂光照环境、伴随至多10类任务无关的密集干扰物(Distractor),模型充分显现了稳健鲁棒的域自适应表现能力。
特别是在复合扰动(Triple-Factor Variation)这一"地狱级"难度下相比仅采集基准演示集,RoboAug 完全压制了各种灾难性遗忘与泛化退化。
- UR-5e 单臂协同基线:在强干扰场景下的动作执行鲁棒成功率由 9% 跃迁至 47%;
- AgileX 具有移动底盘的双臂操作基线:整体闭环序列成功率由 16% 断崖式攀升至 60%;
- 基于大自由度的天工2.0人形机器人全场景评估:通用操作泛化能力由 19% 跃迁至高达 67% 的成功率!
![fd7451d154bdd202094d7a73934941f8.png]()
真机部署表现
场景1:多维复合分布偏移考验(背景纹理换置+高密集 Distractors+全局光照扰动),不论是复杂长时程多步依赖的时序任务,甚至是涉及冗余自由度空间控制的双臂精细协同规划,RoboAug 凭借其强劲的注意力表征,均实现了近乎免疫性的视觉鲁棒位姿估计与动作序列输出!
![8e1c5c85ff16dfbfe91b1ac0a3db979d.jpg]()
![3fdfe1519c9adca6fc5f7ec055143bb6.jpg]()
![8624ea744fb53b1a2741ae3485e51723.jpg]()
场景2:边缘形态的灾变性单一变量施压(Ablation under Severe Single-Factor Shift),在测试集外超过 170 个零交集(Zero-overlap)语义背景纹理替换、逾 20 种强空间变换光源照射,乃至于在紧凑的工作空间内密集堆叠超过 10 种具有高度混淆性的物理干扰实体(Distractors)等情况下,RoboAug 有效抑制了对伪特征的拟合,提取并锚定到了高维稳定的语义中心区域!
![b9cfa9fb0a140cfa7b2f6a2b09cbbc42.jpg]()
![84995a159d502ed7c89805eb7b07102c.jpg]()
![dc8637ec468fe245234723f307eed8c3.jpg]()
零样本与基线对比:对抗未规划轨迹的主动纠偏与抗干扰演练(Robust Action Alignment under Visual Perturbations),在前所未闻的高维组合扰动(OOD Combinations)物理交互中,各大纯视觉策略基线模型(Base Policies)往往受累于非因果(Non-causal)特征映射,频繁发生策略遗忘与幻觉动作,表现为严重的空间位姿误判与抓取失效。与之形成鲜明技术代差的是,RoboAug 的表征不为局部噪声或材质偏移所惑,自始至终在闭环控制序列里展现出高频可靠的行动引导。
![57ed2cd514d9ad062486167a717694f3.jpg]() }
}![4cee356fdbb999137f41dcf24d07f995.jpg]()
![3d6a95bdbb358e4a4ddbb003027775f4.jpg]()
结语
具身智能要真正走进千家万户、应对非结构化的复杂世界,强大的跨场景泛化能力是必不可少的敲门砖。RoboAug 为我们提供了一条高效、低成本的技术捷径。"一图胜千言,一框衍百景",研究团队期待这项技术能加速机器人的规模化落地。






 }
}

