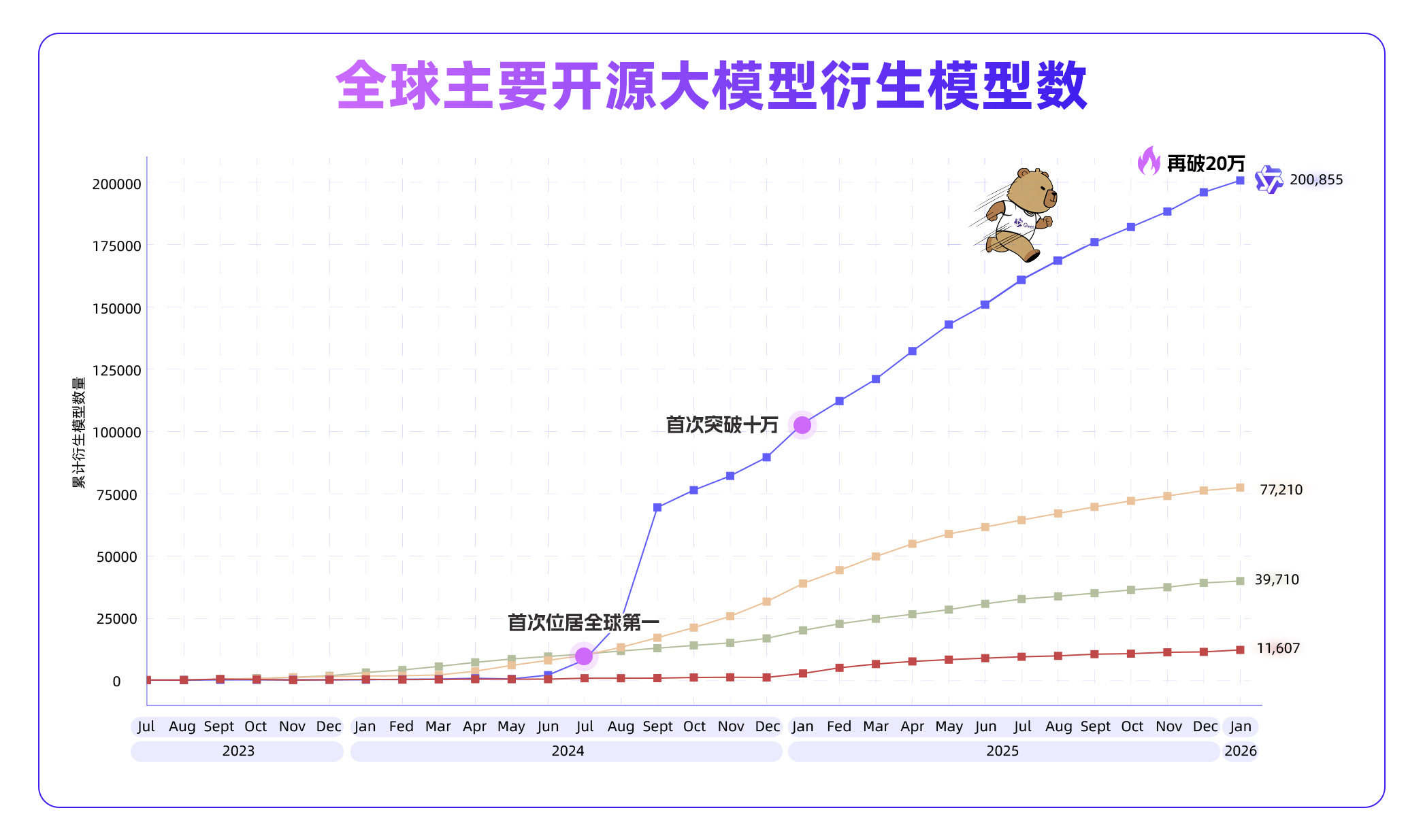
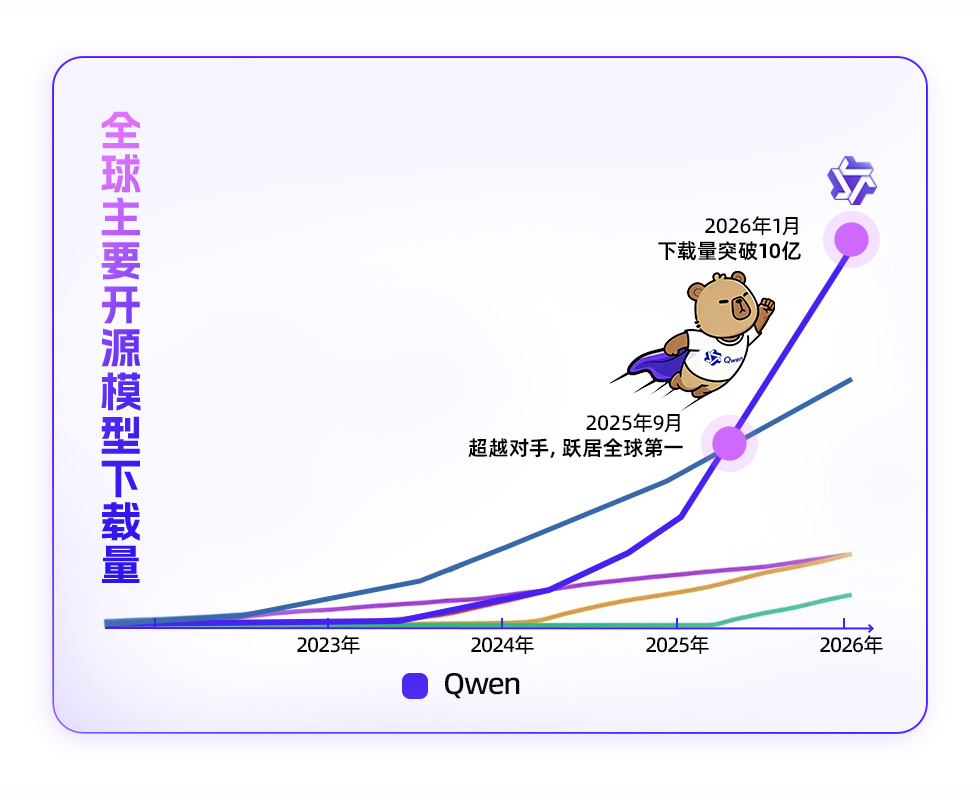

月之暗面总裁张予彤透露 Kimi 新模型即将发布
月之暗面 Kimi 总裁张予彤出席世界经济论坛 2026 年年会时透露了 Kimi 的下一步动态,称“我们很快就会发布一个新模型。” 据张予彤介绍,Kimi 仅使用美国顶尖实验室 1% 的资源,就开发出 Kimi K2、Kimi K2 Thinking 这样全球领先的开源模型,甚至在部分性能上超越美国的顶尖闭源模型。“从创业第一天起我们就清醒地意识到,中国初创公司没有随意堆砌算力的条件。”她表示,“这迫使我们通过大量的基础研究创新来换取极致的效率。” 张予彤透露,Kimi 投入了大量精力将工程化思维引入研究环节,确保所有算法创新都能在生产系统中大规模稳定运行。例如,Kimi 是全球首个在大型语言模型训练中跑通 Muon 优化器的公司;同时,自研的线性注意力机制(Kimi Linear)在处理速度上已显著超越传统的全注意力系统,实现了效率的跨越式提升。 在论坛问答环节,当被问及今年是否会出现新的“中国 AI 时刻”时,张予彤笑着回应:“我们很快就会发布一个新模型。”