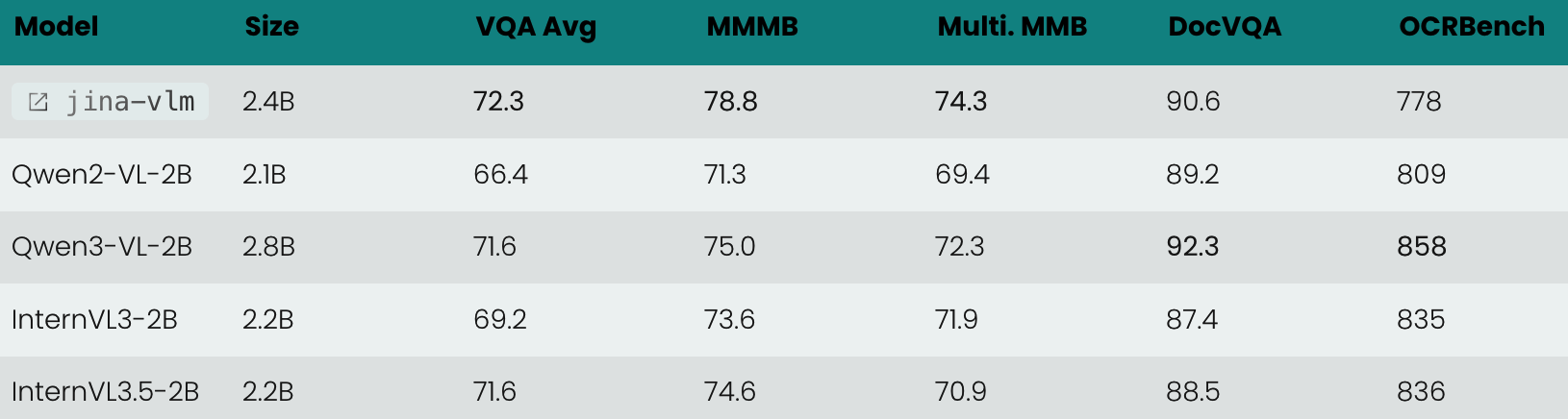
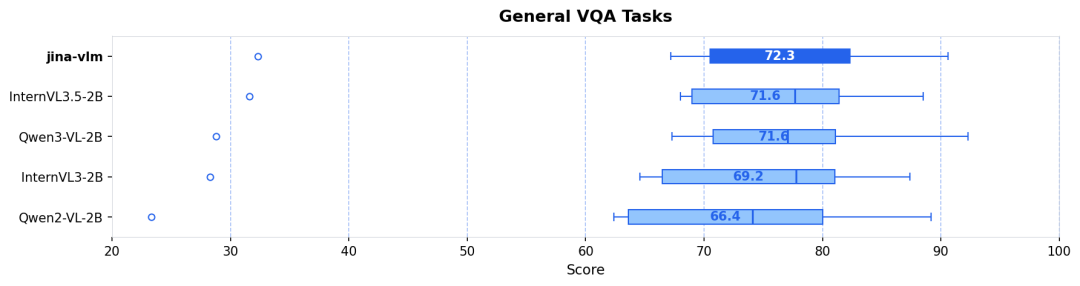
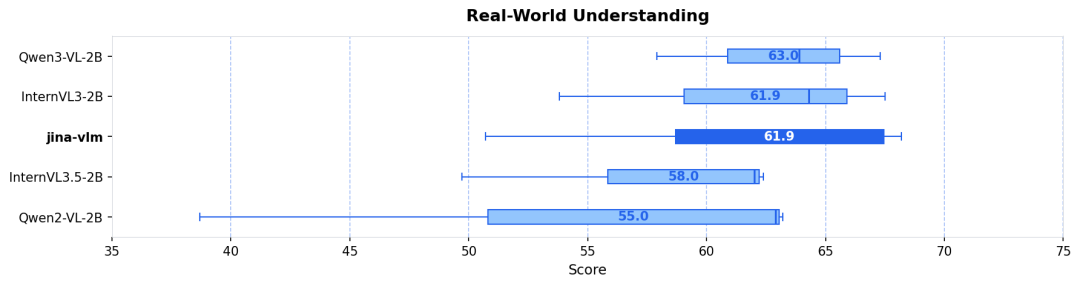
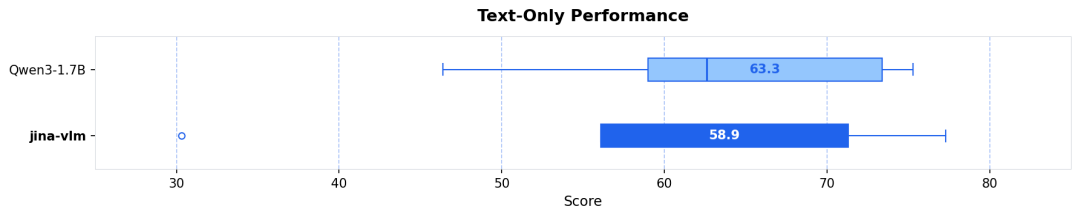

SpaceX 估值暴涨至 8000 亿美元,或将成全球估值最高独角兽
据最新消息,SpaceX 正在与投资者洽谈一轮新的股份出售,预计这将使公司的估值飙升至8000亿美元。这一数字几乎相当于瑞士的 GDP(9000亿美元),也将使 SpaceX 超越 OpenAI,成为全球估值最高的独角兽。 值得注意的是,SpaceX 的估值在短短五个月内翻了一番。在今年7月时,SpaceX 的估值还为4000亿美元。 SpaceX 成立于2002年,总部位于德州,是一家专注于航空航天和太空运输的私营公司。马斯克的目标是降低太空发射成本,并为人类移民火星铺平道路。虽然这个目标听起来颇为宏大,但在马斯克的推动下,SpaceX 在火箭发射领域已取得显著成就。 此次股权出售将采用二次股票出售的方式,现有股东(如员工和早期投资者)将其手中的股份出售给新投资者。通常,这种方式是为了帮助老股东套现,而资金不会直接流入公司。这次计划由 SpaceX 首席财务官 Bret Johnsen 向投资者透露,公司的估值将在交易完成后得以确认。媒体报道称,交易的股价或将定在300美元左右,估值可能达到5600亿美元,具体数字仍在不断变化中。 此外,SpaceX 还预计将在明年下半年进行首次公开...