打开链接点亮社区Star,照亮技术的前进之路。每一个点赞,都是社区技术大佬前进的动力
![]()
Github 地址: https://github.com/secretflow/secretflow
一、行业应用背景
随着大数据人工智能等技术的发展,推动健康险迈入3.0时代,保险行业数字化转型中服务逐步实现向线上迁移,数据合规使用为保险理赔模式优化带来无限可能。
其中,商业健康险作为促进多层次医疗保障体系建设的重要组成部分,对于国民医疗健康具有重要意义。2022年1月,中国银保监会人身险部向全国各人身保险公司下发《关于印发商业健康保险发展问题和建议报告的通知》:"争取与医疗机构信息系统实现充分信息共享,改进结算服务;在确保信息安全和个人隐私权的基础上,强化医疗健康大数据运用,推动医疗支付方式改革,更好服务医保政策制定和医疗费用管理。"
面对理赔业务升级需求以及监管的要求,保险公司在服务创新的过程中需要优先重视数据合规,因而隐私计算就提供了这种中立可信的技术支撑。
为了解决千万级在保用户住院医疗险的理赔体验、成本和效能问题,蚂蚁保险科技团队与保险公司合作,构建了基于理赔科技平台和**隐私计算框架"隐语"**的"理赔大脑"智能理赔系统。
二、案例整体介绍
系统基于住院医疗险理赔凭证图像的机器学习,借助数据优势(数十万级典型理赔案件)并辅以一定的知识约束,实现了视觉识别+文本分类+文本语义理解的多模态医疗凭证识别模型(对100+种医疗理赔凭证的识别准确率达到95%以上),突破了真正可以大规模商业化应用的医疗凭证深度结构化和**"专家级"高置信辅助核赔决策**能力,帮助保险机构理赔效能提升70%以上。
系统基于"隐语"框架的大范围线上数据化合作调查能力,又进一步减少了保险公司线下调查的成本和时长花费,将医疗事实调查的数字化和智能化应用,推进到了一个新的高度。
三、隐私计算在本案例的应用
为了有效发现阳性线索,降低错赔风险。需要合规使用外部医疗数据,充分发挥其价值。现有MPC技术适用于多方联合建模(如联合风控场景),但不适合策略驱动、强规则计算的理赔阳性风险发现场景。
在整个系统中,健康险定制多方数据联合分析解决方案是核心模块之一。本项目基于"隐语"提供的MPC SQL多方联合分析领域专用语言,构建了健康险定制多方数据联合分析解决方案,覆盖了全国案件占比50%省份的官方合法来源医疗数据,为医疗数据的合规使用提供了一种典型案例。
这一方案基于多方安全计算技术,使用安全加密算法将多方数据进行联合分析。帮助保险公司及其外部医疗数据ISV在原始数据不离开本地、数据价值有保护的前提下,进行联合分析。在最大程度保障用户隐私的基础上,满足了业务需要。
四、多方联合分析过程
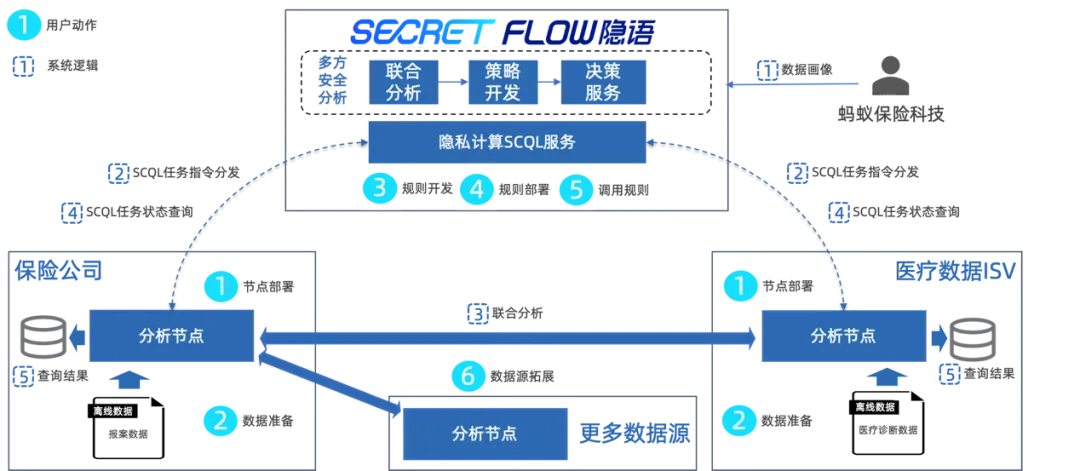
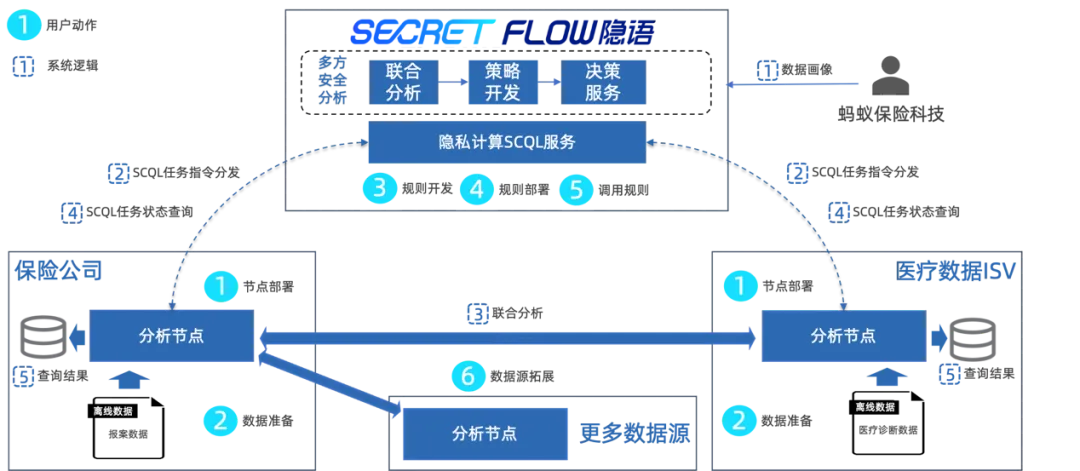
蚂蚁保与保险公司基于"隐语"框架的多方联合分析能力,在保障联合项目各参与方数据隐私前提下,引入外部数据源完成联合分析的流程如下:
![be454456-d944-437e-a4d8-0741c3eda093.png]()
![图片]()
用户一键获取部署包,填入节点标识&token信息后执行脚本,即可轻量化、小时内完成本地节点部署;
双方分别将各自的样本数据,加载至各自本地分析节点,并在平台上注册对应样本的数据表结构,同意授权进入多方安全分析项目。
基于隐语的丰富MPC SQL算子支持,用户可以在脚本中描述基于多个数据源的安全计算,通过"SELECT FROM"、"JOIN ON"、"GROUP BY"等语句的组合搭配,即可完成联合分析的统计结果生成;通过"SELECT INTO"语句可将交集结果导出至节点本地。
随后,用户可使用ISV授权的数据,通过联合分析提供的在线SCQLIDE,在平台完成在线调试优化规则,且经调试验证后的规则可作为标准规则在更多数据源进行规模化部署。
规则部署完成后,用户在平台端即可对规则发起调用,且隐语支持简单的数据分析结果可视,如就诊分布、就诊频次等分析结果。
用户还可通过持续引入外部医疗数据进一步提升丰富底层数据能力,进一步提升自身理赔和风控能力,增加核保场景智能决策服务。
五、案例隐私计算技术突破
在数据准备环节中,用户可通过隐语的CCL前置安全配置功能,在MPC相关技术能力支撑下,对数据资产进行分级分类,通过前置配置来保证安全级别高的数据的安全性,保证多方隐私数据在计算过程中不泄漏。
- 丰富MPC SQL算子支持 编写脚本描述基于多个数据源的安全计算
隐语支持:算术计算(+, -, *, /, %)、比较(>, <, >=, <=, =, <>, IN, NOT IN)、逻辑计算(AND, OR, NOT)、窗口聚合(group by ... min, max, avg, sum, count, median )、控制(IF, CASE WHEN)、排序(RANK, ROW NUMBER, ORDER BY)、日期函数(DATE_DIFF, DATE_ADD)、其他函数(ceil, floor, round...)丰富算子。
-
底层数据能力持续丰富能力
![5639e98a-ac03-4963-9c5d-b1e0ddd170d6.png]()
在如上隐语框架分层总览图所示,隐语在资源管理层面向业务交付团队,可以屏蔽不同机构底层基础设施的差异,降低业务交付团队的部署运维成本。另一方面,可以对联合项目中的节点、数据、成员核心资源进行集中式管理,构建出一个高效协作的数据协同网络。
在整个智能理赔系统中,隐语框架聚焦于合规引入ISV的医疗数据,在数据用于分析、机器学习的过程中则更涉及就医凭证多模态分类识别、医疗文本NLP深度学习引擎等技术,是隐私计算与其他技术综合应用的典型探索,对图像、文本等更多类型的数据价值协同挖掘利用具有范式效应。
六、案例业务成效
基于隐语MPC SQL多方联合分析领域专用语言的健康险定制多方数据联合分析解决方案,有利于提升阳性案件识别和调查路径规划能力,覆盖了全国案件占比50%省份的官方合法来源医疗数据,为医疗数据的合规使用提供了一种典型案例。利于有效发现阳性线索、降低错赔风险,通过数字化调查审核控制了理赔运营成本,更有利于扩大普惠医疗的服务范围、提升普惠医疗的服务效率。
"理赔大脑"智能理赔系统上线后,整体相对于传统线下调查作业,调查案均成本降低了40%,赔付率控制在了合理水平,保障了业务持续健康发展。
七、案例推广展望
此次健康险定制多方数据联合分析解决方案的落地不仅有利于商业健康险的降本增效良好发展,更可拓展应用于医疗行业中的前沿技术合作、创新药研发、高端医疗器械研发应用以及疾病风险评估、疾病预防、分类诊断等众多场景,联通多种类型的医疗健康数据。
在我国,健康医疗大数据作为国家重要基础性战略资源在管理决策、公共卫生、临床科研、惠民服务、行业治理和产业发展等众多方面影响深远。医疗健康大数据生态的构建,有利于平衡医疗资源本身在地域分布上的差异,促进社会资源的合理分配,提升国民健康服务的整体水平。