当代码融入黑夜,当系统静默运行,是谁在守护着数字世界的稳定与安宁?
又是一年 1024 ,由快猫星云主办的 1024 程序员节特别直播“1024守护者之夜:用可观测性点亮系统稳定”已于前一晚圆满落幕。
在这个充满极客精神的夜晚,快猫星云联创& CMO 秦晓辉、B站 SRE 负责人武安闯、OSCHINA.NET 负责人林师授三位行业大咖,以“系统稳定性建设”为题,从实战体系、高效方法论、社区应对策略等多个维度,为大家带来从硬核技术分享。
![]()
直播精彩回顾
分享一:《 SRE 稳定性体系建设分享》
快猫星云联创& CMO 秦晓辉
“ 可观测性,其实最核心应该从 SLO(服务等级目标)着手,需要与业务团队一起率先梳理好 SLO 。”秦晓辉老师表示,SLO 这个指标,是谁拍板呢?其实应该是业务团队来拍,而不是运维人员:根据业务的实际需要,制定出错误预算,以及预估消耗完错误预算之后,系统呈现怎样的行为,这些都是需要提前梳理的内容。
![]()
直播中,秦晓辉老师举了一个 Google SRE 的典型案例:以 28 天为周期,形成 SLO 的计算窗口,在这个窗口中,将上线的稳定性着以次之,从而凸显上线效率,以及创新性。一旦消耗完了错误预算,即便窗口还有剩余时间,比如还剩 3 天,也依旧不能上线了。
“通常现在各个公司都是微服务了,每一个服务都应该有自己的 SLI ,并且我们应该建立一个全局、可查的 SLI 指标查询分析系统。”简言之,虽然各个服务都有自己的仪表盘,但是少有企业将这些仪表盘统一在一起,那么就会缺少一个全局的视图,当出现问题的时候,运维人员其实很难定界哪里出了问题。
秦晓辉老师提及,可观测性中目前常用的指标有:
-
梳理关键指标,如参考 USE、RED、Google 4 Gold Signals 等方法论
-
业务北极星指标
-
依赖的基础设施、第三方服务、第三方接口的指标
-
上游流量的指标
-
系统内部的一些业务逻辑指标,比如内存队列的长度
而在“日志”上,又有哪些关注点呢?秦晓辉老师提到了以下五个方面:建立中心化的日志平台,把分散日志收集到中心,方便查看日志流;日志统一打印成 JSON ,方便收集、ETL ;遵循 Cannonical log lines 或 Wide events 理念打印日志;各日志字段统一规范(比如统一名称及语义),统一 SDK ;最后,就是建立日志告警规则。
“可观测性,除了以上的几大支柱建设,其实最终还是需要下沉到对数据的分析这一层。”在数据分析层面,秦晓辉老师指出,建立了多套指标、日志、链路系统,有海量数据,但没有洞悉,那就没有什么意义。企业不仅需要建立各个维度的全局视图,建立“总-分”结构的下钻链路,同时也需要着眼于数据特性,而非炫酷的图表。并且,还需要将现有的数据串联起来,比如从日志跳转到链路追踪,最终根据日常故障排查路径组织数据,将经验沉淀到产品力,确保长远的稳定性。
“当然,后续也可以引入 AI ,自动根据人工运维这个路径进行周期性排查。”
相关推荐工具:https://flashcat.cloud/
分享二:《 把攻击变成能力——从超大流量到长期稳定》
OSCHINA.NET 负责人 林师授
分享开始前,林师授老师分享了今年 5 月平台遭受恶意攻击的过程,从最开始的流量试探,到后面的可疑 IP 暴涨,加码至千万级伪装浏览器访问,最终导致服务器卡顿、故障。而在本次恶意攻击的防御中,林师授老师分享了当时的应对方式:
-
止血:扩容、高防、黑名单/限速/限流/JS Challenge ,但此举成本高、容易误杀
-
稳态:观测先行(误杀率/限流命中率可视化)、战情室协同、防御 TCO 仪表盘
-
进化:把策略下沉到网关/缓存/对象存储/分发,做自适应挑战与速率重,始终以开发者体验为边界
经历此事之后,林师授团队做了严格的复盘,不仅仅记录了本次防御,同时还从本次防御的过程中制定了保障后续平台稳定的SOP,包括:监控、告警方面,补全本次攻击中所缺乏的指标数据,并在关联告紧,将数据串联起来,同时做到夜间联动(本次攻击发生在中国区夜间时段);值守、备份方面,指定多角色轮值制度,以 SOP 标准日常进行 15min 救火演练,且常态化;服务器方面,新增应用级降级服务器,及相关预案,同时增加读写分离,而面对高风险接口,增设熔断/灰度开关;在性能方面,借助此次攻击事件,将慢查询集中做了清理,提升底层吞吐能力。
“在原则和取舍方面,我们首先遵循开发者体验优先,首先得让开发者能用到、读到;其次就是可观测优先,可量化才谈得上去优化;最后就是可演进优先,也就是被攻击后的平台升级,修补自身漏洞,建立防御机制。”
在构建平台全链路风险防御网的过程中,林师授老师提到了“三层机制+六环节”:
具体怎么去做呢?林师授老师提出:首先得建立全维度数据联动,消除观测盲区,在基础层秒级采样 CPU、内存、宽带、磁盘、队列等,形成稳定性基线;在业务层联动接口错误率、登录成功率、页面加载时长等用户有感指标,先判定“热点/噪声/层级”,再决策动作;在历史层,将多年的时序指标做趋势与季节性分析,最终指导容量及预算。
![]()
林师授老师最后表示,实际上,SRE是“稳态”与“进化”的平衡艺术。
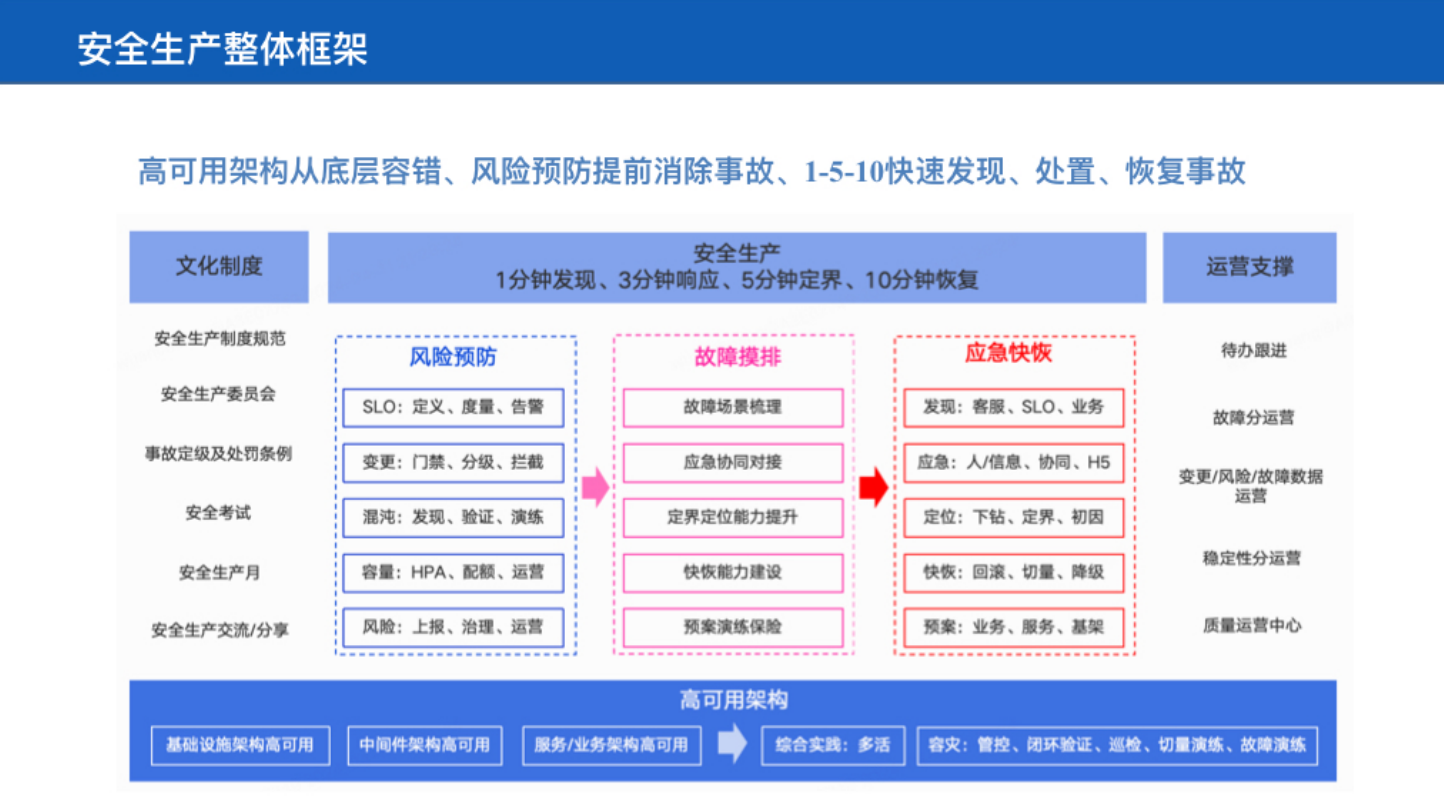
分享三:《面向 1-5-10 的稳定性思考与实践》
B站 SRE 负责人 武安闯
武安闯老师的分享,主要围绕“1-5-10”的背景与挑战,以及 B 站的稳定性框架与数据运营。这几年,行业的事故发生的比较多,B 站也不例外,比如说:某服务配置变更,需要两可用区发布,但发布时未严格灰度、观测时间短;某服务代码变更,业务框架设计不完善,大量请求回源 DB 过载,业务异常等......
“分几个角度来讲,业务上的压力增加、历史债的问题爆发、效率优先导致的故障红线管控,以及变更质量降低等等。基于此,B 站指定了 1-5-10 安全生产规范,即:1 分钟发现、5 分钟定界、 10 分钟回复。”
![]()
关于故障应急与定界定位,武安闯老师介绍了三个方面:
包括:自动建应急群、通告;SRE、RD、Oncall ,快捷入群;故障应急文案推送;业务自定义故障应急推送;电话升级等。
包括:上游影响面分析;可用区、应用下钻分析;错误 path 、 code 占比;Top 实例占比分析...
包括:基于链路告警分析;基于变更快速定位变更诱因;基于链路指标分析、初因推荐
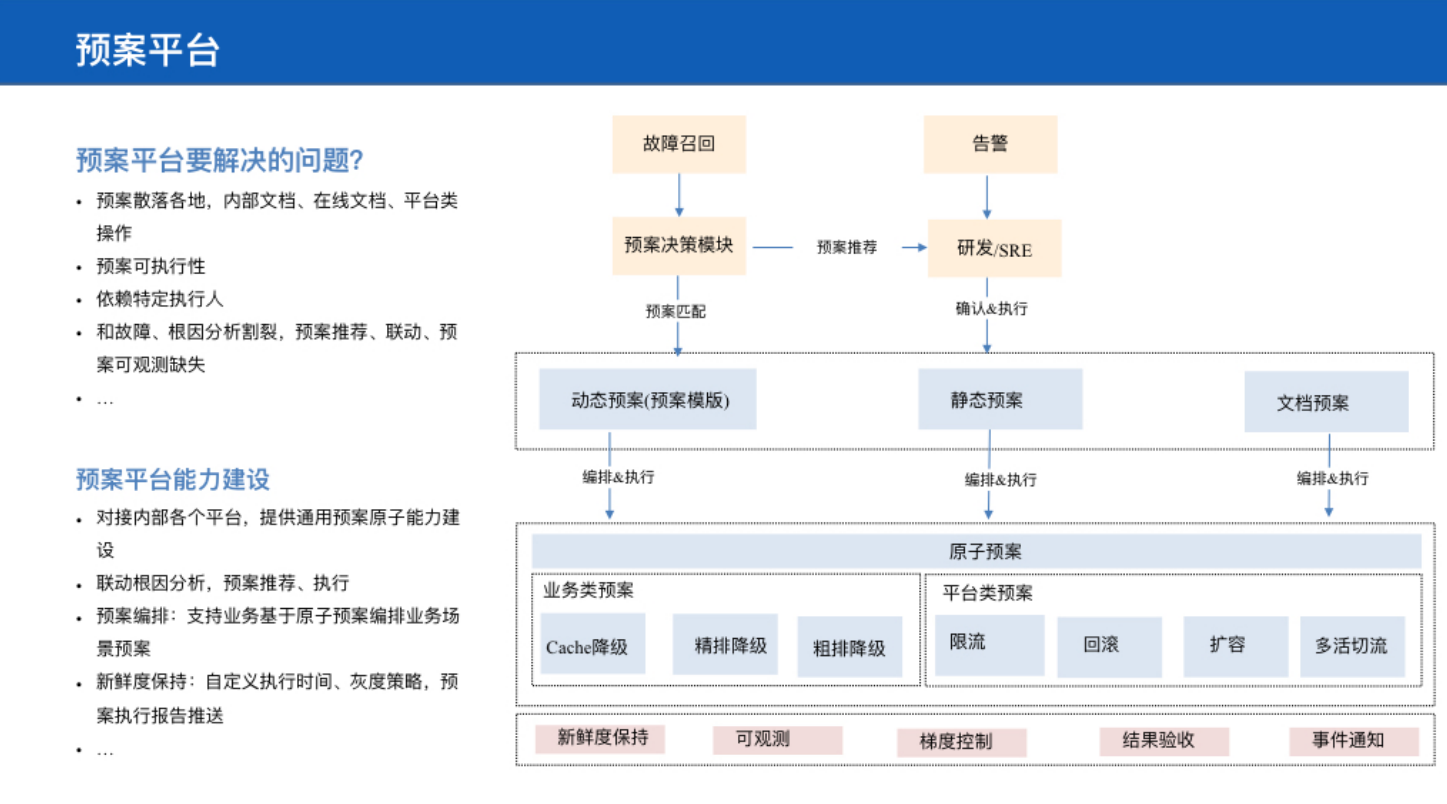
而预案平台需要解决哪些问题呢?武安闯老师指出:1、解决预案散落各地,内部文档、在线文档、平台类操作 2、预案可执行性 3、依赖特定执行人 4、和故障、根因分析割裂,预案推荐、联动、预案可观测性缺失。“所以,预案平台能力建设需要考虑以下四个方面:对接内部各个平台,提供通用预案原子能力建设;联动根因分析,预案推荐、执行;支持业务基于原子预案编排业务场景预案;自定义执行时间、灰度策略、预案执行报告推送等等”
![]()