阿里通义 Qwen 团队宣布 Qwen3-VL 家族再上新,新增 2B 与 32B 两个密集(Dense)模型尺寸,从轻量级到甜品级,全线覆盖视觉语言理解场景。
两种版本自由选择:
- Instruct —— 响应更快、执行更稳,适合对话与工具调用;
- Thinking —— 强化长链推理与复杂视觉理解,能“看图思考”,应对高难任务更出色。
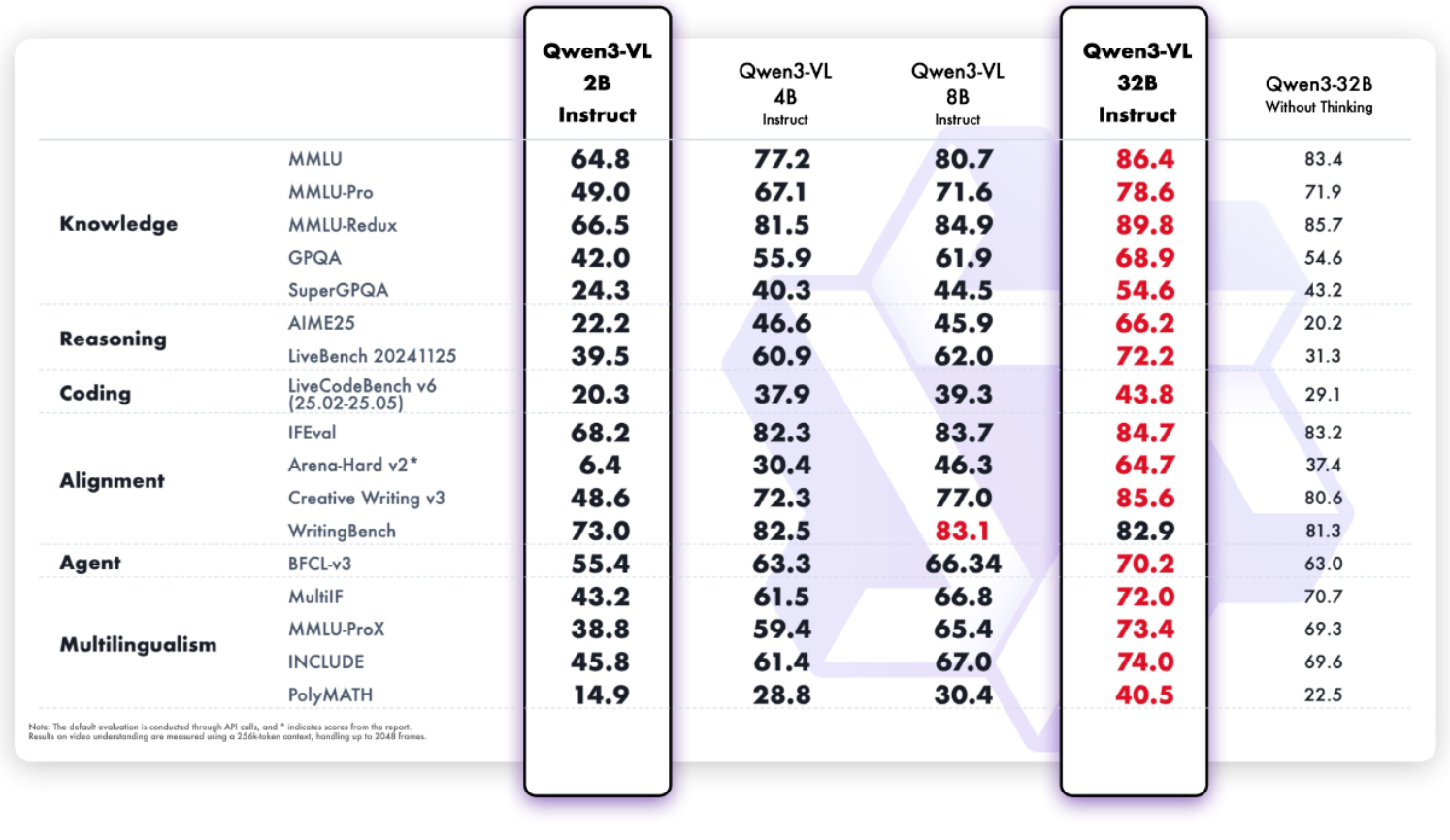
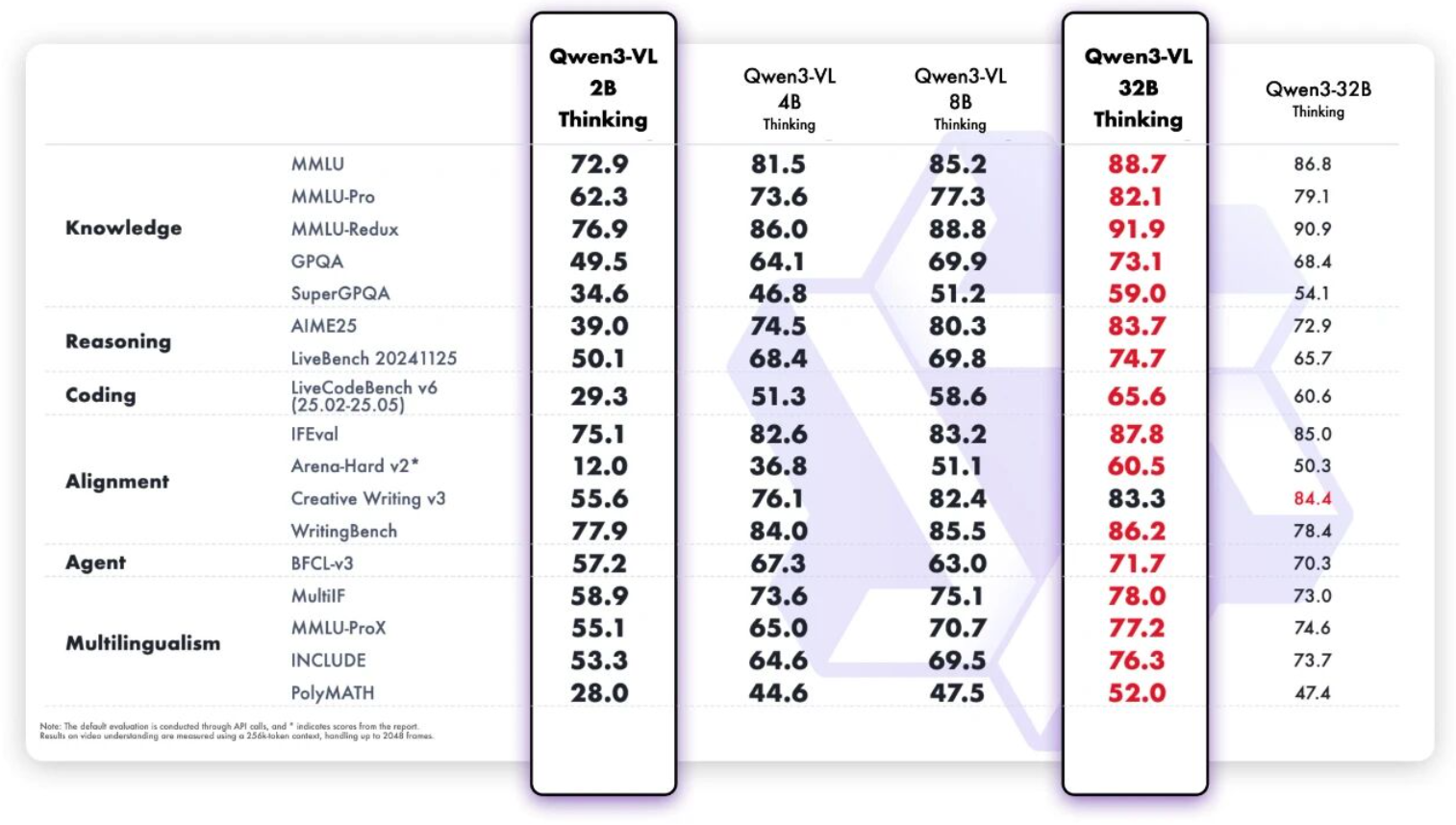
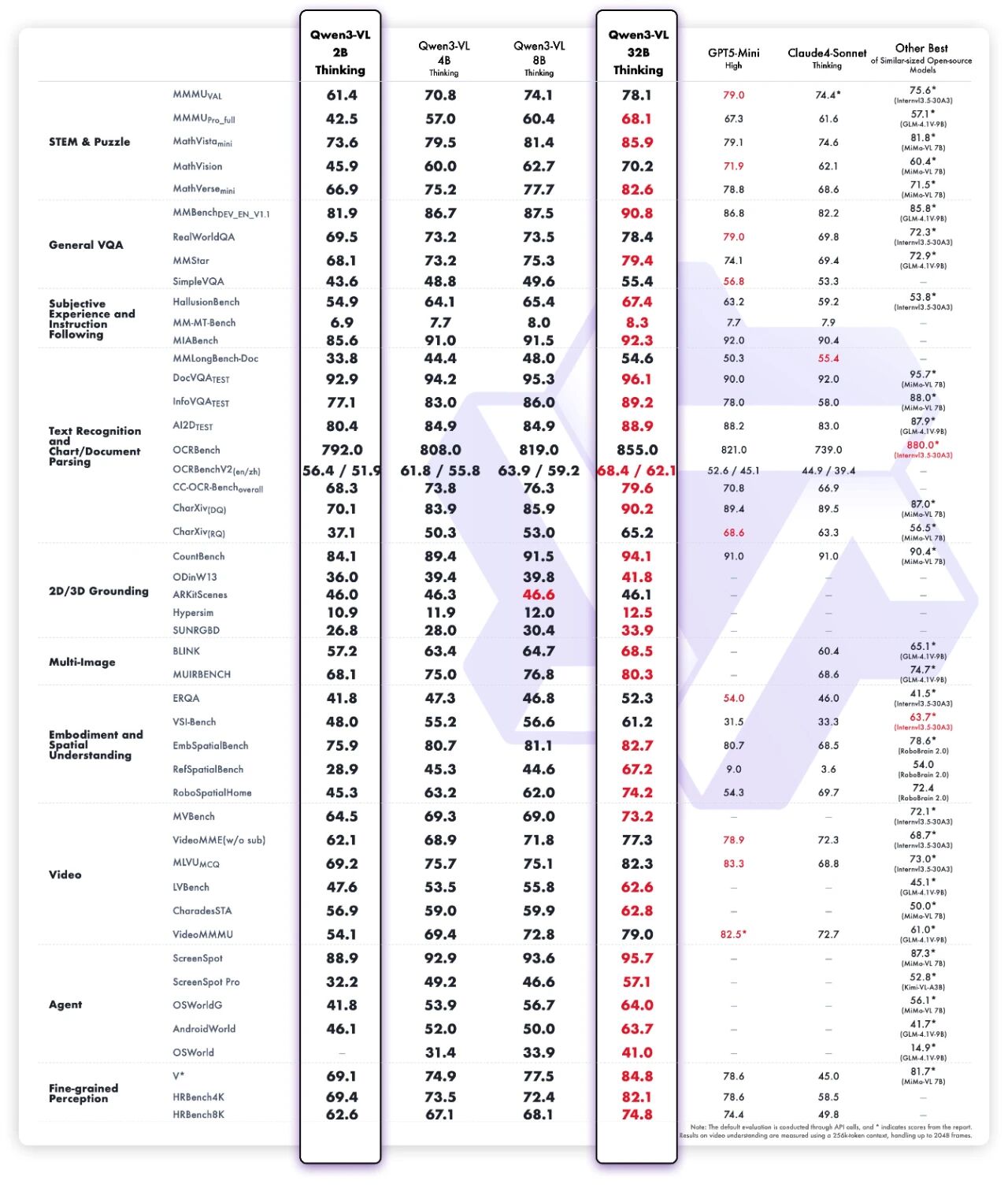
公告称,Qwen3-VL-32B在 STEM、VQA、OCR、视频理解、代理任务等方面的表现优于 GPT-5 mini 和 Claude 4 Sonnet,仅使用 32B 参数即可匹敌高达 235B 的模型,甚至在 OSWorld 上击败了它们。
Qwen3-VL-2B则在小体量下释放惊人表现,能跑在极限端侧设备上,开发者实验、部署都更轻盈。“从识图、写文,到推理、创作,Qwen3-VL 让“看懂世界”变得更轻、更快、更聪明。”
![]()
![]()
![]()
截至目前,Qwen3-VL共开源 2B、4B、8B、32B四款Dense模型以及30B-A3B、235B-A22B两款MoE模型,每款模型均推出Instruct和Thinking两大版本,以及12个模型相应的FP8量化版,累计24个Qwen3-VL开源权重模型均可免费下载商用。