智谱GLM大模型团队提出了 Glyph 框架,探索了一条不同于现有范式的上下文扩展路径。
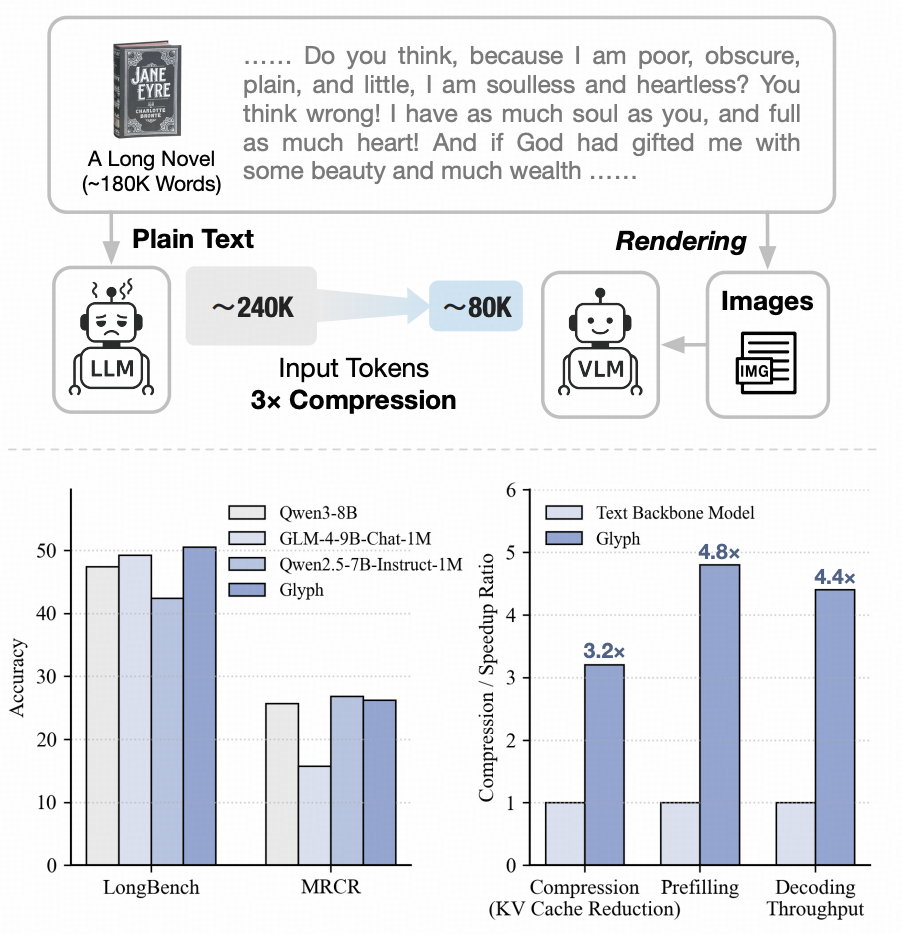
据介绍,Glyph 通过视觉-文本压缩将长文本渲染为图像,使模型能够以视觉方式理解语义。通过 LLM 驱动的搜索算法,Glyph能够自动找到最高效的视觉渲染方案,从而以更少的 token 处理更长的上下文,突破了模型本身上下文长度的限制。
在长文本基准中,Glyph 在保持性能和当前领先的LLM相近的情况下,实现了约3-4倍的上下文压缩,同时带来数倍的推理和训练加速。
Glyph 展示了长上下文建模的新方向——通过视觉化输入实现高效的上下文扩展,为构建长文本大模型提供了新的思路。
![]()
动机
在长上下文任务(如文档理解、仓库级代码分析、多步推理)中,大模型往往需要处理数十万甚至上百万 token 的输入。
然而,直接扩展上下文窗口会带来巨大的资源消耗,这大大限制了“百万级上下文模型”的广泛应用。
为了突破这一瓶颈,我们提出了 Glyph ——一种全新的视觉上下文扩展范式。
不同于基于注意力结构的上下文扩展,Glyph 选择从输入层面重新思考问题:
将文本渲染为图像,通过视觉-语言模型(VLM)读取与理解,从而在不增加模型实际上下文长度的前提下实现上下文的高效扩展。
方法
![]()
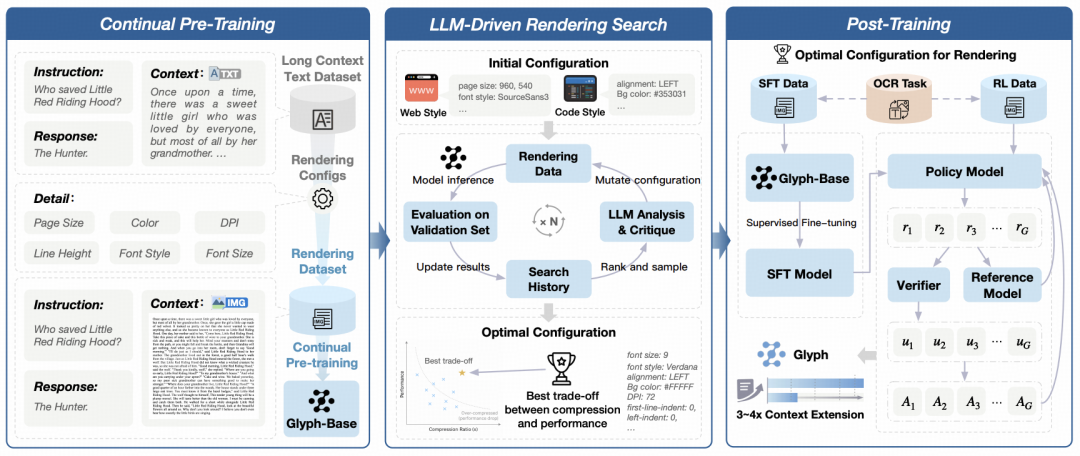
Glyph 的核心目标是让模型以“看”的方式理解超长文本。通过将文本渲染为图像,模型能够在有限的 token 数量下接收更丰富的上下文信息,实现高效的文本压缩。 整体框架包含三个主要阶段:
-
持续预训练 我们首先将大规模长文本数据渲染为多种视觉风格,包括文档布局、网页结构、代码展示等形式,以模拟不同类型的真实长文本场景。 在此基础上,我们构建多种任务,例如 OCR 识别任务、图文交错建模任务与视觉补全任务,使模型能够同时学习文字的视觉形态与语义含义。 这一阶段的训练帮助模型建立起视觉与语言之间的跨模态语义对齐能力。
-
LLM驱动渲染搜索 在视觉压缩过程中,渲染配置(如字体、分辨率、排版布局)直接影响模型的感知效果与任务性能。为了在压缩率与理解能力**之间取得最优平衡,我们提出了一种由 大语言模型驱动的遗传搜索算法。在该框架中,我们在验证集上自动评估不同渲染方案的性能,由 LLM 分析其优劣并生成新的候选配置。通过多轮迭代,Glyph 能够逐步收敛到在语义保持与压缩效率间最优的渲染策略。
-
后训练阶段 在找到最优渲染配置后,我们对模型进行有监督微调(SFT)与强化学习优化(使用 GRPO 算法)。此外,我们引入OCR 辅助任务,进一步强化模型的文字识别与细节理解能力。
总结
Glyph 开启了视觉与文本融合的上下文扩展新范式。
通过三阶段训练,Glyph 在 3–4× 的文本 token 压缩 下依然保持强大的任务性能,同时显著提升训练与推理效率。
在极端压缩场景下,Glyph 甚至能够利用 128K 上下文视觉模型 处理 百万级 token 文本任务,展现出卓越的上下文扩展能力,为从百万级向千万级上下文的进一步突破奠定了基础。