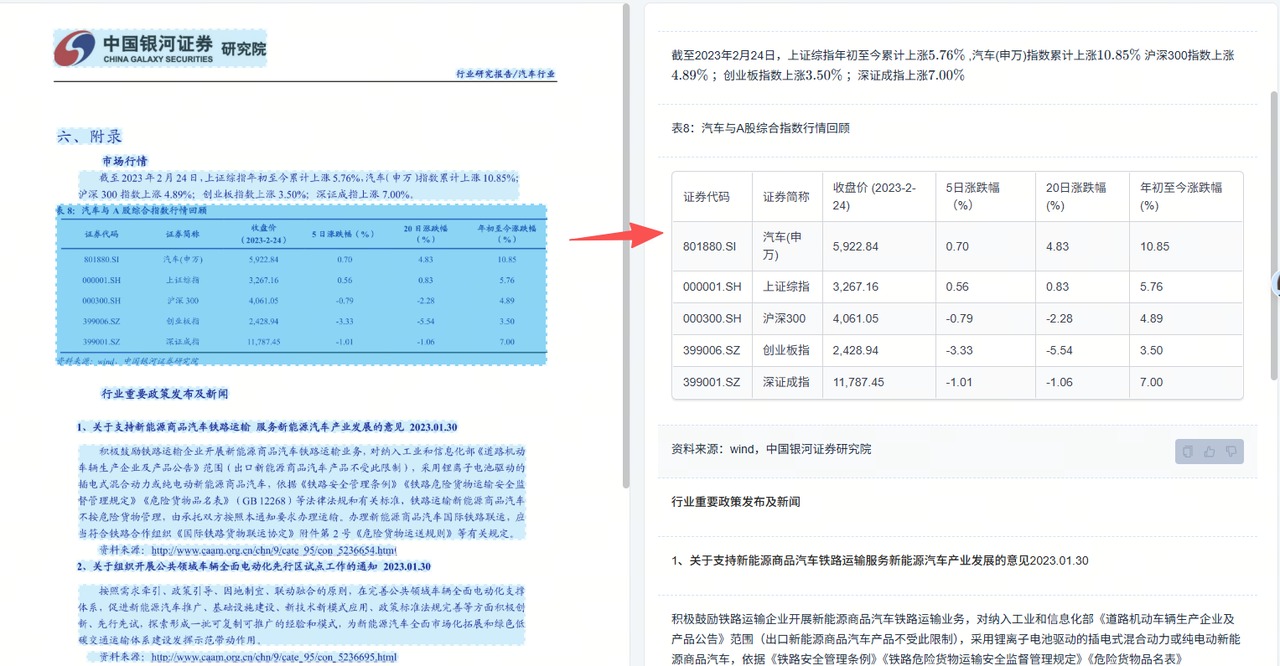
上一期我们向大家介绍了商汤自研的智能文档解析 UniParse,欢迎大家试用!本期开始,我们将对 UniParse 中涉及的技术点进行逐一拆解,希望能帮助大家更好地理解和使用我们的产品~
本期和下期的分享主题都将围绕“表格解析”展开,技术细节,一探究竟!
什么是表格解析
表格解析是将非结构化的表格图像(如扫描文档、照片或PDF中的表格)转为机器可读、可理解的结构化数据的过程。具体而言,它旨在将图像中的表格最终转为HTML等结构化表示。这种转换不仅要保留表格中的原始数据,还要准确还原其结构关系(如行列层级)与视觉布局(如合并单元格)。
下图为表格的HTML表示(左边)以及对应的图片显示(右边),比如<td></td>表示单元格,colspan="2"表示合并单元格等,表格解析即是将图片解析为对应的HTML表达的过程。
![]()
为什么需要表格解析
表格作为一种常见的信息呈现方式,广泛存在于各类文档、报告、网页和书籍中,它以紧凑的形式高效地组织数据,方便人们查看和比较信息。
然而,对计算机而言,图像格式的表格仅仅是像素的集合,缺乏语义信息。因此,通过表格解析技术,我们可以:
-
实现数据的数字化与再利用:替代传统人工录入,实现对海量纸质或图像表格的批量自动化提取,将数据高效转化为可编辑、可分析的格式,大幅提升数据入库与分析效率。
-
构建大数据的关键养料:表格作为人类高效组织数据的一种方式,数据质量高、知识密度大,表格解析后的数据可用于人工智能的模型训练和测试,是构成大数据时代数据养料的关键一环。
-
大模型时代的润滑剂:作为文档理解(Document Understanding)、机器人流程自动化(RPA)的关键环节,表格解析能为大语言模型(LLM)提供可靠的结构化输入,方便大语言模型进行分析和总结,广泛用于金融分析、学术研究、商业决策等多种场景。
![]()
![]()
![]()
表格解析的技术流程
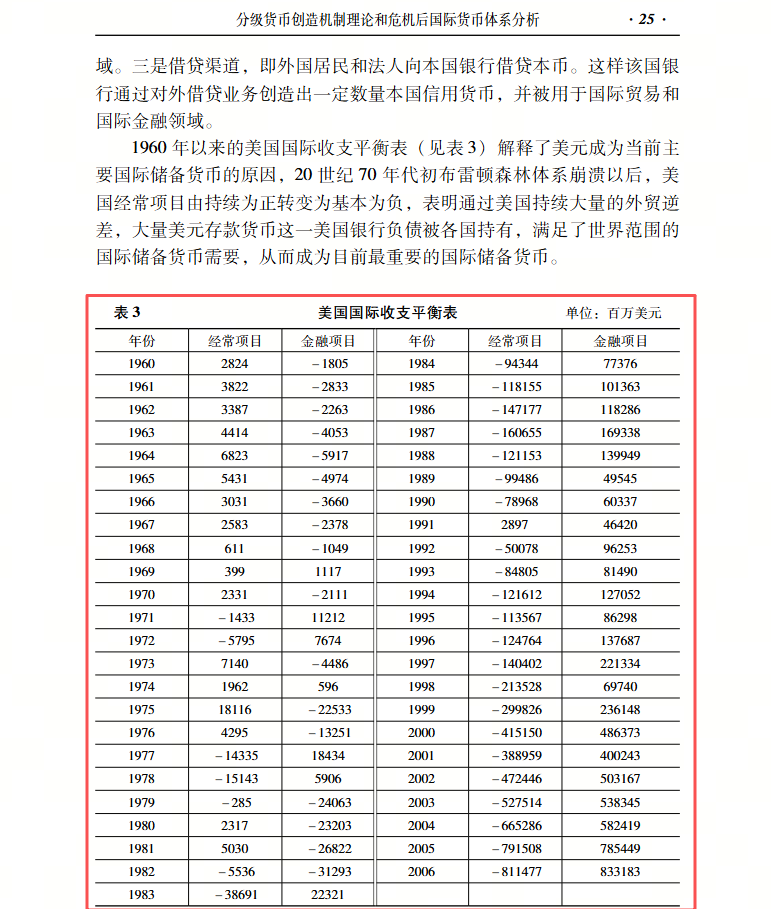
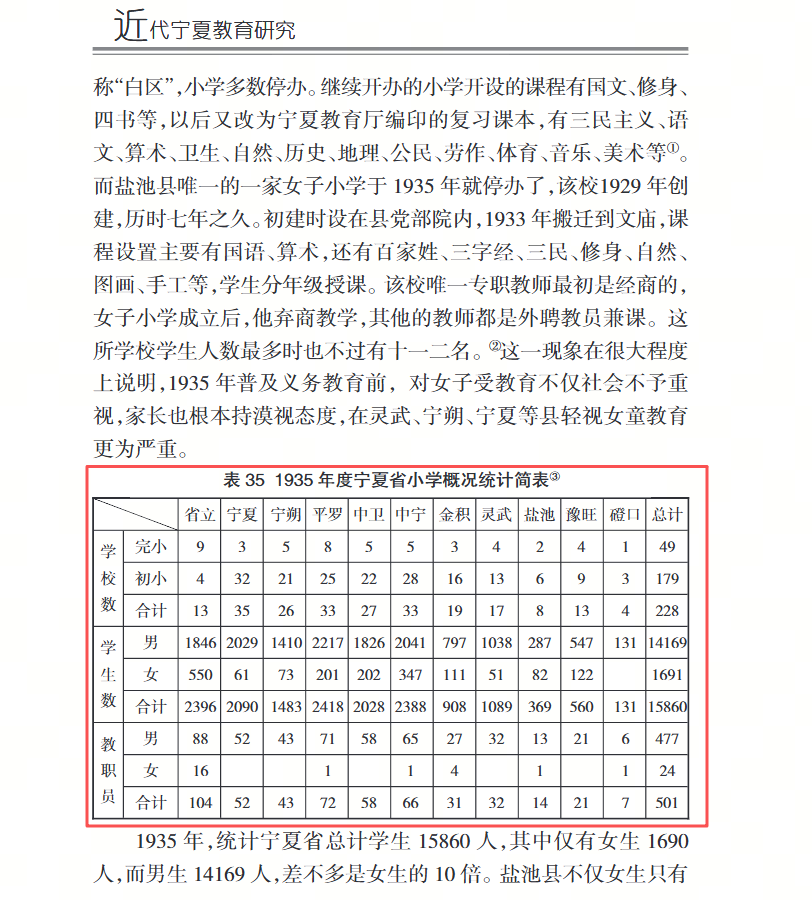
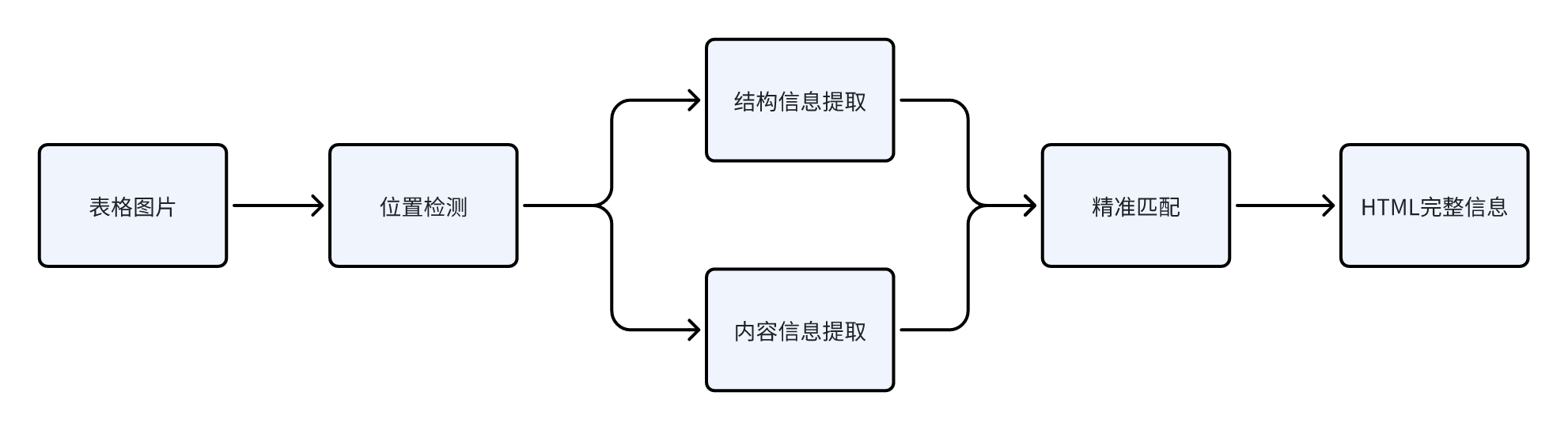
表格解析的技术方案通常包含四个核心阶段:位置检测、结构提取、内容提取和匹配后处理。
![]()
1️⃣位置检测
该阶段的目标是从输入的文档图像中定位出表格区域的位置,区分表格与文本、图片等其他元素。在版面复杂的文档(如学术论文或财务报表)中,表格位置检测尤为关键。
技术上,该任务通常被视为目标检测问题,可采用YOLO等模型,对图片进行扫描,识别出包围表格的边界框。
2️⃣结构提取
确定了表格位置后,需进一步解析其内部结构,包括识别行、列、单元格的拓扑关系(例如跨行/列合并的单元格)。
结构识别一般分为两个子任务:
基于 Transformer 的模型是较为主流的解决方案,通过二维序列建模的方式同时预测逻辑结构与物理布局。
3️⃣内容提取
内容提取即识别单元格的文本内容。借助光学字符识别(OCR)技术,实现文本检测(找到文本行的位置)和文本识别(将图片中的文字转为编码的文本)。
现代OCR引擎(如PaddleOCR等)拥有良好的提取效果,并在一些复杂场景保持较好的识别结果,比如复杂背景、特殊字体、低分辨率和畸变等。
4️⃣后处理匹配
最后的匹配阶段,将前几步的输出(结构信息和内容信息),根据物理位置关系进行精准匹配与对齐,对应到统一的HTML的语义标签上,最终生成一个完整的HTML表格字符串。后处理通常包括错误校正、冗余过滤、格式统一等操作,以确保输出结果的准确性与可用性。
完整解析过程
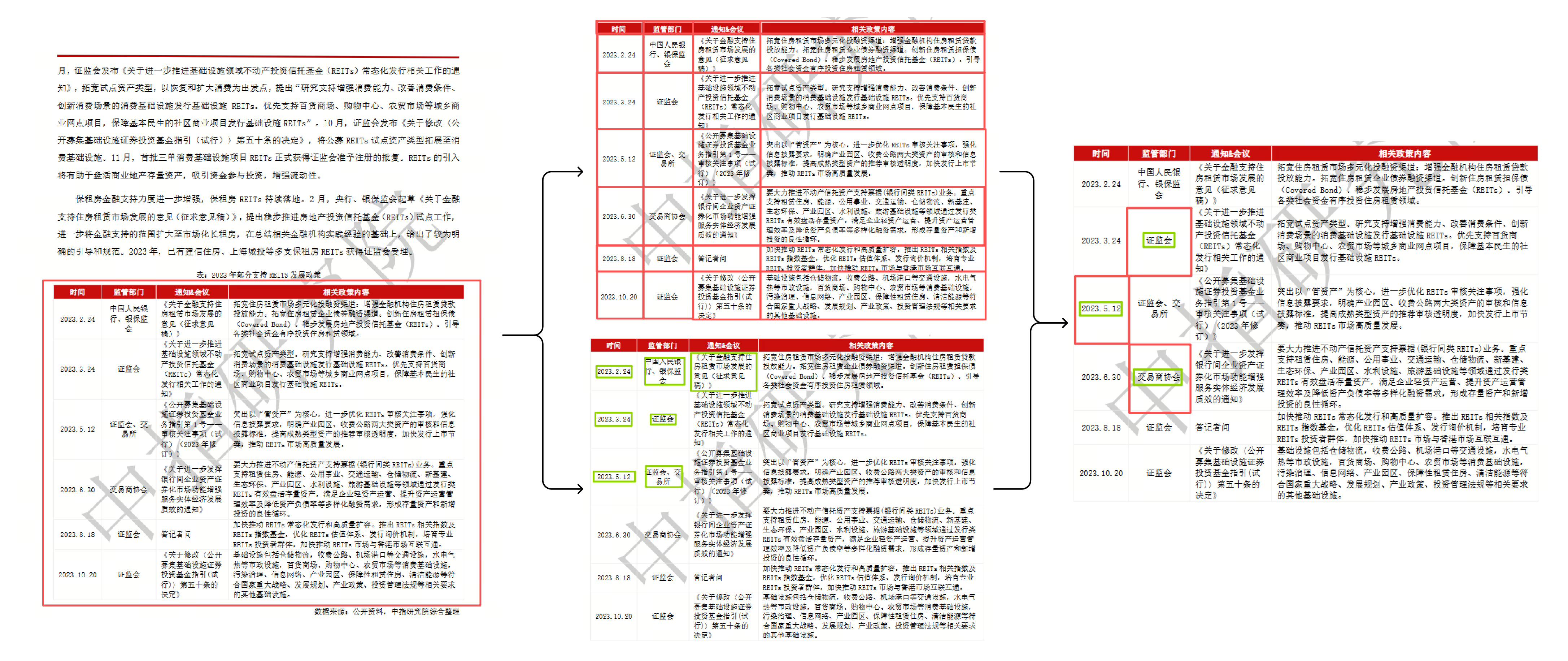
下图是完整的解析过程。首先将表格从PDF中检测出具体的位置,然后分别提取结构信息(红框表示)和内容信息(绿框表示),最后将结构信息和内容信息(红框和绿框)对应匹配到一起得到最终的解析结果。
![]()
实际应用场景
-
金融与商业:自动化处理财务报表、发票、采购单、银行对账单等,提取关键数据用于审计、分析和录入系统。
-
学术研究:从大量的学术论文和古籍中提取表格数据,构建专用知识库或进行分析。
-
医疗健康:解析医疗报告和体检表,快速结构化患者信息,辅助诊断和研究。
-
政府与法律:数字化归档的政府文件、数据和法律文书,提高公共数据利用率和透明度。
-
日常办公:将纸质表格或截图快速转换为可编辑的格式,提升工作效率。
UniParse是一款由商汤自主研发的智能文档解析工具,专注于复杂文档与票证深度理解场景,依托智能Agent技术实现结构化与非结构化数据的全面精准解析,为文档识别、信息提取及数据后处理提供全方位、高精度、流畅化的智能解决方案。
UniParse集成了丰富的表格解析功能,可以将PDF中的表格准确地解析出来,表格类型支持全线表、少线表和无线表等多种类型,解析准确率媲美最好的开源方案和业界产品。
![]()
小结
表格解析作为多模态文档理解中的一项关键技术,融合了计算机视觉、自然语言处理与深度学习等多个领域的前沿方法。该技术的发展显著增强了大语言模型及多模态模型对结构化文档的解析能力,为其提供高质量、高一致性的表格信息输入。
随着精度与泛化能力的持续提升,表格解析正日益成为企业数字化与AI应用流程中不可或缺的基础支撑环节。
更多技术内容,欢迎移步“万象开发者”gzh!