【栏目介绍:“玩转OurBMC”是OurBMC社区开创的知识分享类栏目,主要聚焦于社区和BMC全栈技术相关基础知识的分享,全方位涵盖了从理论原理到实践操作的知识传递。OurBMC社区将通过“玩转OurBMC”栏目,帮助开发者们深入了解到社区文化、理念及特色,增进开发者对BMC全栈技术的理解。
欢迎各位关注“玩转OurBMC”栏目,共同探索OurBMC社区的精彩世界。同时,我们诚挚地邀请各位开发者向“玩转OurBMC”栏目投稿,共同学习进步,将栏目打造成为汇聚智慧、激发创意的知识园地。】
PCI-Express (peripheral component interconnect express)是一种高速串行计算机扩展总线标准,它采用高速串行点对点双通道的传输架构,使得每一个所连接的设备都能够被分配到独享的通道带宽,与传统共享总线带宽的方式截然不同,独享通道带宽有效避免了多个设备争抢带宽的情况,从而显著提升了数据传输的效率和稳定性。PCI-Express主要支持主动电源管理,错误报告,端对端的可靠性传输,热插拔以及服务质量(QOS)等重要功能,这些功能共同构建起了一个高效、稳定且灵活的计算机扩展总线系统。
PCIe接口应用:虚拟网卡
在PCIe(PCI Express)系统中,BDF(Bus, Device, Function)是用于唯一标识设备的关键资源标识方式,它构成了 PCIe 设备的 "地址" 系统,让操作系统和固件能够准确定位和管理总线上的每个功能单元。BDF 格式通常表示为BB:DD.F,分别为Bus(总线号,BB),用于区分系统中的不同 PCIe 总线。Device(设备号,DD),用于标识同一总线上的不同物理设备。Function(功能号,F),用于标识同一物理设备内的不同逻辑功能(对应多 func 设备)。
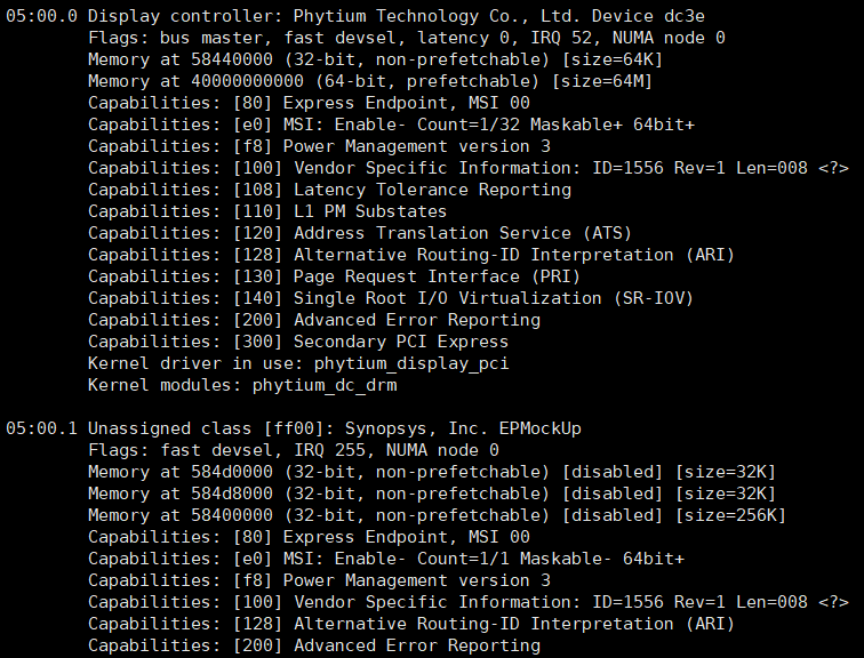
E2000 PCIe EP支持生成多个真实 function的能力,其控制器内包含3个逻辑功能单元。目前function0默认用作DC的图形显示功能,同样的其他function的BAR0都用于特定的硬件功能无法更改,但BAR1-5可以选择性的映射地址。如下图所示,E2000内核启动后按照内核EPC驱动提供的sys接口配置相关参数(如Vendor ID、Device ID等),Host上电启动后则会扫描一个05:00.1的PCIe EP。
![5394cf1461bc23fbda24be0b995f0311.png]()
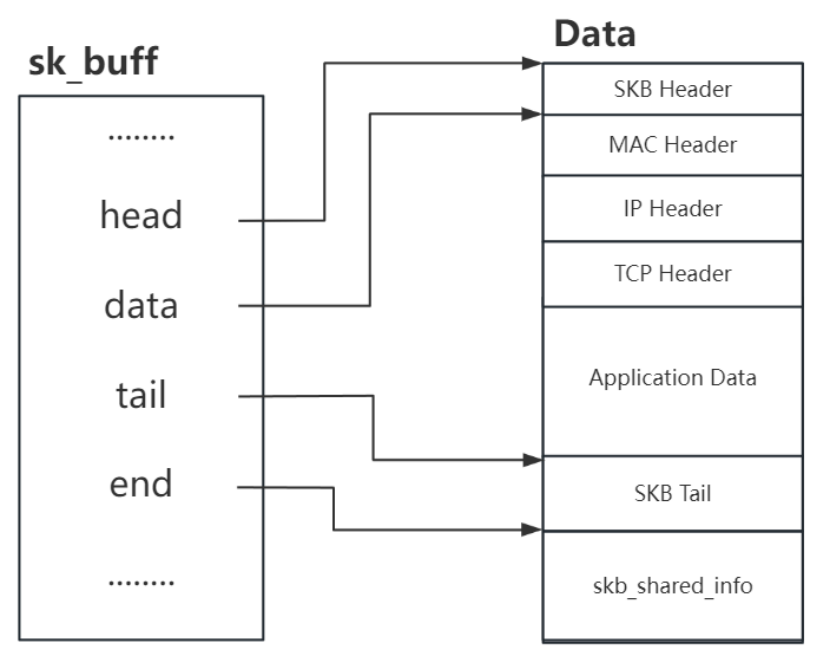
此时用户需要在E2000端基于内核EPC框架开发EP驱动,在Host端开发RC驱动。Host内核在启动过程中,会根据PCI Device ID Table(VendorID、DeviceID)自动匹配并加载对应的RC驱动。Host与EP驱动之间通过BAR空间所映射的共享内存进行通信,即前述的共享内存通信机制。用虚拟网卡为例,加载驱动后Host与EP在系统中分别呈现出一个网络设备。两者应用层可通过Socket网络编程进行通信,在内核中网络数据包以sk_buff(skb)形式进行处理,那么共享内存中传输的数据为skb的网络数据包。
![37caf6ed65835b5827f05dab40858281.png]()
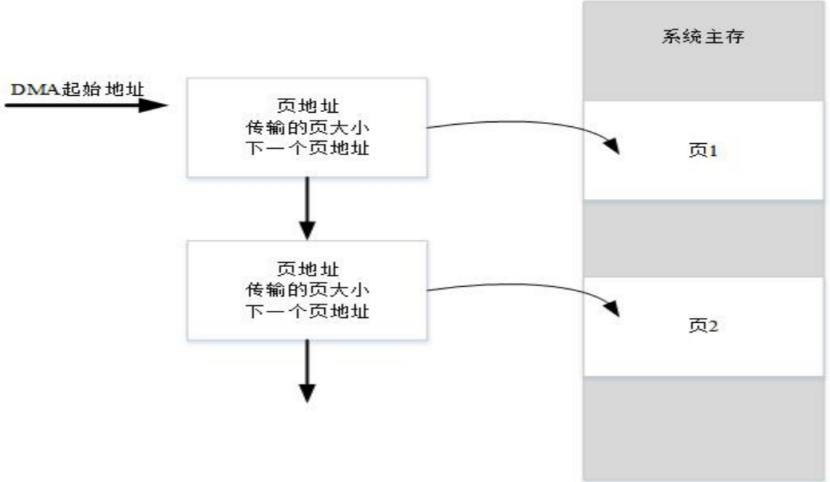
由于共享内存缓冲区大小在初始化时就已固定,若要在BAR空间里存储完整的SKB数据,就需要为其分配足够大的固定缓冲区,这会造成巨大的浪费(内存碎片化),大量碎片化网络数据包的通信场景将成为性能瓶颈。同时在共享内存PIO机制下,CPU的核心工作变成执行IN/OUT指令,即从端口读取数据到寄存器,再从寄存器写入内存(或反之),每个字节/字的移动都需要CPU亲自执行指令。CPU时间几乎全部被数据搬运占用,无法有效处理真正的网络协议栈(IP、TCP解包)或用户应用程序。为了解决这个问题,真实的网卡都会使用DMA引擎来搬运数据。
![6c9cb866a89ab7801df48564152ef7fe.png]()
E2000 PCIe控制器实现了两个完全独立的 DMA 引擎模块,可以编程使用 DMA 直接传输或分散式DMA(SG-DMA)传输。每个 DMA 引擎,既支持从主存到 EP 设备搬运数据,也支持从 EP 设备到主存搬运数据;支持任意长度的数据传输(DMA 直接传输模式最大 4GB;SG DMA 模式每个描述符最大 16MB)。DMA控制器作为总线主控设备,可以主动发起对内存的读写操作,在不经过CPU寄存器的情况下,直接在外设(如网卡)和内存之间建立数据通道,这消除了不必要的中间步骤,效率更高。让CPU的角色从“搬运工”转变为“管理者”。它只负责初始化DMA传输(设置描述符)和处理传输完成后的中断,其余时间CPU可以去处理其他计算任务。
当引入DMA控制器后,BAR空间内不再需要CPU填充完整的skb数据,而只需写入待发送skb的内存物理地址和长度,理论上CPU占用率可以大幅下降。但是目前还没有“通知EP启动DMA引擎搬运”的方法,导致RC和EP驱动都需要轮询BAR空间来识别是否有新的SKB需要发送。所以还需要一种中断触发机制来解决这个问题,而在PCIe总线上一般使用MSI/MSI-X和Doorbell实现。
![a69dcb7c648f7075fa33688890bde35d.png]()
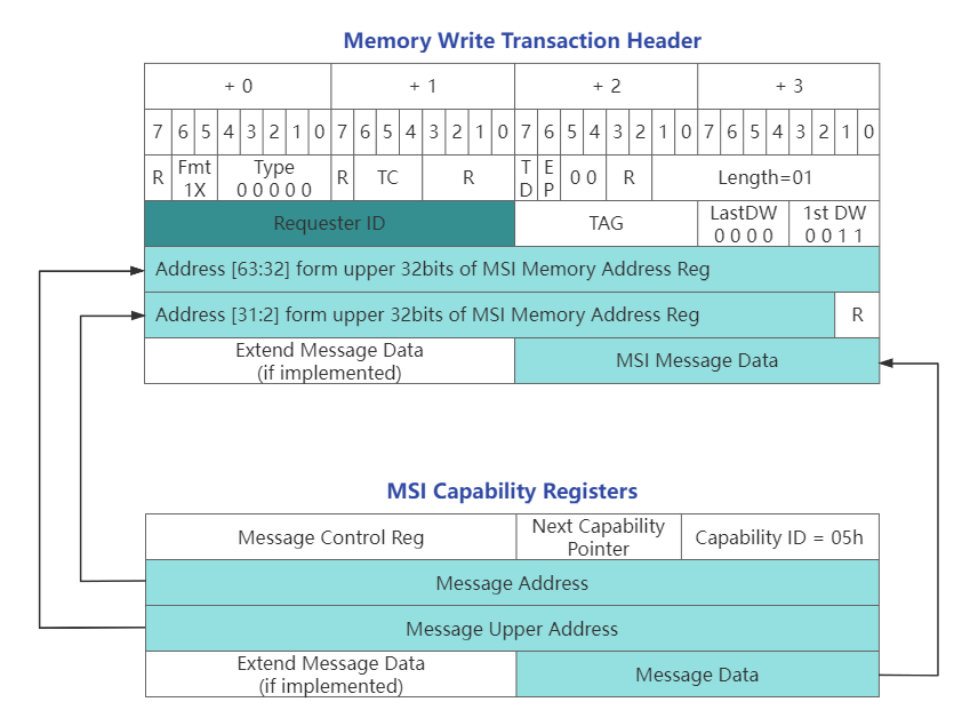
MSI(Message Signaled Interrupt)是一种EP主动触发RC产生中断的功能,系统软件在RC枚举PCIe总线时会扫描每个EP的PCIe空间,为支持MSI能力的EP设置Message Address Register,这个地址通常就是处理器中断控制器的地址。同时根据硬件平台当前可用的中断资源,分配相应数量的、连续的中断向量号给这个设备,并将起始向量号写入设备的 MessageData寄存器中。
当BMC需要触发Host MSI中断时,则会使用该地址发出上图所示Memory Write Transaction的TLP报文给Host,使其产生中断。随后Host内核基于报文的MSI中断向量号调用设备驱动注册的中断处理函数。从上述EP使RC产生中断的过程发现,MSI本质上是一种特殊的 Memory Write TLP报文。
Doorbell是一种在PCIe设备中广泛应用的软件编程模型或概念。它并非由PCIe基础规范直接定义一个叫做 “Doorbell” 的特定寄存器,而是被许多建立在PCIe之上的设备规范(如NVMe,SR-IOV虚拟化)所采用的一种通用机制。Doorbell通常是一个映射到主机内存空间(位于设备的BAR中)的寄存器。当Host想要通知设备开始处理任务时,它只需向这个Doorbell的地址执行写操作产生一个PCIe事务。E2000的PCIe控制器能够监控Bar1上的地址,支持将收到写请求转换为硬件中断,并可以读出Host写入的值从而执行特定业务,如从共享内存中读取DMA描述符并执行内存搬运动作,将SKB搬运到EP或RC。
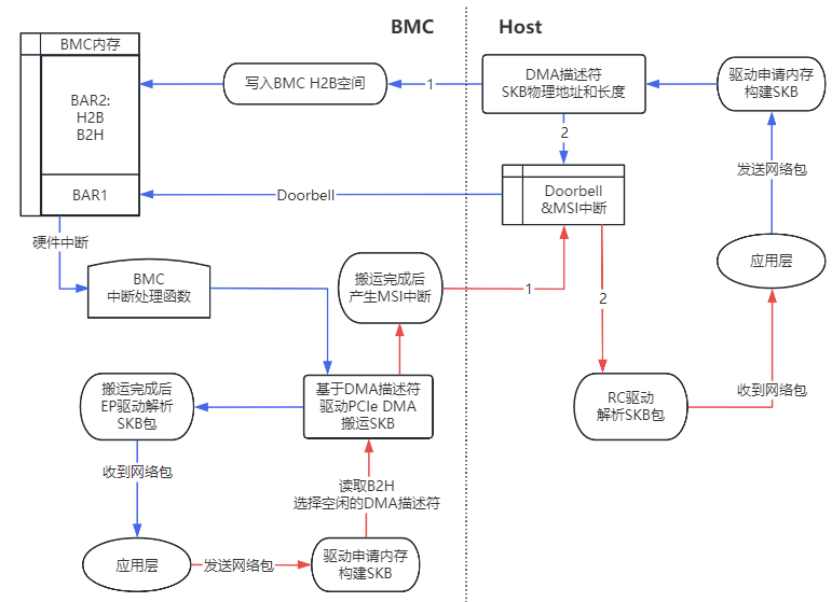
![3f27f3a07c291ac29cb0c20a6c84192a.png]()
虚拟网卡传输SKB参考通信流程如上图所示:
CPU应用层发送网络数据包,驱动构建SKB。
CPU获取SKB数据的物理地址和长度,并写入BAR空间DMA描述符。
CPU向EP发送Doorbell中断,通知“有新的包要发送”。
EP 进入中断处理函数,读取BAR空间描述符环,申请SKB长度的内存。
EP DMA控制器根据描述符中的地址,直接从主内存中的SKB数据区读取数据并写入申请的内存中。
EP DMA传输结束后,解析TCP报文发给EP的应用层。
本期内容着重为大家介绍了基于PCIE接口实现的应用场景--虚拟网卡,基于PCIe的虚拟网卡通过硬件加速、资源隔离和灵活扩展,成为云计算、HPC、边缘计算等场景的核心组件。除共享内存和虚拟网卡外,PCIe接口在存储加速(NVMe-oF over PCIe)、异构计算(GPU/FPGA直连)及安全计算(TEE可信执行环境)等多个领域也有广泛的应用,欢迎广大读者积极探索。
欢迎大家关注OurBMC社区,了解更多BMC技术干货。
OurBMC社区官方网站:
https://www.ourbmc.cn/