原文作者:Ilya Krutov - F5 NGINX 产品营销经理
原文链接: 快速指南:在 Kubernetes 上扩展 AI/ML 工作负载
原文来源: NGINX 中文官网
NGINX 唯一中文官方社区 ,尽在 nginx.org.cn
![]()
在 Kubernetes 上运行人工智能 (AI) 和机器学习 (ML) 模型训练与推理时,动态扩展是一个关键要素。除了需要高带宽存储和网络来接收数据以外,AI 模型训练还需要大量(且昂贵)的算力,其中大部分来自于 GPU 或其他专用处理器。即使利用预训练的模型,生产环境中的模型服务和微调等任务仍比大多数企业工作负载更耗费算力。
云原生 Kubernetes 专为实现快速扩展而设计,支持混合多云环境中的动态工作负载更灵活、更经济高效地使用资源。
本文介绍了在 Kubernetes 上扩展 AI/ML 工作负载的三种最常见方法,以便您在不同环境中实现最佳性能、成本节省及动态扩展。
在 Kubernetes 上扩展 AI/ML 工作负载的三种方法
Kubernetes 扩展工作负载的三种常用方法是 Horizontal Pod Autoscaler (HPA)、Vertical Pod Autoscaler (VPA) 和 Cluster Autoscaler。
以下是对这三种方法的详细介绍:
- HPA — 能够为应用添加实例或 Pod 副本,从而扩展其规模、容量和吞吐量。
- VPA — 能够调整 Pod 的资源大小,以提高其算力和内存容量。
- Cluster Autoscaler — 根据 Pod 当前的资源需求,自动增减 Kubernetes 集群中的节点数量。
每种方法在模型训练和推理方面都各有优势,您可通过下面的用例进行了解。
HPA 用例
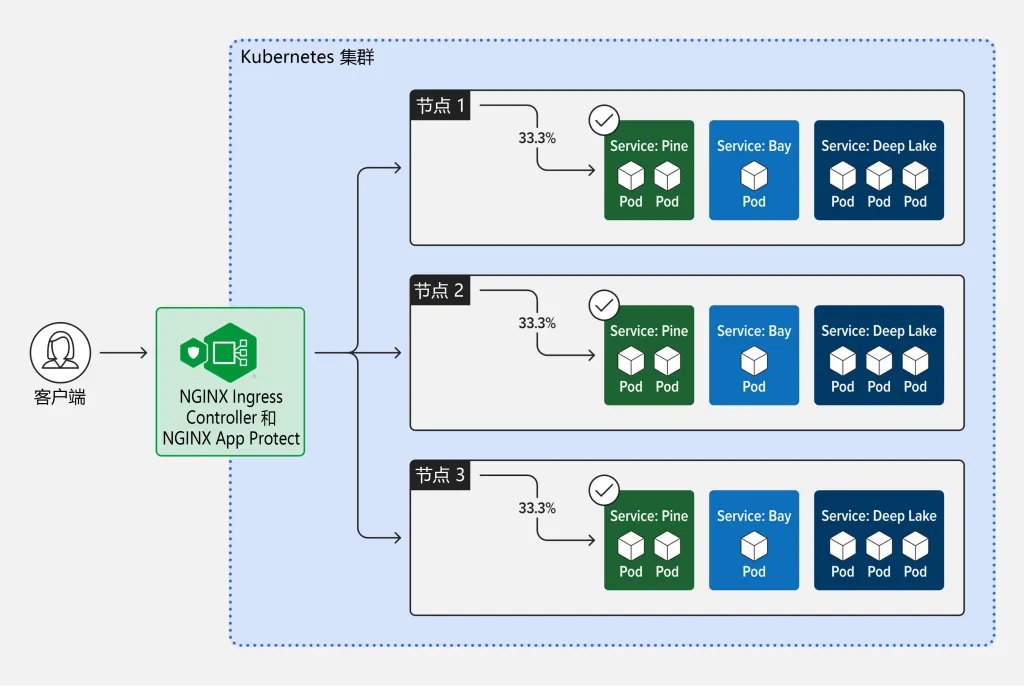
在许多情况下,分布式 AI 模型训练和推理工作负载可以横向扩展(即添加更多 Pod 以加快训练流程或请求处理速度)。这样一来,工作负载便可充分利用 HPA,根据 CPU 和内存使用量等指标,甚至是与工作负载相关的自定义和外部指标来扩展 Pod 的数量。在工作负载随时间变化的场景中,HPA 可以动态调整 Pod 的数量,以确保资源的最佳利用。
在 Kubernetes 中横向扩展 AI 工作负载还可进行负载均衡。为了确保最佳性能和及时处理请求,需要将传入请求分配给多个实例或 Pod。因此,Ingress controller(Ingress 控制器)是能够与 HPA 搭配使用的理想工具之一。
![]()
VPA 用例
AI 模型训练任务往往需要大量资源,包括大量 CPU、GPU 和内存资源。VPA 可以动态调整这些资源分配。这不仅有助于确保每个 Pod 拥有足够的资源来高效处理训练工作负载,而且还可确保所有指定 Pod 都有足够的算力来执行计算。此外,在大型模型的训练过程中,内存需求可能会出现大幅波动。VPA 可按需增加内存分配,从而有效防止内存不足问题。
虽然从技术上讲可以同时使用 HPA 和 VPA,但需要谨慎配置以避免冲突,因为它们可能会尝试以不同的方式(即横向和纵向)扩展相同的工作负载。必须明确界定每个自动扩展器,确保它们相互补充而不是相互冲突。一种新兴的方法是将两者用于不同用途 ,例如 HPA 用于根据工作负载跨多个 Pod 进行扩展,而 VPA 则用于在 HPA 设定的限制范围内微调每个 Pod 的资源分配。
Cluster Autoscaler 用例
Cluster Autoscaler 可帮助动态调整集群整体可用的计算、存储和网络基础设施资源池,以满足 AI/ML 工作负载的需求。通过根据当前需求调整集群中的节点数量,企业可以实现宏观水平的负载均衡。这对于确保实现最佳性能是必要的,因为 AI/ML 工作负载可能会意外需要大量计算资源。
HPA、VPA 和 Cluster Autoscaler 各有所长
总的来说,有三种方式可实现 Kubernetes 面向 AI 工作负载的自动扩展:
- HPA 可扩展 AI 模型,为需要支持波动请求速率的端点提供服务。
- VPA 能够优化 AI/ML 工作负载的资源分配,并确保每个 Pod 都有足够的资源进行高效处理,而不会出现过度配置的情况。
- Cluster Autoscaler 可向集群添加节点,以确保集群能够支持资源密集型 AI 作业,或者在计算需求较低时移除节点。
在管理 Kubernetes 中的 AI/ML 工作负载时,HPA、VPA 和 Cluster Autoscaler 相辅相成。Cluster Autoscaler 可确保拥有足够的节点来满足工作负载需求,HPA 能够在多个 Pod 之间高效分配工作负载,而 VPA 则可优化这些 Pod 的资源分配。它们共同为 Kubernetes 环境中的 AI/ML 应用提供了一款全面的扩展和资源管理解决方案。