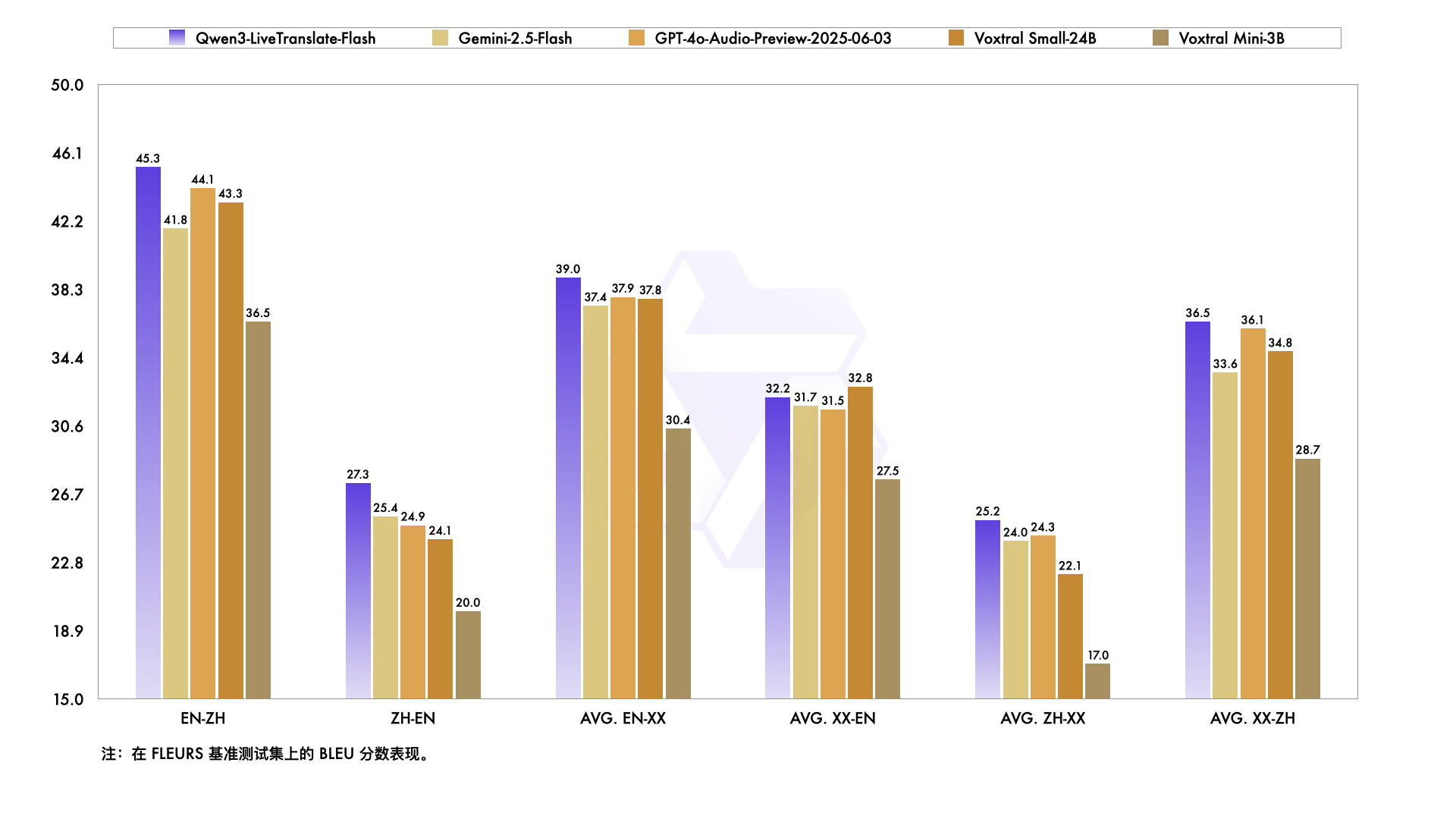
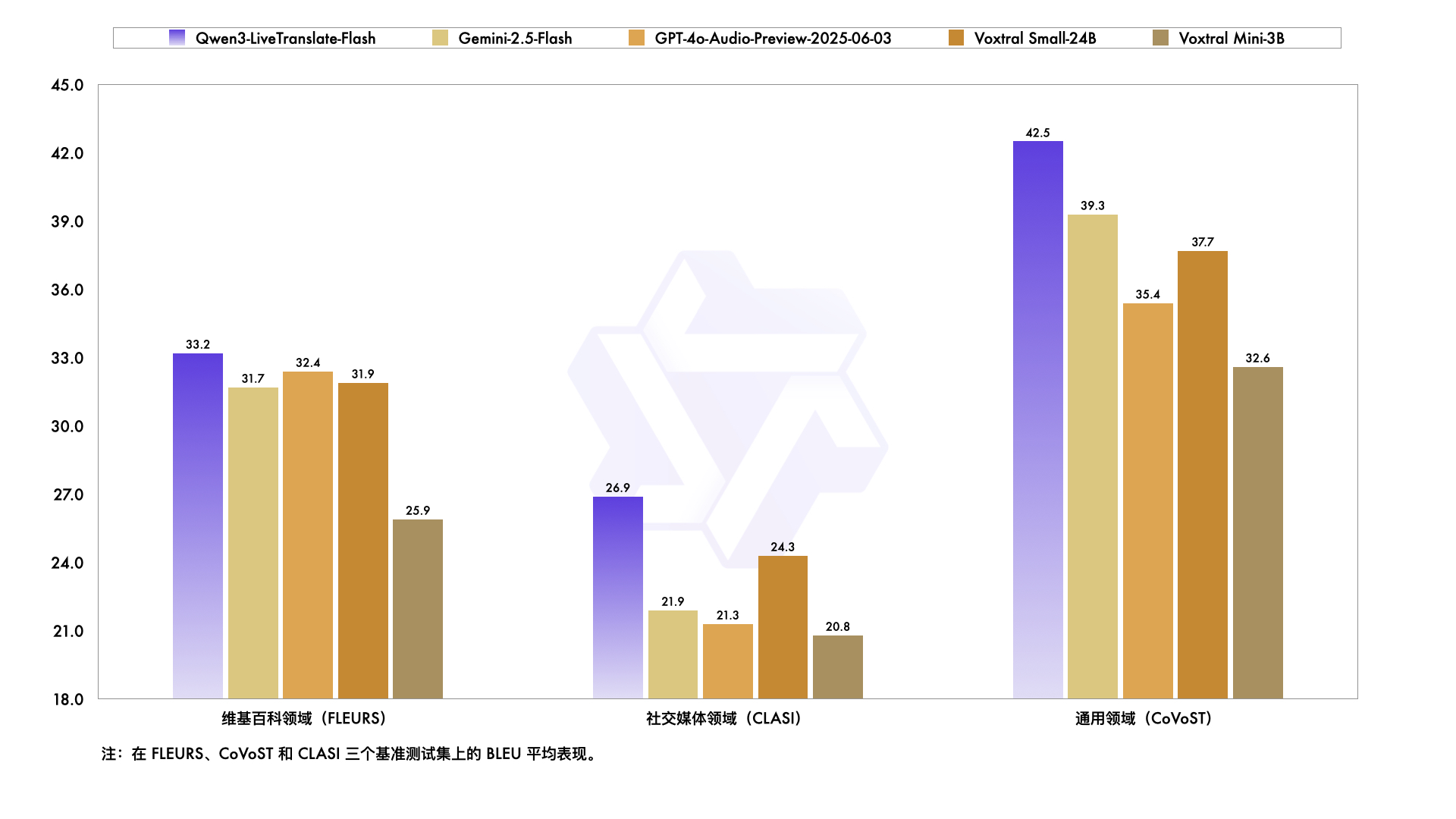
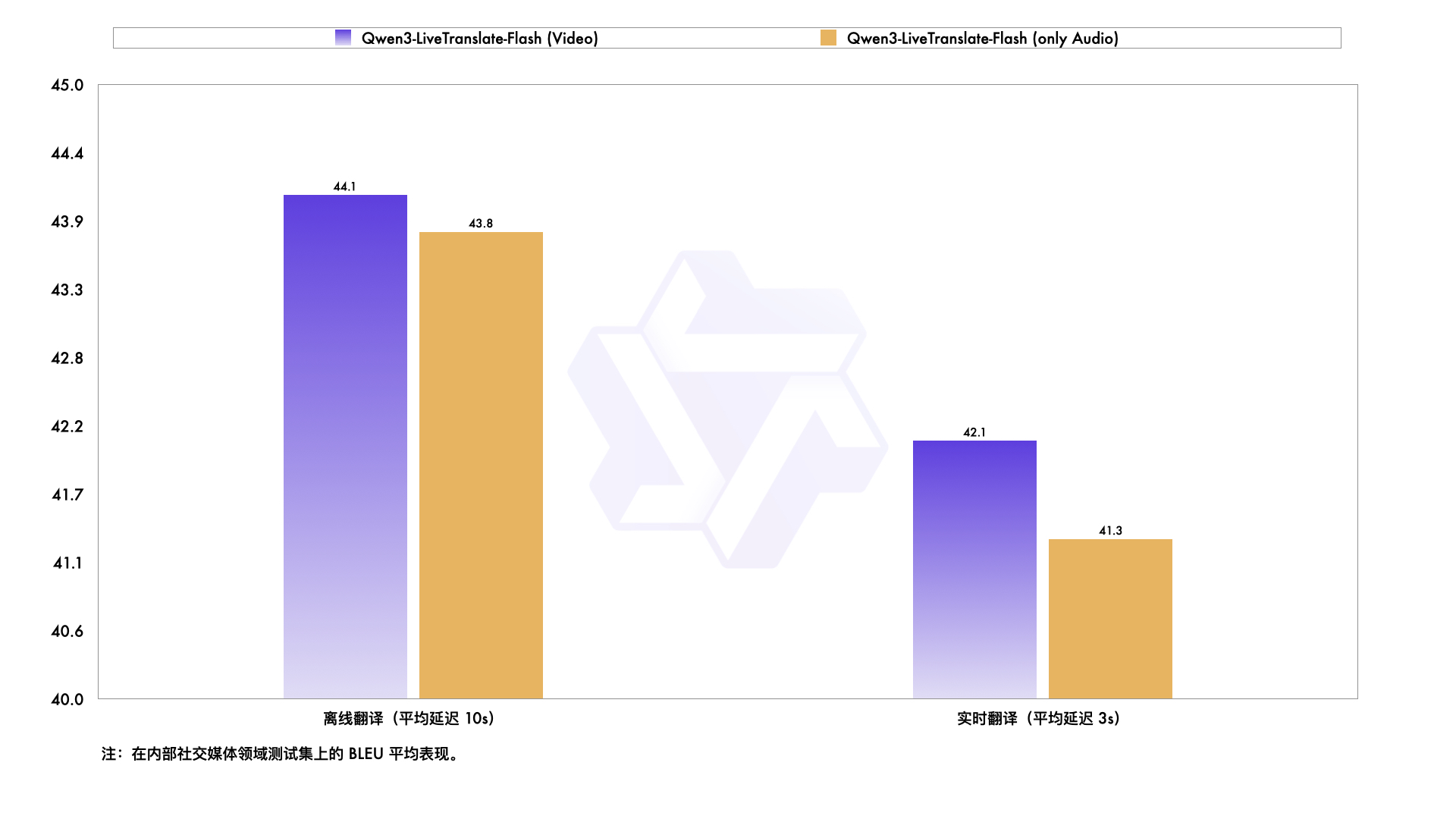

九科Agent上线6大新功能,助力企业自动化效率再升级
经过数月的实战探索,九科信息团队捕捉到企业在使用自动化工具时面临的界面理解难、执行易卡壳、任务管控散等核心痛点,全新推出bit-Agent的6大功能,从“界面认知、稳定执行、任务管理、生态扩展”四大维度实现体验优化,让自动化真正贴合业务场景,为企业降本增效注入新动力。 针对企业各部门业务系统的强个性化属性导致界面理解偏差的问题,bit-Agent新增“网页说明管理”功能,构建起内置的网页知识库。用户可对网页链接、页面模块进行人工标注与详细说明,Agent运行时能基于这些标注实现智能监管、导航引导和自动补全逻辑三大能力,既能依据业务规则规范员工操作,又能跨模块跳转,还能在批量任务中修正输入错误,彻底破解非标准化界面的认知难题。 任务执行中的意外中断常常拖累整体进度,“跳过错误步骤”功能为此赋予Agent容错能力。当遇到必要信息缺失、系统接口中断等问题且自动纠错无效时,Agent会自动跳过异常步骤优先推进其他环节,待人工介入后再处理问题环节,有效避免任务整体延误。 在复杂自动化场景中,模糊的任务指令易导致执行偏差,“设置参数”功能则解决了这一问题。用户创建任务时可对关键信息进行精细化参数配...