最新的 MLPerf Storage v2.0 测试结果显示,Alluxio 通过分布式缓存技术大幅加速了 AI 训练和 checkpointing 工作负载的 I/O 性能,在多种常见的由于 I/O 瓶颈导致 GPU 利用率不足的场景中,成功将 GPU 利用率提升至 99.57%。
虽然 GPU 本身算力极强,但其在 AI 训练中的实际效能取决于能否解决两个关键的 I/O 瓶颈问题:数据加载和Checkpointing(检查点保存)。我们曾在白皮书《Alluxio助力多GPU集群突破I/O瓶颈,高效释放AI算力》中提到,AI 训练基础设施的真正挑战并不在于算力,而在于如何避免因数据加载或模型 checkpointing 过慢而导致昂贵的 GPU 资源闲置。
I/O 加速至关重要,这是因为现代 AI 训练不但涉及在多个训练周期中反复读取海量数据集,还伴随着频繁保存百 GB 以上的模型状态。当 I/O 速度无法匹配 GPU 处理能力时,GPU 将处于空闲状态,不仅浪费每小时高达数千美元的计算资源,还会严重影响关键模型开发进度。因此,MLCommons 推出了 MLPerf Storage 基准测试,旨在以架构中立、有代表性、可复现的方式测量不同存储系统对机器学习(ML) 工作负载下的性能,此次发布是其最新的 v2.0 版本测试结果。
以下将探讨 Alluxio 的分布式缓存架构如何应对上述 I/O 挑战,分析其在最新版 MLPerf Storage v2.0 基准测试中的表现。
AI训练中的两大I/O瓶颈:数据加载和Checkpointing
模型数据加载: 指将训练数据集从存储加载到 GPU 服务器的 CPU 内存的过程。当 PyTorch DataLoader、TensorFlow 的 tf.data 等框架发出混合顺序/随机读取请求时,存储系统往往难以维持稳定吞吐。在多周期训练场景下,同一海量数据集需被反复加载,进一步加剧了对 I/O 的压力。传统存储架构常产生难以预测的延迟峰值,导致 GPU 处于"饥饿"状态。当数据加载速度跟不上 GPU 处理速度时,将造成昂贵的计算资源闲置,显著拉长训练周期并推高基础设施成本。
模型 Checkpointing: 训练代码定期将模型状态写入磁盘的过程。当训练过程中发生故障时,可重新加载已保存的模型状态并从该时间点恢复训练。在 checkpoint 完成模型状态文件写入之前,训练计算会被暂停。大多数训练工作负载在每次迭代(即对单批数据完成完整训练)后执行 checkpoint。随着迭代进行,模型状态文件可能增长至数百 GB 甚至更大规模。因此,如果 checkpoint 写入因 I/O 缓慢而受限,端到端训练时间也会受到延误。
解读MLPerf Storage v2.0 基准测试
MLCommons 发布的新版 MLPerf Storage v2.0 测试结果,凸显了存储性能在 AI 训练系统中的关键作用。
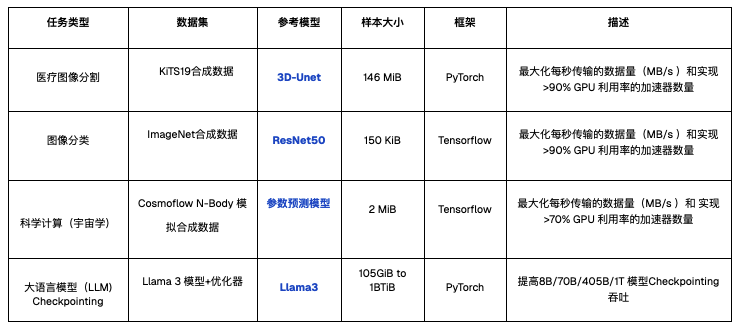
测试模拟的训练工作负载如下,涵盖多个行业的常见 AI 模型训练类型,这些模型的训练负载涵盖了针对大、小文件的顺序读、随机读等多样化的 I/O 模式,旨在充分检验系统在不同 I/O 压力下的真实表现。
![]()
相较于 v1.0 版本,v2.0 新增了 checkpointing 工作负载测试,重点评估训练过程中的备份与恢复速度,特别关注在可扩展系统上进行大语言模型(LLM)训练时的性能表现。
- 吞吐:在保持加速器利用率 >90%(3D-Unet/ResNet50)或 >70%(CosmoFlow)时的吞吐和延迟情况训练:读取带宽(GiB/s)Checkpointing:写入带宽(GiB/s)、写入时长(秒)、读取带宽(GiB/s)、读取时长(秒)
- 模拟加速器数量:测试期间运行的模拟 GPU 加速器数量。
Alluxio在MLPerf Storage v2.0 测试中的亮眼表现
在 MLPerf Storage v2.0 测试中,Alluxio 展现出优异的 AI 训练和 checkpointing 性能。
测试准备
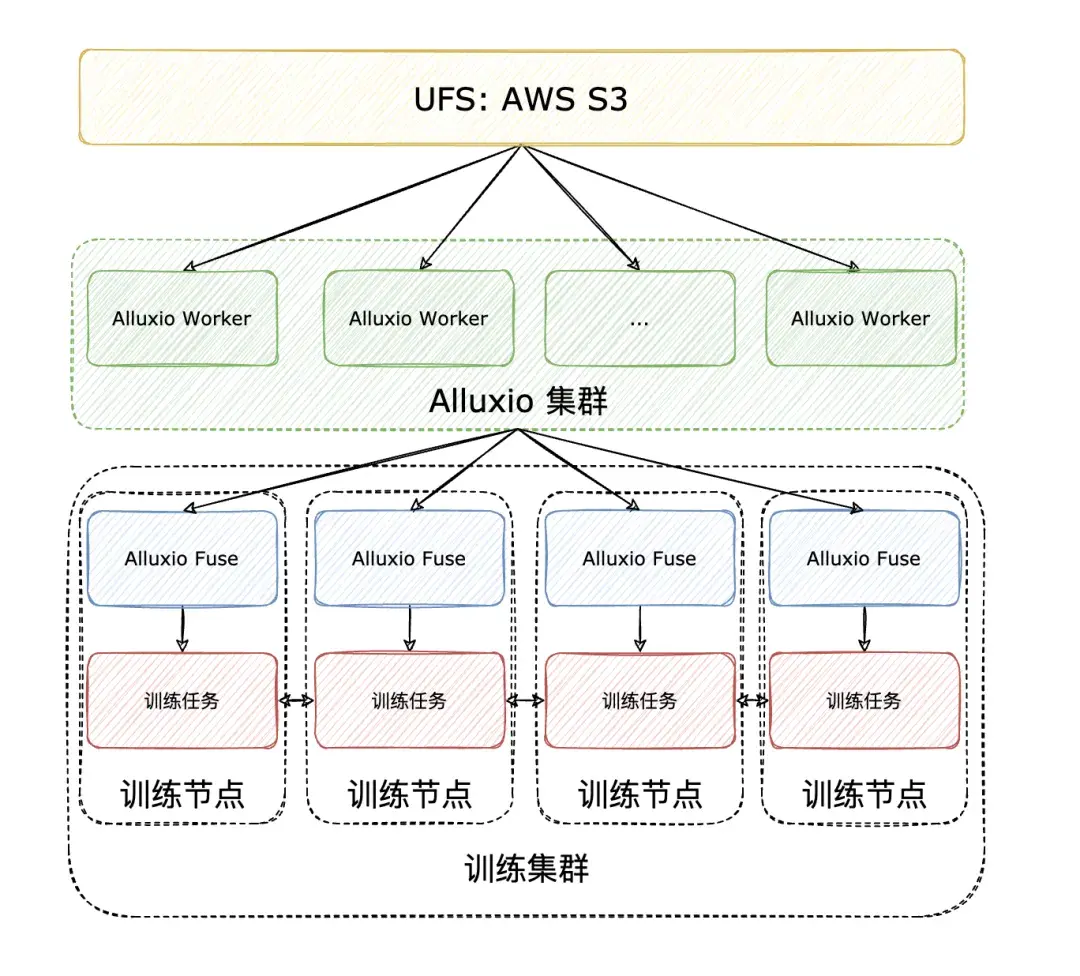
测试基于 Alluxio Enterprise AI 3.6 高性能数据平台,模型训练任务直接通过 Alluxio Fuse(POSIX 协议接口) 向 Alluxio 集群请求缓存数据进行训练,训练集群及 Alluxio 集群的拓扑分布如下:
![]()
高性价比AI训练:用通用硬件,实现极致模型性能
不同于其他厂商依赖昂贵的定制化硬件,Alluxio 本次直接选用 AWS 上的高性价比商用实例: ![]() 事实证明,即便在标准硬件环境下,Alluxio 依旧能为模型训练提供极致的加速性能。
事实证明,即便在标准硬件环境下,Alluxio 依旧能为模型训练提供极致的加速性能。
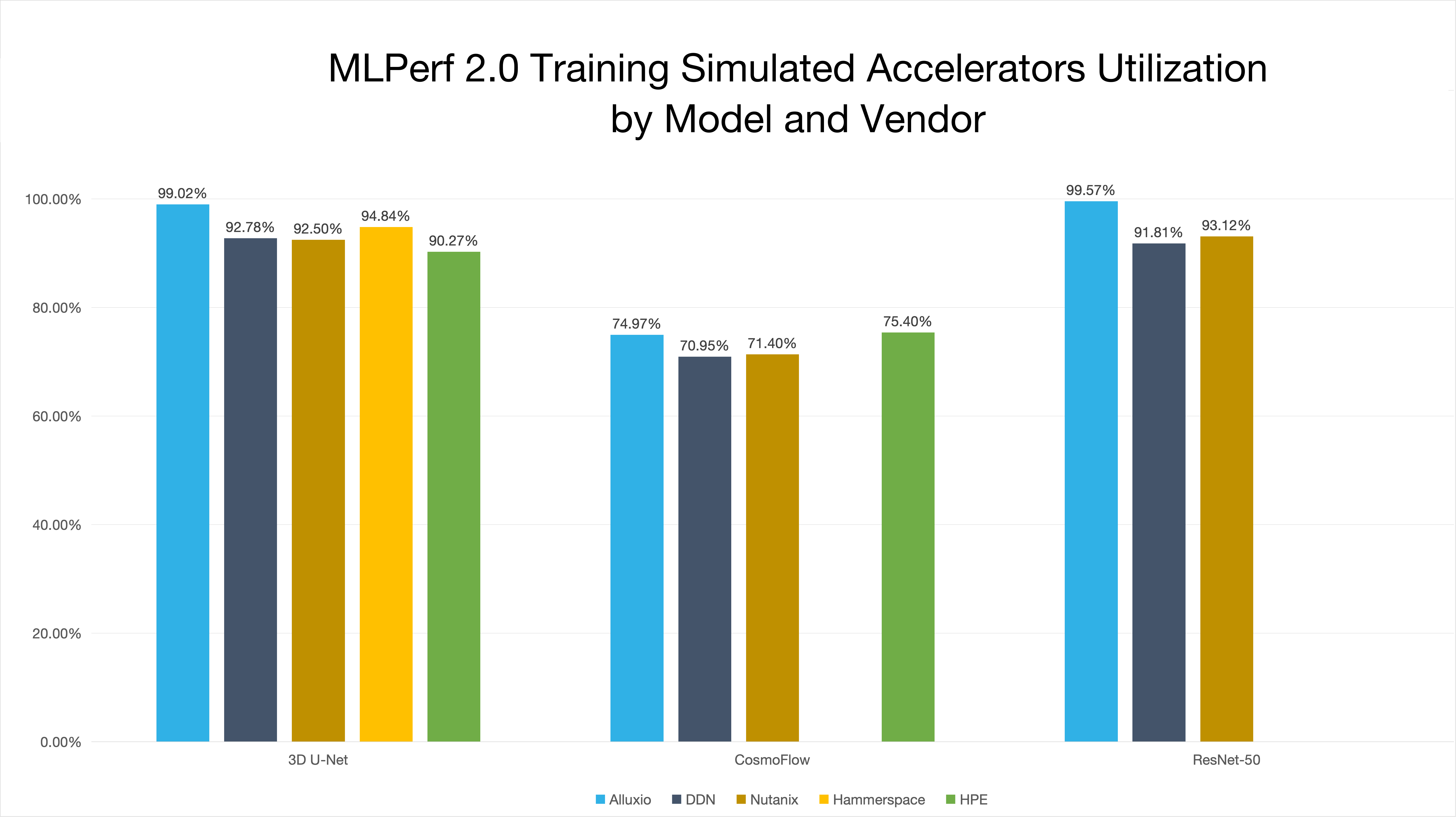
亮点1:加速器利用率高达 99.57%
加速器利用率是衡量数据系统效率的黄金标准,也是 MLPerf 基准测试的核心要求。在此关键指标上,Alluxio 表现卓越:
- 在 3D-Unet 和 ResNet50 模型测试中,加速器利用率双双突破 99%。
- 尤其在元数据密集型的 ResNet50 负载下,加速器利用率更是高达 99.57%。顶级的表现在全球知名厂商中脱颖而出,彰显了 Alluxio 高效的数据供给能力。
![]()
亮点2:性能随计算集群完美线性扩展
Alluxio 能将极致的单点性能无损地扩展至大规模集群,以下是在横向扩展能力测试中的具体表现:
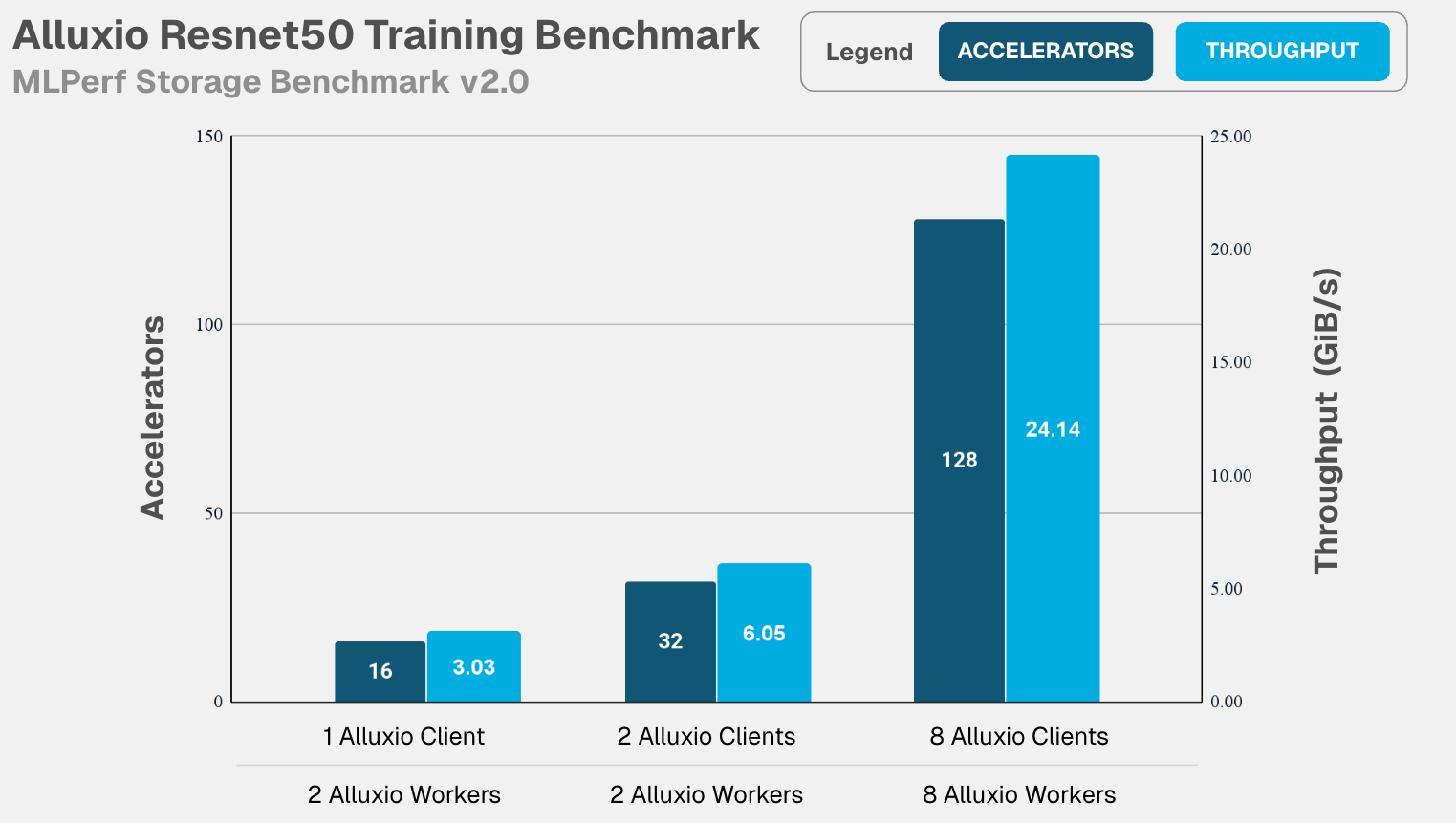
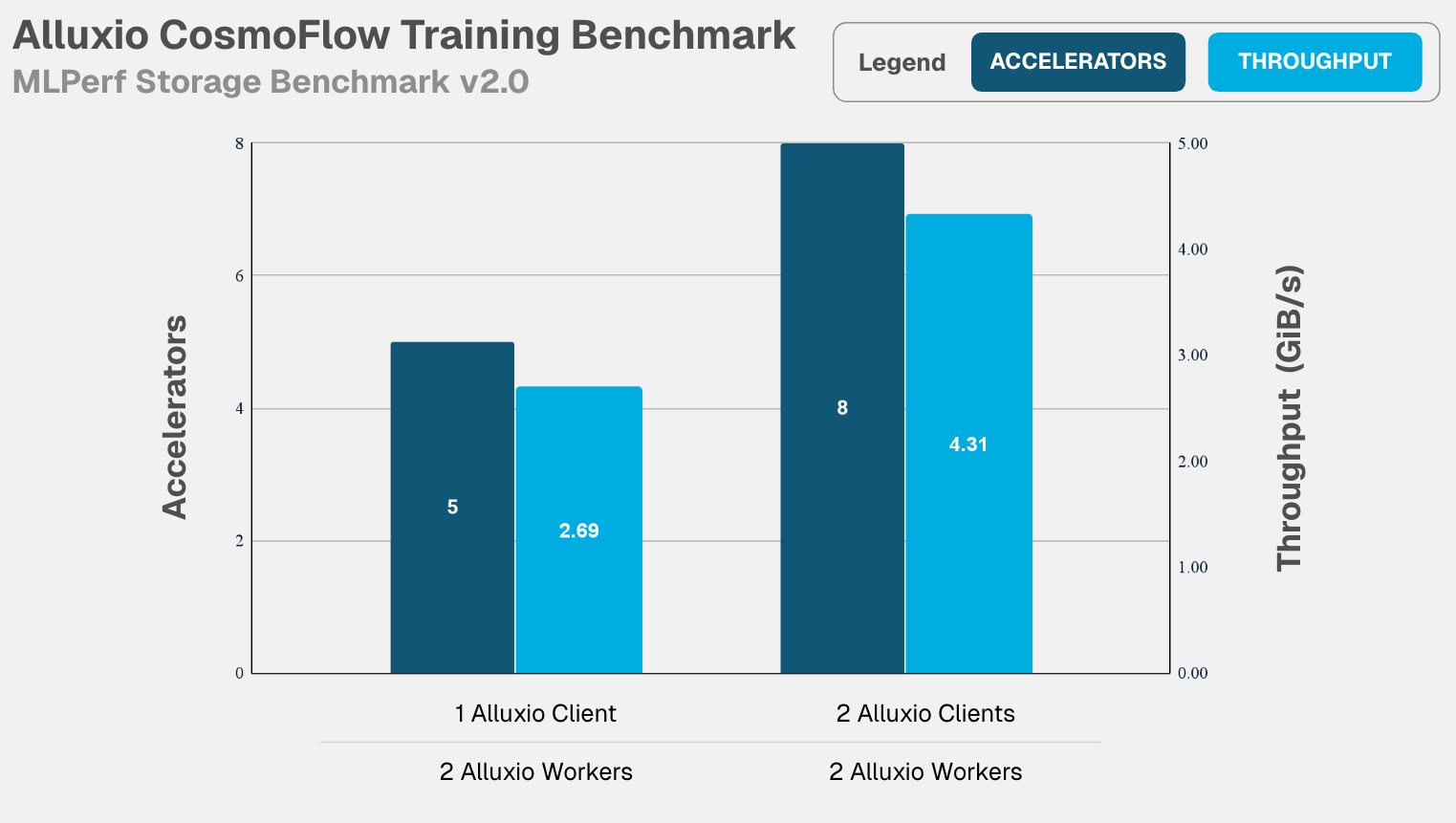
- ResNet50 :当计算集群从16个加速器(单机)扩展至128个加速器(8机)时,总带宽随之线性增长至 24.14 GiB/s ,同时加速器利用率始终保持在 99.57% 的近乎饱和状态,展现出完美的线性扩展能力。
![]()
![]()
与全球知名厂商的对比情况
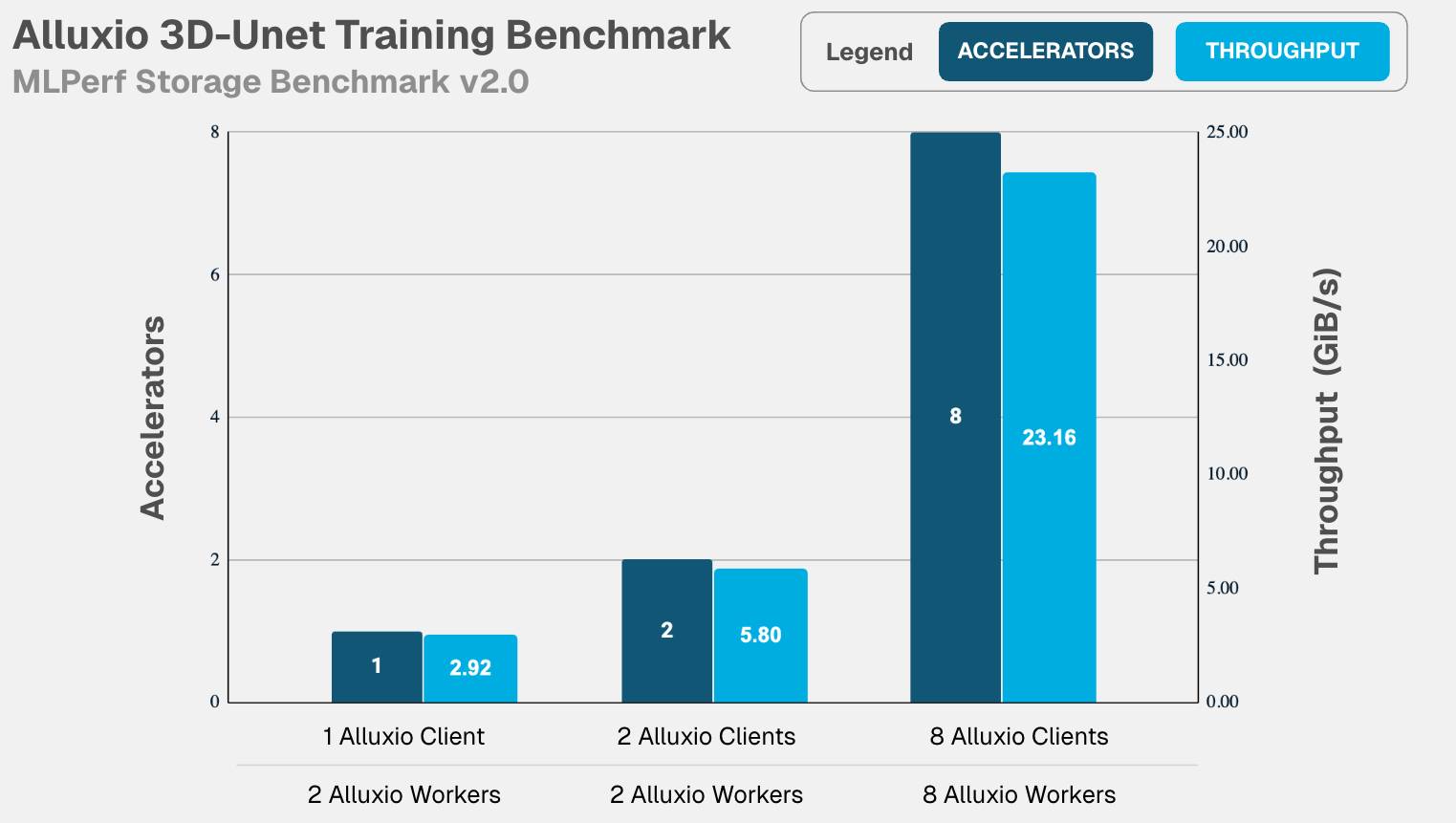
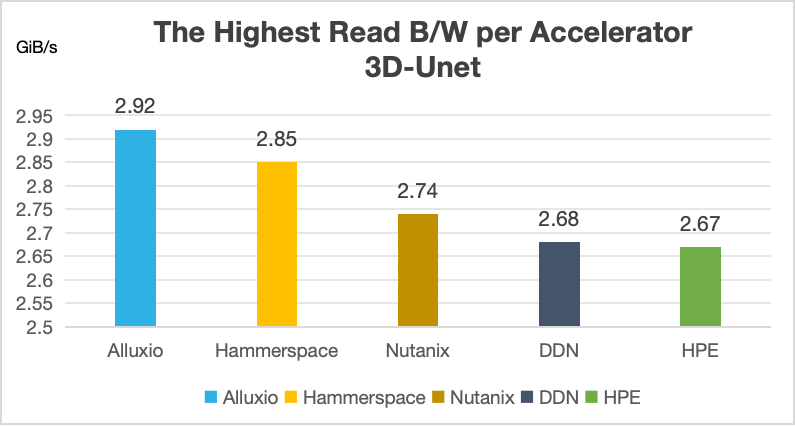
- 3D-Unet :在从单个加速器扩展至 8 个加速器的过程中,总带宽同样实现了线性增长,达到 23.16 GiB/s ,加速器利用率稳定维持在 99% 以上。
![]()
![]()
与全球知名厂商的对比情况
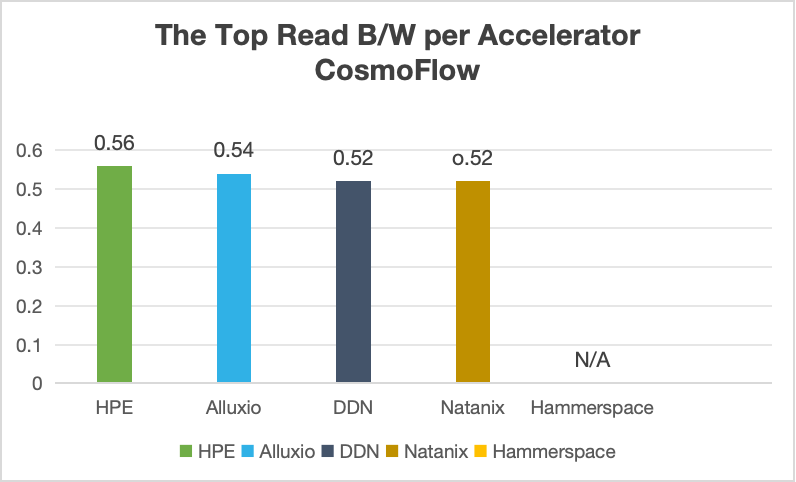
- CosmoFlow :在 8 加速器的配置下,系统性能表现优异,加速器利用率高达 74.97% ,显著超越了行业权威的 MLPerf 测试基准。
![]()
![]()
与全球知名厂商的对比情况
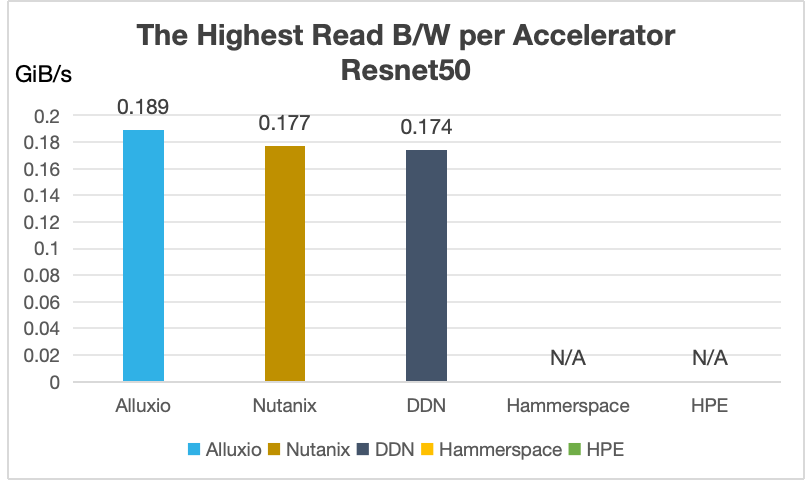
综合来看,无论面对何种模型或 I/O 模式,Alluxio 均能确保计算资源得到充分利用,其单卡吞吐性能表现全球领先。不仅如此,Alluxio 能够在标准商用硬件上满足任意规模 AI 训练的极致 I/O 需求,并提供卓越的集群扩展性。
亮点3:用平价硬件,打造高性能模型训练 checkpoint,显著降低成本
在模型训练中,Checkpoint 的写入速度是痛点,它直接决定了宝贵的计算资源需要暂停多久。Alluxio 解决方案,能够基于高性价比的云主机(如AWS i3en.12xlarge),构建性能媲美本地物理磁盘的 Checkpoint 系统。
-
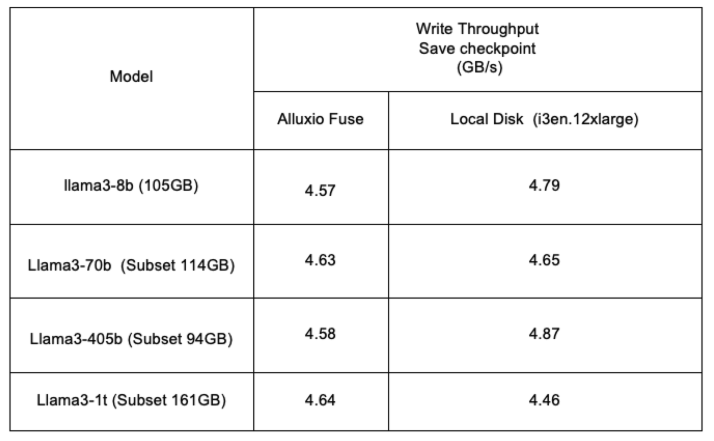
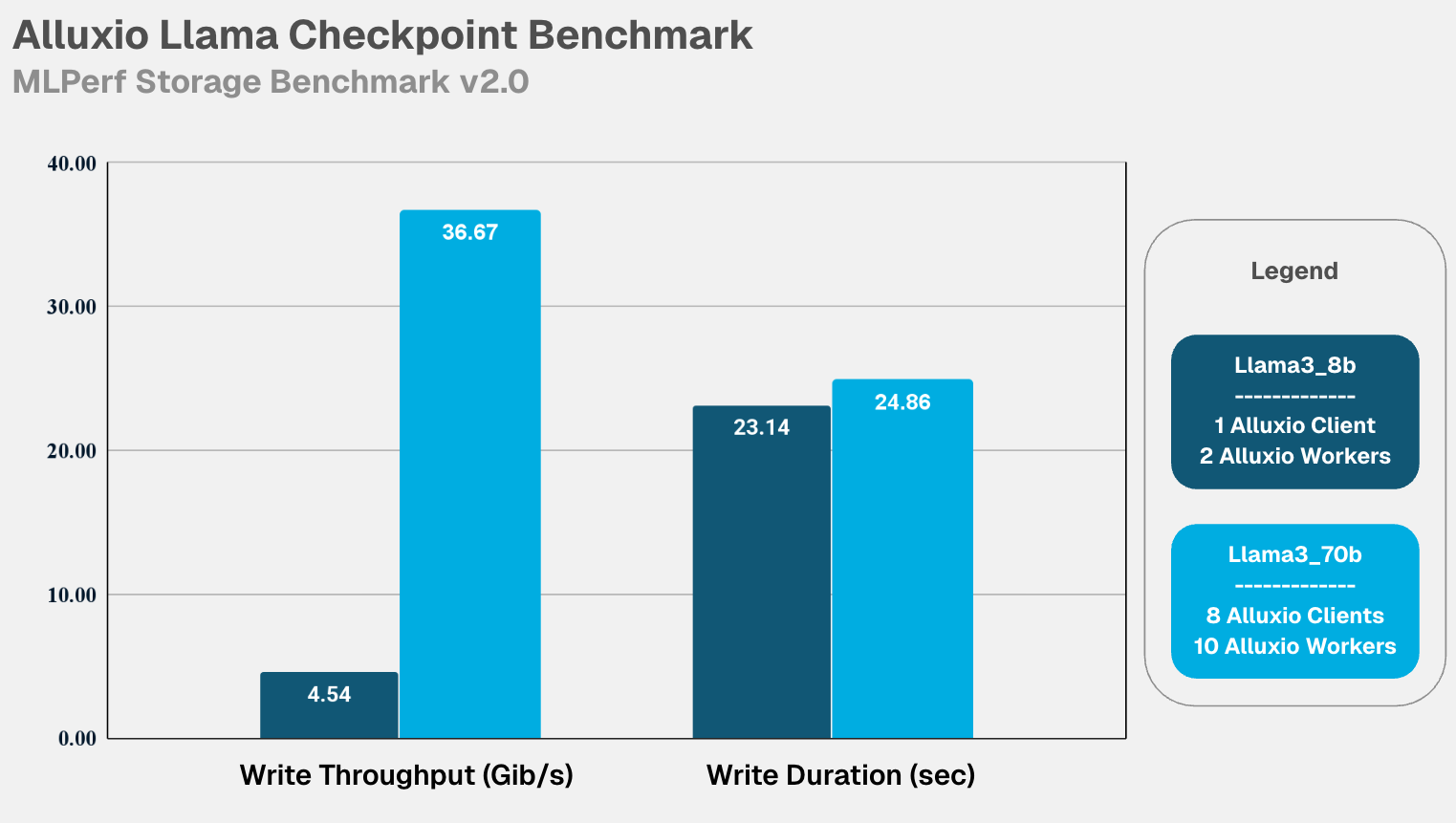
单节点性能:榨干硬件潜力 。如下表所示,在单台机器(8个加速器)上,Alluxio 的写入吞吐量与本地盘几乎无异,完全释放了存储节点的硬件性能。 ![]()
-
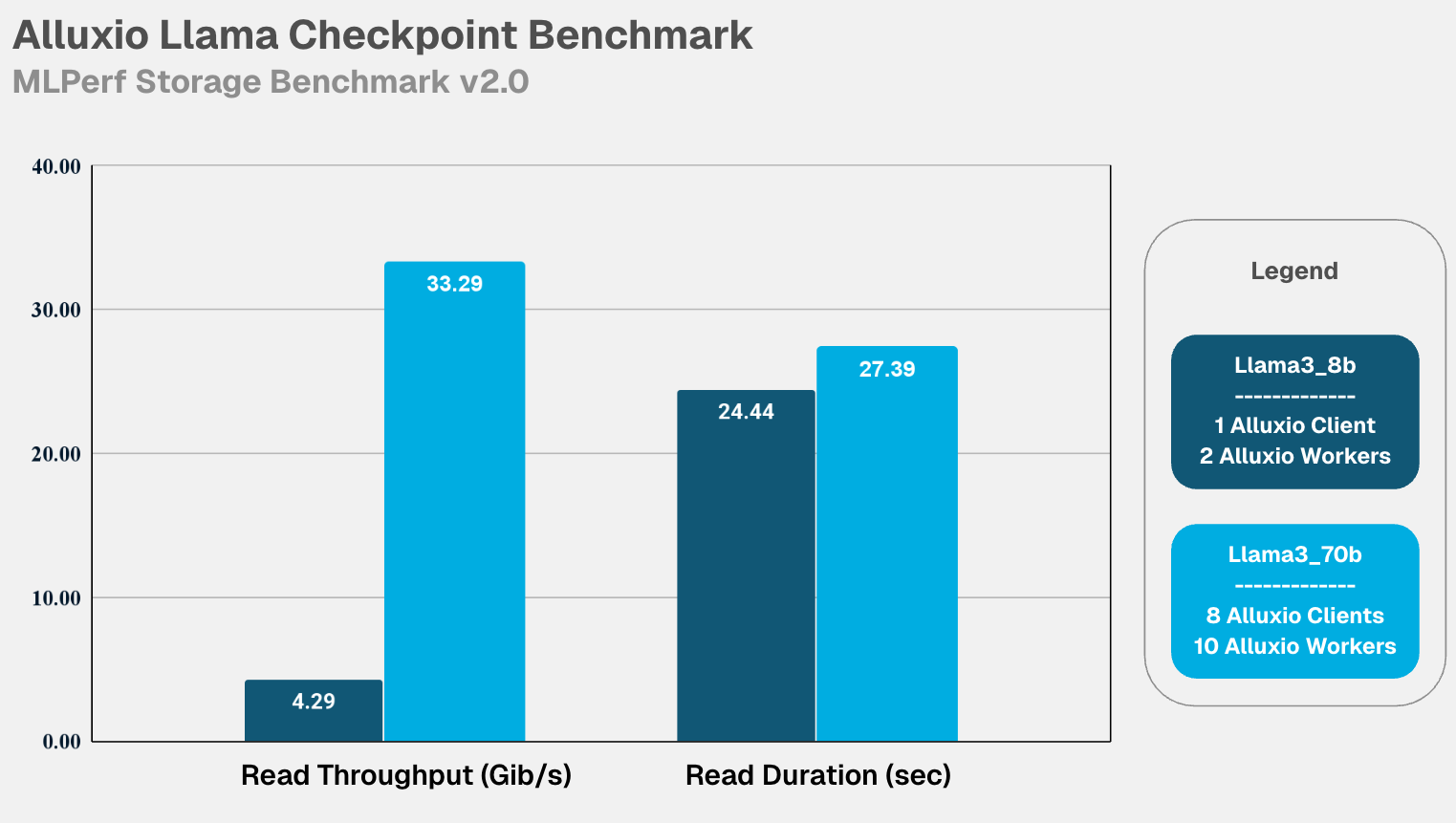
多节点性能:实现完美线性扩展 。当集群从单节点(8卡)扩展至 8 节点(64卡)时,性能随节点数线性增长。在 Llama3-70b 的 64 卡训练中,写入带宽飙升至 36.67 GiB/s ,近乎是单节点性能(约4.6 GiB/s)的 8 倍,再次展现了卓越的横向扩展能力。 ![]()
![]()
-
核心价值: Alluxio方案证明无需采购昂贵的专用存储设备,仅通过普通低成本的机型,就能轻松构建一个性能随规模线性扩展的高性能 Checkpoint 系统,从而大幅节省训练成本。
Alluxio表现出的核心优势
优势1:分布式缓存而非存储
Alluxio 在 MLPerf Storage v2.0 基准测试中的卓越表现,源于其在架构上的根本差异:它并非传统存储系统,而是作为分布式缓存层运行,极具创新且巧妙地部署在计算与存储之间以消除 I/O 瓶颈。该架构利用部署在 GPU 集群附近的高速 NVMe SSD,创造出传统网络附加存储(NAS)难以比拟的性能倍增效应。
Alluxio 消除 I/O 瓶颈的机制:
- 数据加载(读取优化):Alluxio 通过将训练数据缓存到 GPU 集群闲置的 NVMe SSD 上,加速数据加载过程。这种方式能够实现高吞吐数据访问,在加载数据时保持 GPU 的高效利用。
- Checkpointing(读写优化):Alluxio 通过缓存机制加快 checkpoint 文件的保存与恢复,实现快速写入和低延迟读取。通过将数据缓存到本地 NVMe SSD,Alluxio 不仅支持快速写入,还能减少对远程存储的访问延迟,确保 checkpointing 高效可靠。
优势2:性价比之王
与行业内部分厂商依赖定制化高端机型或专用存储设备才能实现高性能的方案不同,Alluxio 的核心优势不仅在于卓越的 I/O 加速能力,还在于其对硬件环境的普适性与成本友好性。
在 AI 训练基础设施成本中,硬件采购往往占据重要比例。传统方案为追求存储性能,常需搭配昂贵的专用服务器、高端存储阵列或定制化硬件配置,这不仅推高了初期投入,还增加了后期维护与扩展的复杂性。而 Alluxio 的分布式缓存架构彻底打破了这一局限 ------ 它无需依赖特定品牌或高端型号的硬件,能够在任意廉价的通用服务器(如普通云主机、标准 x86 服务器)上部署,通过对本地 NVMe SSD 等常规硬件资源的高效调度,即可搭建高性能的 AI 数据通道。
结语
人工智能的未来,建立在数据之上。然而,数据 I/O 的效率,长期以来一直是束缚AI发展的无形枷锁。MLPerf Storage v2.0的测试结果,标志着一个重要的行业信号:我们已经拥有打破这一枷锁的成熟工具。
Alluxio 此次的表现,展示了一种全新的解题思路------不再是在存储本身上无限投入,而是在计算和存储之间,构建一个轻量、高效且能随计算资源无限扩展的"数据高速公路"。它让数据能够以前所未有的速度流向 GPU,将硬件利用率推向极致,并最终将训练周期从"周"缩短至"天"。
在基础模型(Foundation Models)日益庞大、AI 应用无处不在的今天,Alluxio 所代表的分布式缓存技术,已成为 AI 基础设施现代化的必然选择。它赋能的不仅是当下的 AI 训练,更是下一代人工智能创新浪潮的基石。
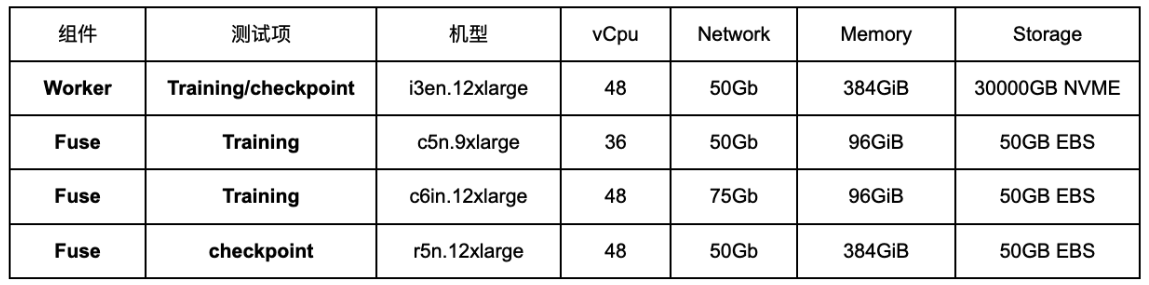 事实证明,即便在标准硬件环境下,Alluxio 依旧能为模型训练提供极致的加速性能。
事实证明,即便在标准硬件环境下,Alluxio 依旧能为模型训练提供极致的加速性能。