AIBrix 0.4.0 版本现已发布,这个版本解决了编排和路由方面的关键瓶颈,包括 Prefill/Decode(P/D)分离以及大规模 Expert 并行(EP)在编排和路由上的瓶颈,优化了 AIBrix KV 缓存 V1 连接器,实现了引擎的 KV 事件同步 以及 多引擎支持。
v0.4.0 亮点功能
1. StormService:用于 P/D 分离的编排与感知路由支持
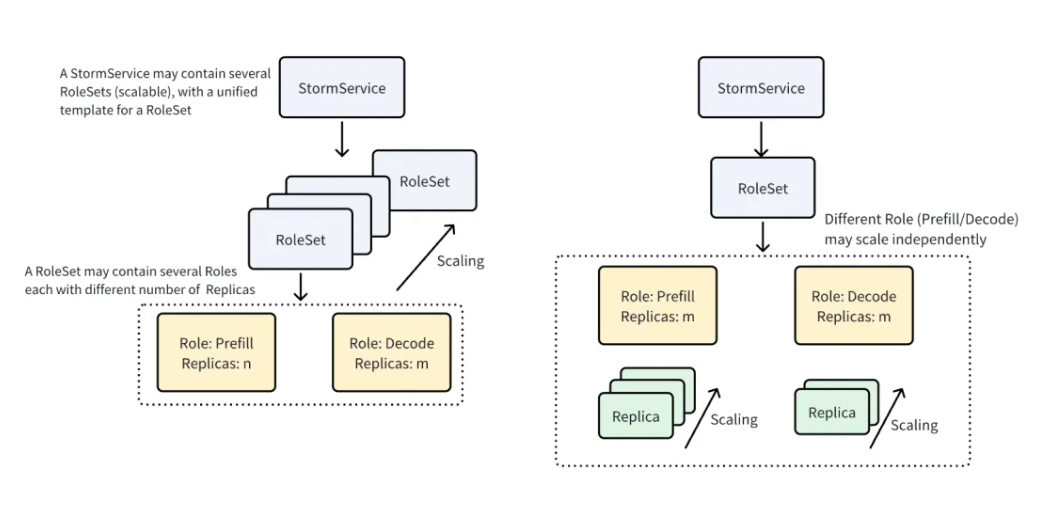
P/D 分离是一种架构,其中预填充 Prefill 和解码 Decode 阶段在不同的 GPU 节点上运行,以提高资源利用率和吞吐量。为了支持 P/D 分离,AIBrix 定义了一个名为 StormService 的自定义资源,用于管理 P/D 分离架构中推理容器的生命周期。StormService 使用三层结构:顶层的 StormService 对象封装服务并跟踪副本数量;中间层的 RoleSet 表示一组角色(如预填充或解码);底层的 Pod 执行实际的推理任务。这种分层设计允许更新从 StormService 向下传播,并且每层的协调器根据需要同步状态,从而实现 P/D 分离服务的原子性扩缩容和滚动更新。
![]()
StormService 支持两种部署模式——副本模式和池化模式,以适应不同的 P/D 分离场景。对于更新,StormService 提供两种策略:副本模式支持滚动更新,即逐步用新的 RoleSet 替换旧的;池化模式支持原地更新,可直接更新现有的 RoleSet,且在此过程中不消耗额外的 GPU。为了在多角色部署中进一步控制升级行为,StormService 还支持顺序、并行和交错滚动策略。
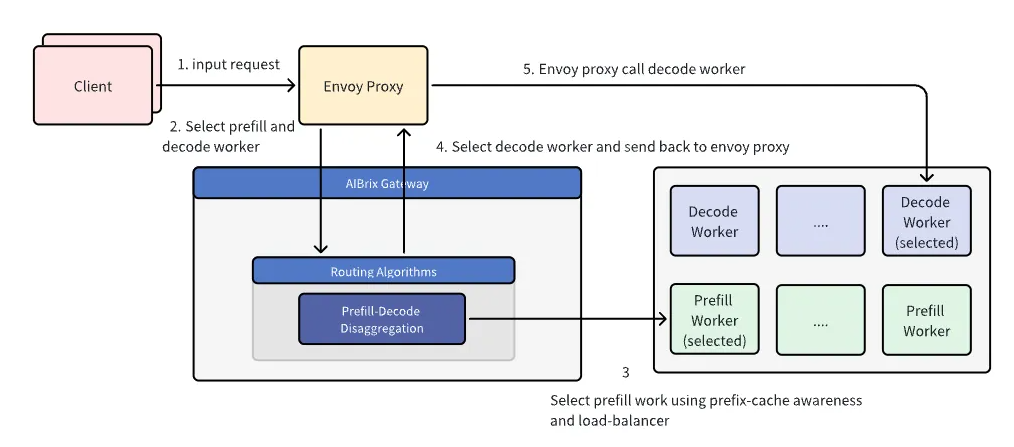
在基础设施层面实现 P/D 分离后,路由成为确保运行时高效处理请求的下一个关键步骤。在 P/D 分离路由工作流中,AIBrix 网关插件首先选择一个预填充工作节点。此选择使用前缀缓存感知算法,以优化缓存命中率并确保在可用工作节点之间实现有效负载均衡。一旦选择了预填充工作节点,插件就会将预填充请求直接发送给该节点。
预填充请求的处理取决于底层的推理引擎:
![]()
预填充步骤完成后,选择一个解码工作节点。在当前实现中,解码工作节点是随机选择的。然而,未来的改进旨在通过考虑 KV 缓存传输延迟和工作节点负载等因素来优化此选择,以提高效率。然后,所选解码工作节点的连接详细信息会返回给 Envoy Proxy,代理会相应地转发解码请求。从 Envoy Proxy 到解码工作节点的后续传播和响应处理机制保持不变。此工作流的关键区别在于对预填充请求的特殊处理,即在进入解码之前引入了一个专门的步骤来单独路由和处理预填充请求。
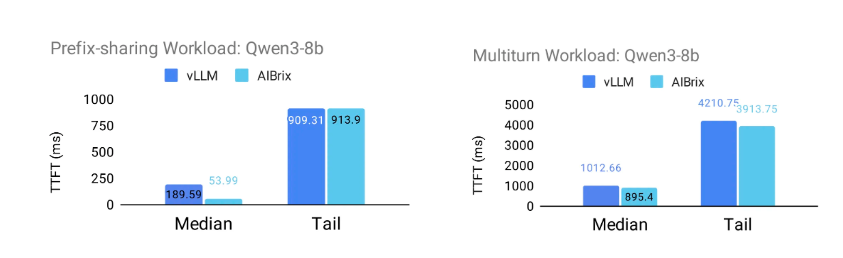
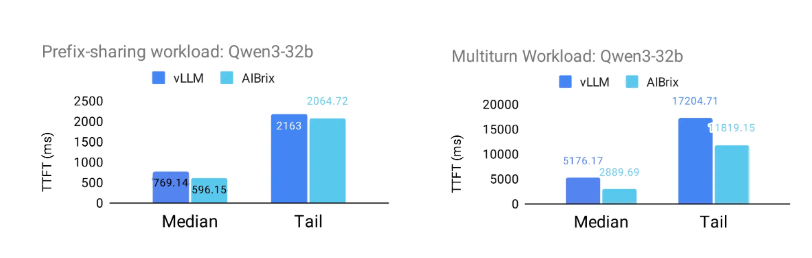
以下图表展示了 AIBrix 的 P/D 分离感知路由支持带来的前缀感知路由的优势。为了评估此功能的影响,项目团队设计了两个受现实场景启发的工作负载。前缀共享工作负载模拟共享几个长公共前缀的请求,模仿具有显著前缀重叠的场景。下面指定了所使用的具体共享模式。多轮对话工作负载模拟多轮对话,平均请求长度为 2000 个令牌(标准差:500),平均 每次对话 3.55 轮。
实验在 NVIDIA H20 GPU 上进行,采用两种配置:
(1)使用Qwen/Qwen3 - 8b模型的 2P1D 配置;
(2)使用 Qwen/Qwen3 - 32b模型并采用张量并行(TP = 2)的 2P2D 配置。
结果表明,当 AIBrix 与 vLLM 集成时,在两个工作负载中,首次令牌生成时间(TTFT)的中位数和尾延迟都有显著改善。对于 Qwen/Qwen3 - 8b模型,AIBrix 使 TTFT 中位数最多提高 72%,第 95 百分位的尾延迟 TTFT 最多提高** 7%**。对于更大的 Qwen/Qwen3 - 32b模型,AIBrix 使 TTFT 中位数最多提高 44%,尾延迟 TTFT 最多提高 31%。
![]()
Qwen3-8b
![]()
Qwen3-32b
由于实例数量有限且流量饱和度高,在此设置中尾部延迟的改善不太明显。如果配置更多实例,AIBrix的优势将更加显著,特别是在突发或高并发工作负载的情况下。
注意
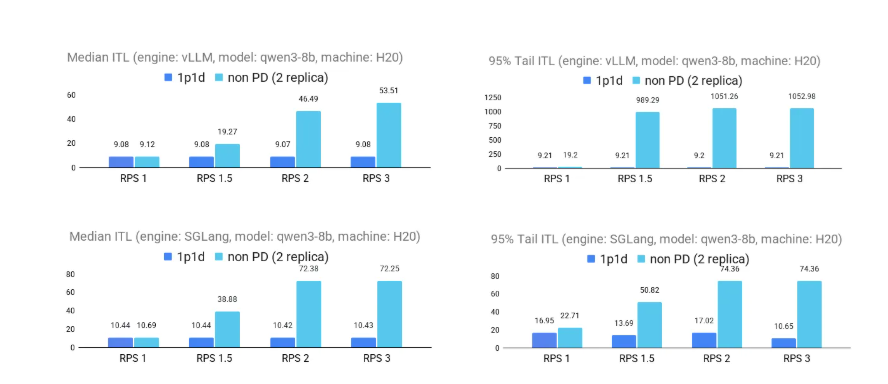
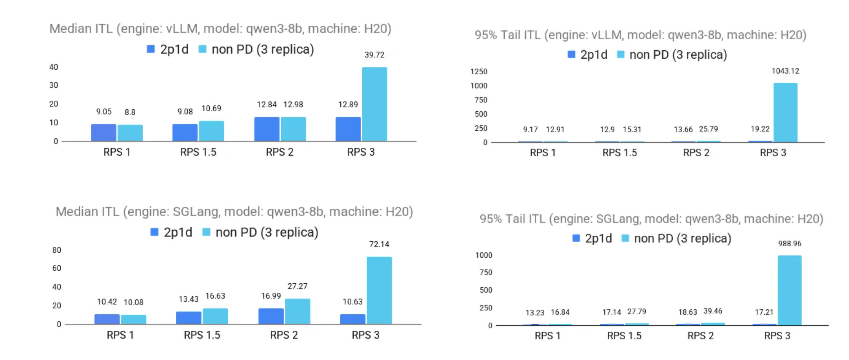
以下图表展示了在请求负载(RPS)增加的情况下,P/D 分离在降低推理时间延迟(ITL)方面的显著优势。在 1p1d 和 2p1d 两种配置中,P/D 分离始终优于非 P/D 分离基线,在 vLLM 和 SGLang 引擎中都保持较低的延迟。在较高负载下,性能提升尤为明显:在 2p1d 设置中,第 95 百分位的尾延迟 ITL 最多提高 2 倍;在 1p1d 设置中,两种引擎的中位数 ITL 最多提高 5 倍以上。
![]()
1p1d 场景
![]()
2p1d场景
2.大规模专家并行支持
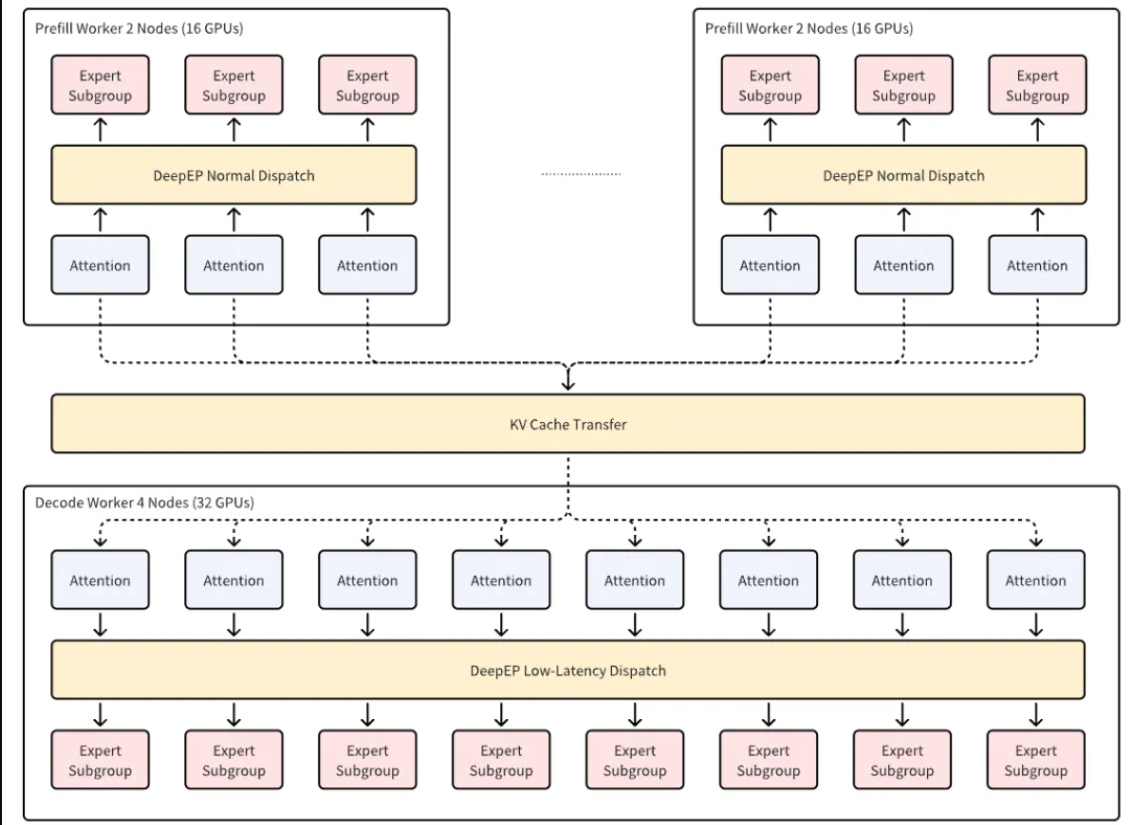
除了 P/D 分离架构,AIBrix v0.4.0 还增强了对专家并行(EP)的支持。对于像 DeepSeek 这样的混合专家(MoE)模型,EP 显著降低了与稀疏前馈网络(FFN)相关的内存开销。vLLM 和 SGLang 社区通过实现 EP 机制并集成 DeepEP 和 DeepGemm 等高性能算子库,为可扩展的专家并行奠定了坚实的基础。这些能力已经在包括 H100 和 GB200 在内的前沿硬件上得到验证,为持续创新建立了强大的技术基础。
![]()
在这个版本中,AIBrix 专注于大规模 EP 的生产级部署。在 8 台配备 64 个 H20 GPU 的服务器上部署了 DeepSeek,采用 2P1D 配置(两个 TP16 预填充工作节点和一个 TP32 解码工作节点)。在 5 秒 TTFT 和 50 毫秒 TPOT 的约束下,输入/输出令牌为 3.5k/1.5k 时,每个 H20 节点在预填充阶段的吞吐量为 9.0k TPS,在解码阶段为 3.2k TPS,与 TP16 基线相比,预填充吞吐量提高了 30%,解码吞吐量提高了 3.8 倍。
这些结果凸显了 AIBrix 在生产环境中对大规模专家并行(EP)的强大编排能力。除了原始性能,AIBrix 还提供生产级的部署机制,包括版本控制部署、优雅升级和分布式 EP 工作负载的容错恢复。借助 AIBrix StormService,预填充和解码单元可以灵活地部署在多个节点上,同时内置的路由器可以智能地调度请求,以最大限度地提高 GPU 利用率和系统吞吐量。这种架构即使在动态流量模式下也能实现稳定、高吞吐量的推理。
火山引擎已正式将 AIBrix 集成至其Serving Kit,为大规模专家并行(EP)部署提供生产级服务。
3.KV 缓存 v1 连接器
在 v0.3.0 版本开源了KV 缓存卸载框架,并将其与 vLLM v0.8.5(V0 架构)集成。现在,在 v0.4.0 版本中进一步优化了该框架,并将其集成到 vLLM v0.9.1(V1 架构)中,提高了兼容性和性能。
最新版本带来了几个关键特性和改进:
- 完全支持 vLLM v0.9.1 的 V0 和 V1 架构
- 通过新的性能分析功能和火焰图可视化增强了可观测性
- 将框架开销降低到 3% 以下(在 TP = 8 的 70B 模型上测量)
- 为支持 RDMA 的环境提供网络自动配置功能
- 引入新的 AIBrix KV 缓存 L2 连接器,用于 PrisDB 和 EIC,这是字节跳动为大语言模型推理工作负载优化的低延迟、可扩展多层缓存架构的键值存储。
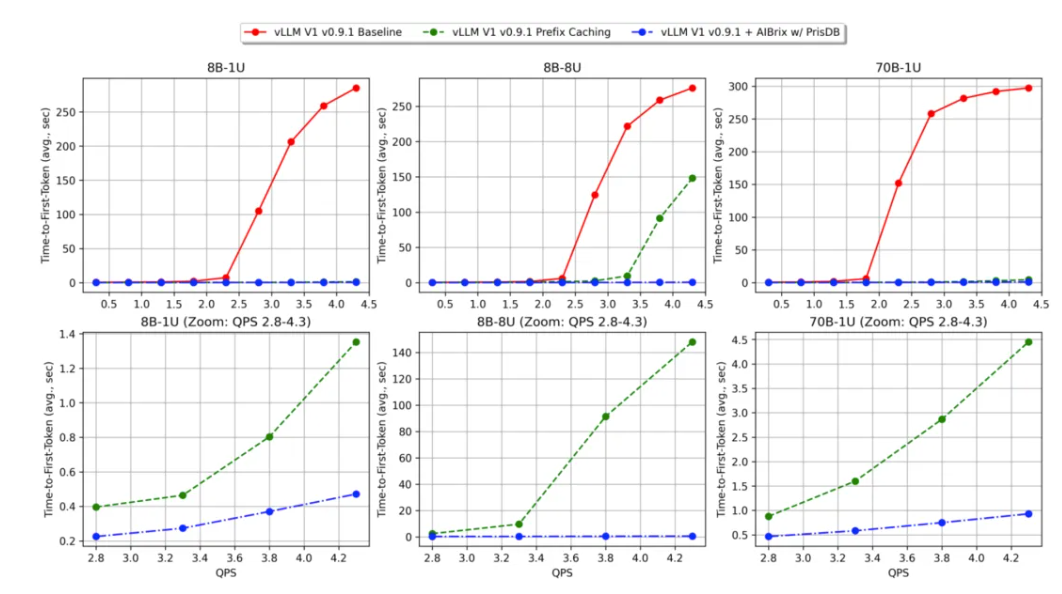
火山EIC 团队的基准测试表明,在高并发场景(70B 模型)下,平均 TTFT 降低了 89.27%,吞吐量提高了 3.97 倍。还使用 PrisDB 作为二级缓存后端,进行了与 0.3.0 版本相同的基准测试。这些基准测试是通过两个模拟生产工作负载进行的。两个工作负载具有相同的共享特征,但规模不同。在 workload-1 中,所有唯一请求都可以放入 GPU KV 缓存,而 workload-2将唯一请求的内存占用扩展到 8 倍,模拟缓存竞争严重的容量受限用例。与 vLLM 基线(无前缀缓存)和 vLLM 前缀缓存相比,AIBrix + PrisDB 表现出更出色的 TTFT 性能,尤其是在每秒查询率(QPS)增加的情况下。下图显示,AIBrix + PrisDB 在所有负载级别和基准测试中都能实现亚秒级的 TTFT,并具有显著的 TTFT 优势。
(注释:8B-1U = DeepSeek-R1-Distill-Llama-8B + workload-1;8B-8U = DeepSeek-R1-Distill-Llama-8B + workload-2;70B-1U = DeepSeek-R1-Distill-Llama-70B + workload-1)
![]()
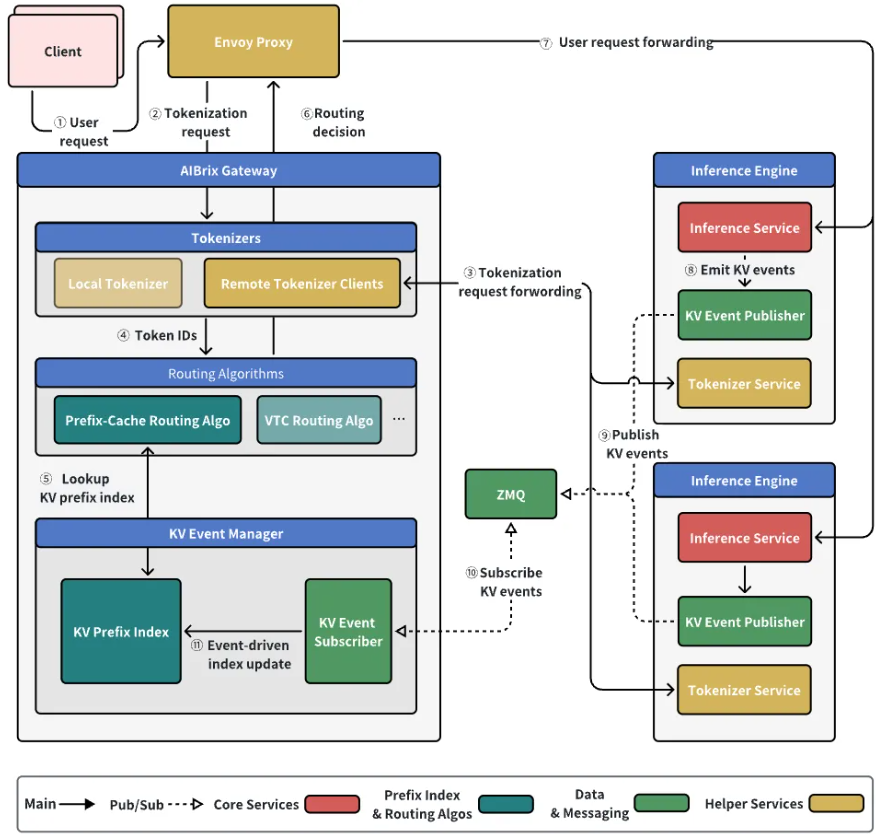
4.KV 事件订阅系统
AIBrix v0.4.0 的新 KV 事件订阅系统通过在分布式节点之间实时同步 KV 缓存状态,提高了前缀缓存命中率。这个新系统提供了不同权衡的选择,允许用户根据自己的需求在 系统简单性 和 前缀缓存状态准确性 之间做出决定。
此功能的核心思想是通过消息中间件在所有路由器之间广播 KV 缓存状态更改事件。这为路由层提供了近实时的全局缓存视图,从而实现 更精确的路由决策。
理论上,全局状态同步可以显著提高集群的潜在前缀缓存命中率。然而,这种优势是有代价的。该方法引入了消息队列管理的 额外开销,增加了系统复杂性。在当前版本中,不能保证性能提升,因为路由算法尚未完全适配。此外,索引器在大规模部署中可能面临 可扩展性挑战。
相比之下,传统的非同步方法更简单、更轻量级,不需要额外的同步组件。其主要缺点是可能存在 不一致性,因为每个节点独立运行其驱逐策略,这可能会降低整个集群的前缀缓存命中率。
要启用 KV 事件订阅系统,必须激活远程分词器模式,并在网关插件组件中设置以下环境变量:
// 启用 KV 事件同步 AIBRIX_KV_EVENT_SYNC_ENABLED: true// 依赖并启用远程分词器模式 AIBRIX_USE_REMOTE_TOKENIZE: true
如果禁用同步,路由器将自动恢复到原始的前缀缓存路由逻辑。
![]()
KV 事件订阅系统是 AIBrix 迈向高性能分布式前缀缓存的一步。未来的工作将专注于深入优化路由算法,并增强索引器等核心组件的可扩展性,以充分发挥系统的潜力。
5.多引擎支持
此前,AIBrix 主要支持 vLLM 引擎,限制了比较不同推理后端的灵活性。通过最新更新,AIBrix 现在支持 多引擎部署,允许开发人员在单个 AIBrix 集群中同时运行 vLLM、SGLang 和 xLLM。这为基准测试和生产部署开辟了新的可能性,同时利用了 AIBrix 的统一服务基础设施。
关键点包括:
model.aibrix.ai/engine以指定引擎类型,并使用 model.aibrix.ai/name及相关标签来识别模型。例如,用 engine: "vllm"标记 vLLM 部署。
avg_generation_throughput_toks_per_s与 SGLang 的 gen_throughput。如果所需指标不受支持,路由器将恢复到随机策略。
多引擎支持使得同时运行 vLLM 和 SGLang 变得容易,并便于模型迁移或 A/B 测试。随着更多引擎的加入,社区可以利用此机制探索不同的推理栈。
其他改进
AIBrix 网关现在支持基于请求分析和基于截止时间的流量控制的服务级别目标(SLO)感知路由,使系统在动态流量模式下能够更智能、更灵敏地处理负载。其他改进包括可配置的超时时间、自定义指标端口,以及一个可直接使用的 Grafana 仪表板以提高可观测性。
在控制平面方面,加强了 Webhook 验证、CRD 存在性检查,并添加了在组件重启时安全重新同步缓存状态的机制。还解决了路由器准确性、前缀缓存可扩展性、响应体解析和自动伸缩器配置错误等关键问题,使系统更加稳定,适合生产环境。
下一步计划
AIBrix v0.5.0 将专注于为 基于智能体的用例、多模态 和 经济高效的多租户服务 提供强大功能。以下是即将推出内容的概览:
- P/D 分离提升:引入了更多可用于生产的部署模式和示例,改进了 PodGroup 的集成,以实现更好的调度对齐并增强了自动扩缩容支持。
- 批量 API:推出新的批量推理 API,以提高对延迟不敏感场景下的 GPU 利用率。
- 多租户功能:添加支持租户感知的隔离、请求隔离和按租户设置的服务级别目标(SLO)控制,以实现更安全的共享部署。
- 智能体的上下文缓存:通过新的上下文缓存接口,实现多轮对话和智能体程序之间会话历史的高效复用。
- 多模态支持:将键值缓存(KVCache)和运行时支持扩展到视觉和嵌入模型,为多模态服务奠定基础。