本文整理自 Discord 机器学习工程师 David Christle 在 Pulsar Summit NA 上的演讲内容,一起来看Discord 是如何实现兼顾安全和个性化功能的实时流式机器学习平台的。
1. 背景
Discord 是一个实时⾳视频通信平台,⽀持⽂本/语⾳/视频频道交流,广泛应用于1对1、中小团队或⼤型社区的在线交流场景,能支持用户从私密聊天到百万级社区通信的不同需求。平台于2015年创立,最初在游戏社区中流行起来,目前已扩展到多个领域,月活用户达1.5亿。
2. 挑战
Discord 面临的核心挑战是升级其实时流式机器学习平台,以应对安全和个性化需求,例如限制垃圾信息访问或保护用户账户免遭入侵。其原先架构是为启发式规则设计的,而非机器学习。为了寻求一个稳健、可扩展且实时的解决方案,他们探索了集成 Apache Pulsar、Flink和 Iceberg 的方案。
![]()
![]()
2.1 需求
“该系统的运行速度和可扩展性是关键所在。”
“该框架非常强大,支持过滤、转换、连接、聚合等操作;你在数据处理方式上拥有极大的自由度,即使在实时场景下效率也非常高。这些管道可以非常简单,比如事件采集和去重;也可以用来完成 ETL 任务。我们能在流数据上以极低延迟进行机器学习。”
安全
- 反垃圾邮件:通过跨职能团队协作,最大程度避免⽤户对垃圾内容和垃圾邮件发送者的接触
- 账户安全:主动保护⽤户账户免遭⼊侵,并在⼊侵发⽣时实现快速检测
- 处理速度和可扩展性:解决⽅案的速度和可扩展性⾄关重要,直接影响⽤户体验和安全防护效果
个性化
- 发现服务器(Discord Server,类似兴趣组):帮助⽤户快速发现感兴趣的新服务器
- 通知优化:实时确定最佳通知内容和发送时机,确保信息时效性
- 响应速度:需要在⼏分钟内完成相关计算,避免内容过时失效
2.2 痛点
- 规则引擎不适合ML: 专为人工规则设计,无法处理历史数据,基础计算困难,导致新特征上线延迟长达一个月。
- 批处理延迟高、整合难: 数据获取的延迟依赖批处理的效率,手动拼接批处理与实时特征易错难调,模型问题诊断困难。
- 微服务臃肿低效: 每个模型独立部署微服务带来高复杂度与部署负担,响应速度跟不上威胁变化,灵活性牺牲了实时性。
3. 解决方案
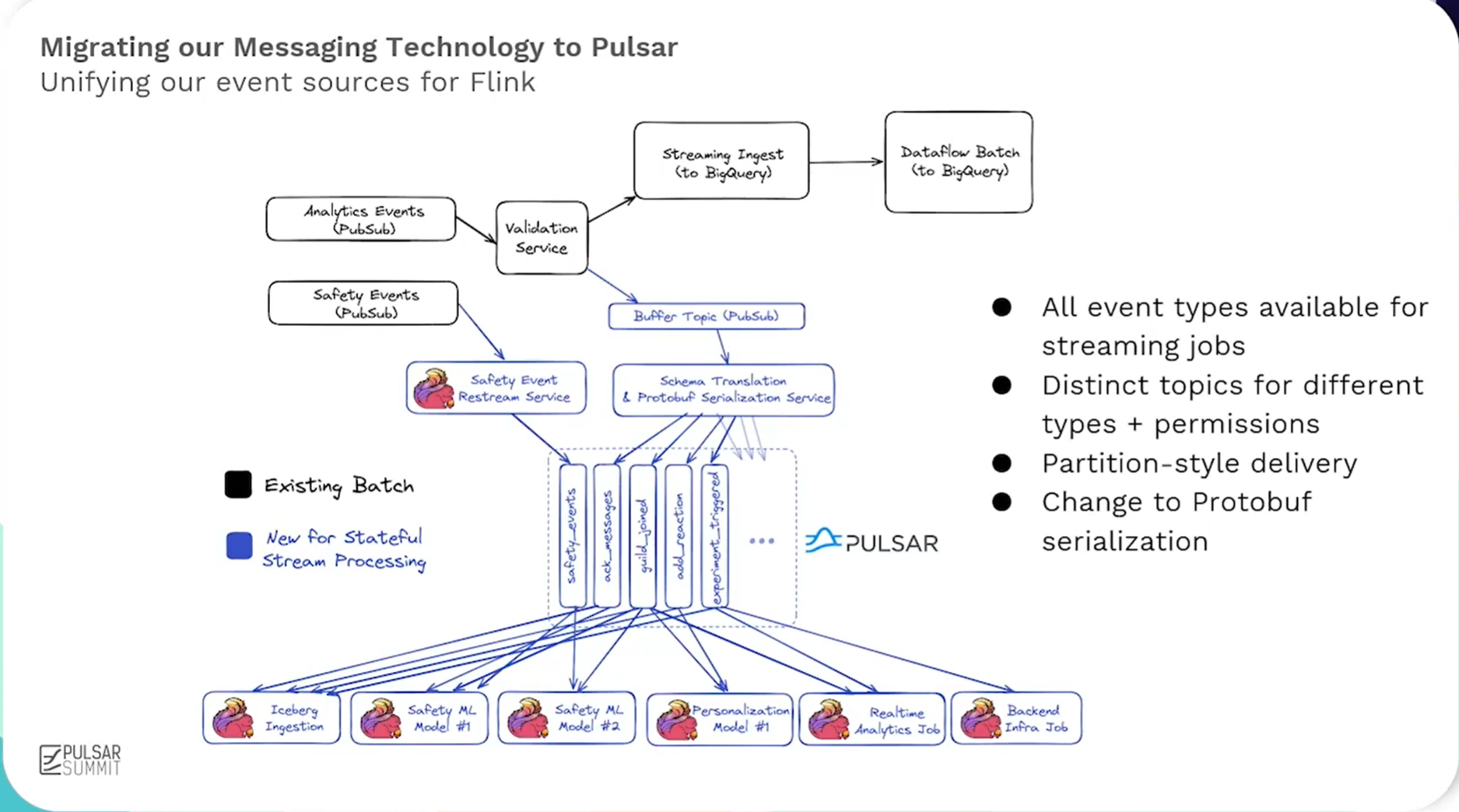
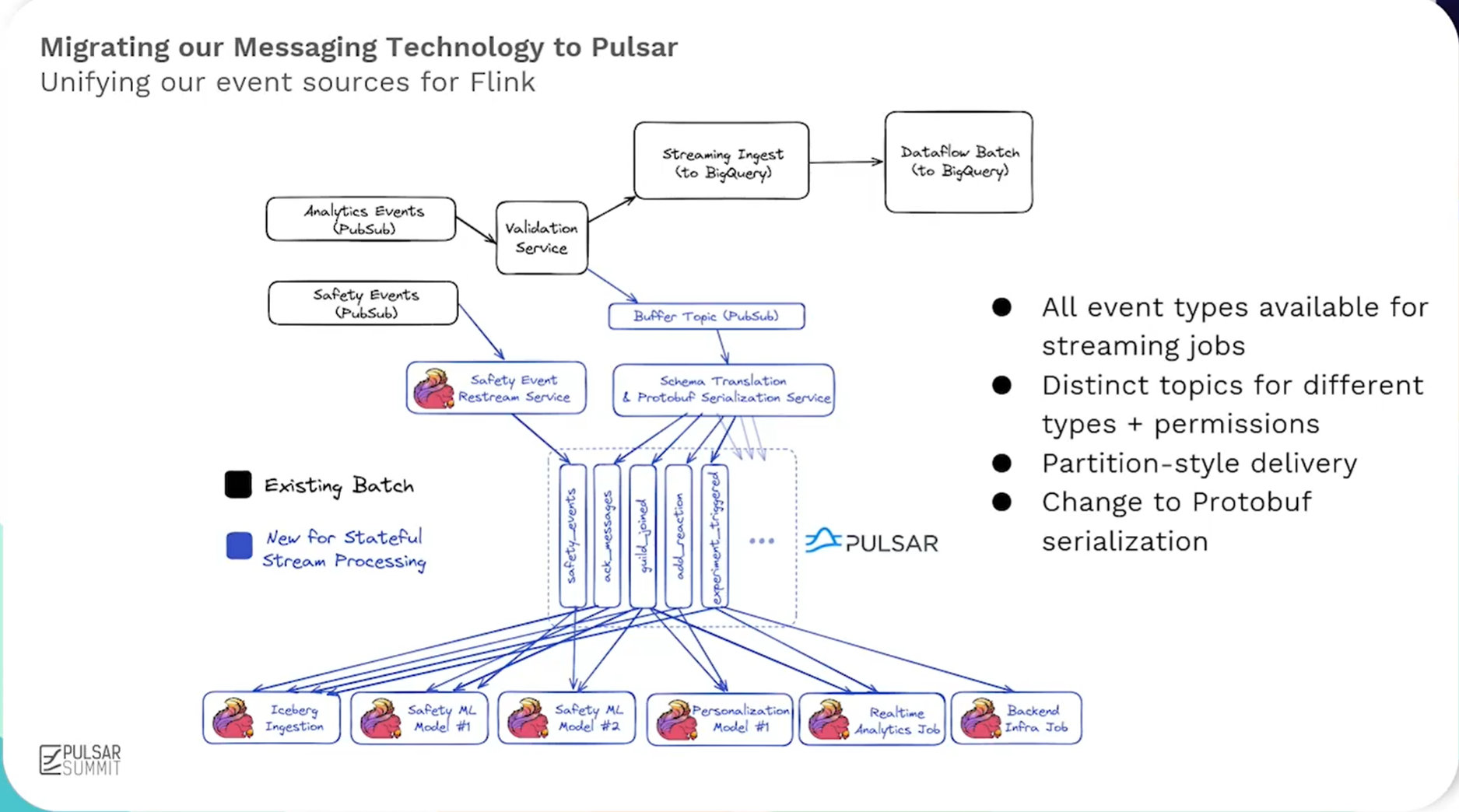
Discord 采用了基于 Pulsar、Flink和 Iceberg的实时流处理方案。其中,从 Google Cloud Pub/Sub(GCP) 迁移到 Pulsar 是一个关键决策,显著提升了效率和可扩展性。Flink 和 Iceberg 则在分析实时数据、管理历史事件以及回填(backfill)方面发挥了至关重要的作用。
“对我们而言,Pulsar 的关键优势在于它不仅拥有队列传输模式(这在 Discord 非常常用),还提供了分区式传输模式。”
“Pulsar分区传输在保障顺序性的同时,还能实现极低的延迟 ;我们利用这一点实现了近乎即时的水位线(watermark)体验,并在低延迟的情况下获得了准确的结果。”
![]()
![]()
GCP 提供了一种无状态且无序的内部事件流量托管方案,适用于不关⼼时间顺序的宽泛分发队列、大规模并⾏处理的⽆状态任务,但存在以下问题:
- Connector:Flink-PubSub连接器维护不⾜且过时;需要依赖开源PR才能实现统⼀批流API
- 高延迟:高达20-40s的延迟
- 高成本:随着规模扩大成本明显拉高
在这种场景下,Pulsar 凭借丰富的 Connector支持、分区和队列双模式、存算分离、原生多租户支持及优秀的低延迟表现从众多方案中脱颖而出。
![]()
![]()
基于业务需求,Discord的工程师团队构建了一个成熟精简、高效灵活且突破传统限制的生产级架构,Pulsar在其中扮演了实时数据主干网与流批融合关键枢纽的角色。
- 精简架构与生产就绪的ML生态系统: 该方案显著简化了架构,减少了部署组件。工程师无需关注底层数据来源的复杂性,系统自动处理数据分区和可靠交付。数据处理流程清晰高效:利用Flink作业进行实时的特征计算(过滤、聚合、连接等),并将长期运行(数月)的计算结果直接输出到Iceberg表中,作为高质量的训练数据集。模型部署采用ONNX格式,兼容XGBoost、PyTorch、TensorFlow等主流框架,其二进制文件可直接嵌入Flink作业运行,完全摒弃了传统独立的模型服务,这不仅大幅降低了系统复杂度和潜在错误,也使得开发调试更简单快速,显著提升了开发效率。
- 灵活流处理与混合源能力: 系统的关键创新在于利用Flink的
HybridSource技术,无缝融合了批处理源(Iceberg)和流处理源(Pulsar)。Pulsar作为核心的实时数据流来源,与Iceberg的历史数据结合得天衣无缝。系统能够在预定时间戳自动在批处理和流处理源之间透明切换,这对工程师完全隐藏了底层复杂性。这种设计确保了开发环境与生产环境数据源的高度一致性,工程师可以直接使用Pulsar流和Iceberg表进行开发测试,并支持从历史任意时间点(数月甚至一年前)启动作业,进行回溯或调试。即使在处理海量数据时,基于Pulsar提供的稳定实时流和Iceberg的可靠存储,系统也表现出极强的稳定性和增量处理能力。
- 突破实时状态与回填限制: 该架构彻底解决了实时ML系统常见的状态管理和历史数据回填(backfill)难题。得益于流批一体的设计(核心是Pulsar流与Iceberg表的融合)和模型内嵌于Flink作业的简化架构(模型仅是作业中的一个“小方块”),系统发生变更后,历史数据的回填速度极快,仅需3-4小时即可完成。这使得快速训练新模型并部署上线观察效果成为现实,极大加速了模型迭代周期。运维层面,通过自定义Bazel规则简化了ML工程师的工作流,并利用Flink Kubernetes Operator自动化管理作业的完整生命周期(包括部署、保存点、高可用性),确保了系统的稳健运行。Pulsar提供的持久化、可重放实时流,是支撑快速、稳定回填的关键基础设施之一。
- 关键安全指标提升与广泛适用性: 此系统在Discord最核心的安全场景(如垃圾邮件过滤和账户保护)中实现了两位数的关键指标提升,并成功将平台超过60%的安全评分决策从传统启发式规则迁移至实时ML模型驱动。这得益于Pulsar提供的高吞吐、低延迟实时数据流,使得系统能够在虚假账户和僵尸网络发起攻击、造成实际损害前就进行主动检测与拦截,显著增强了平台的实时防御能力。更重要的是,该架构设计具备高度通用性,其基于成熟开源技术栈(Flink、Pulsar、Iceberg)的精简模型和流批一体能力,使其可轻松扩展应用于A/B测试、用户实验、个性化推荐等多个场景。
4. 结语
Discord 的成功实践充分验证了由 Apache Pulsar、Flink 和 Iceberg 构建的实时机器学习平台的高效性与强大潜力。利用 Pulsar 作为高吞吐、低延迟的实时数据主干网,无缝连接流处理与批处理,为 Flink 的实时特征计算和模型嵌入提供了坚实基础。David Christle 的分享不仅展示了这一技术栈(尤其是 Pulsar 在流批融合中的关键作用)的强大实力,更凸显了小型团队基于成熟开源技术打造精简、高效生产系统的卓越能力。该案例也为业界探索实时机器学习融合、构建以可靠消息流(如 Pulsar)为核心的实时数据管道提供了极具参考价值的范本。