![封面2]()
直播回放:https://www.bilibili.com/video/BV1X2tdziE9Z/?vd_source=e59b2227d15c7740a5c5f40e4a675095
在数据驱动与智能化的浪潮下,数据调度平台的价值正在被重新定义。天翼云翼 MR 与 Apache DolphinScheduler 的结合,不仅是一次技术选型,更是一次从社区到企业的深度融合与创新探索。
作者介绍
![]()
社区共建:从使用到贡献
天翼云团队与 Apache DolphinScheduler 社区的合作由来已久。除了在生产环境中深度使用外,团队成员也积极参与社区建设,通过PR提交、问题反馈、功能建议等多种方式推动项目迭代。
部分贡献示例:
![]()
这种双向互动,不仅让平台更贴合实际业务需求,也让社区获得了来自一线生产的真实反馈。
翼MR+DolphinScheduler:云上大数据的稳定基座
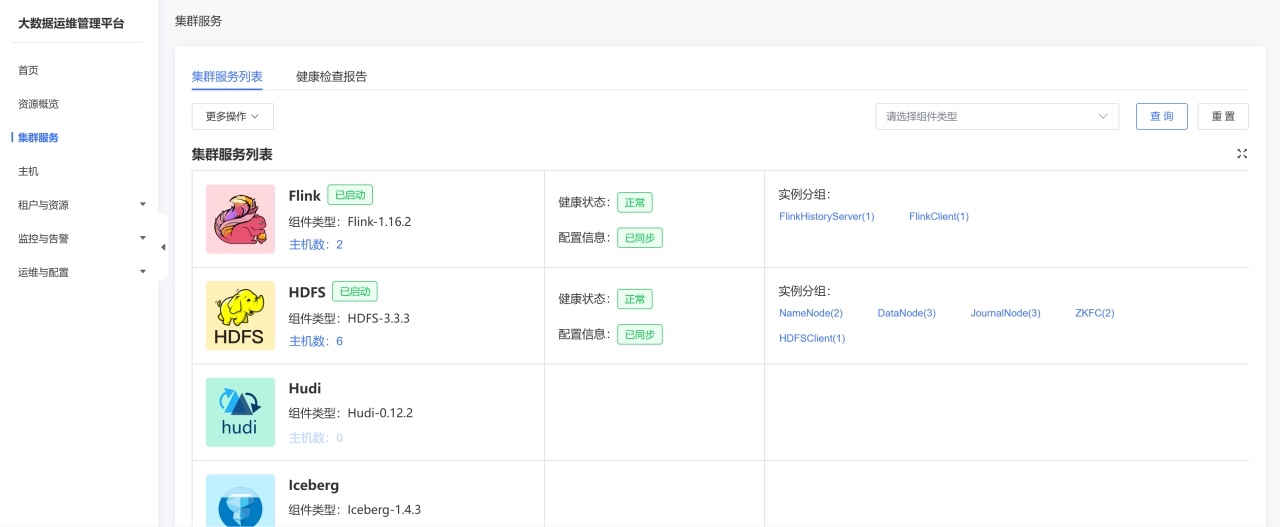
作为天翼云的大数据计算平台,翼MR为用户提供了即开即用、安全可靠、便捷管理的公有云形态:
![]()
更重要的是,翼 MR 与大数据组件实现了自动集成 ,用户在DolphinScheduler 中调度任务时,无需繁琐的环境配置,即可直接调用 Hive、Spark、Flink 等组件。 ![]()
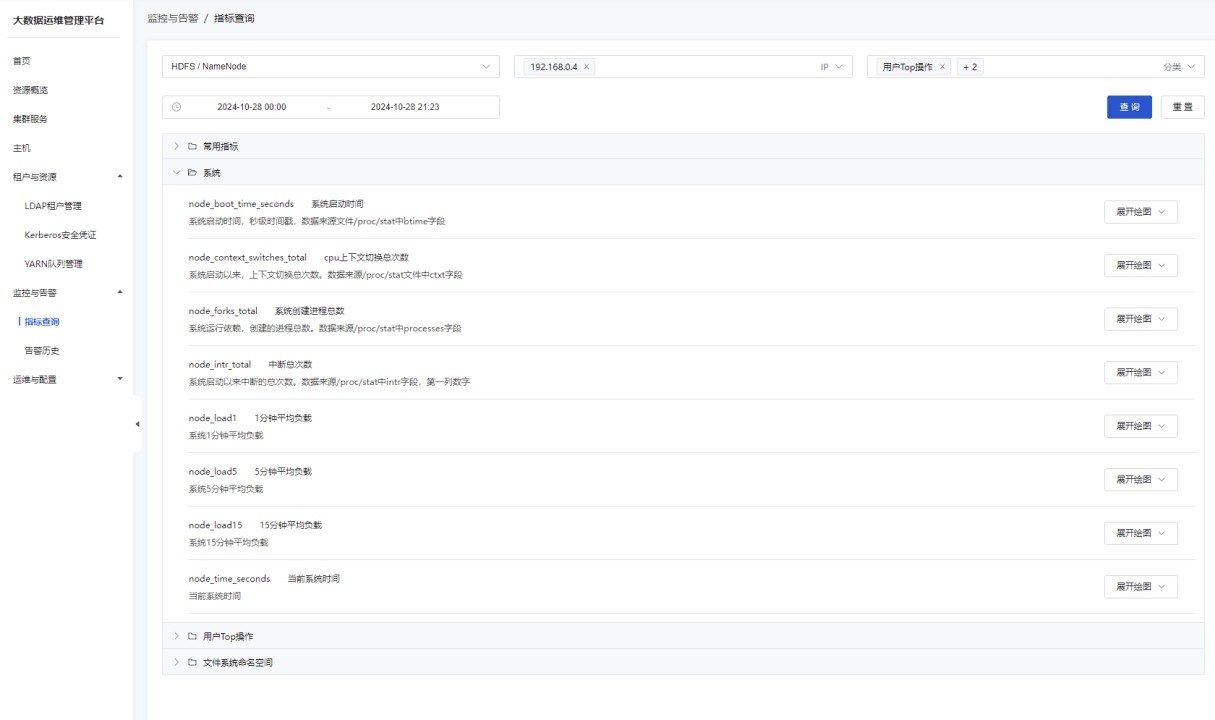
此外,平台内置的基于 Apache DolphinScheduler 优化的监控与运维系统 ,为任务执行提供全链路可视化管理,帮助运维人员快速定位问题、优化性能。 ![]()
二次开发:让调度更贴近业务
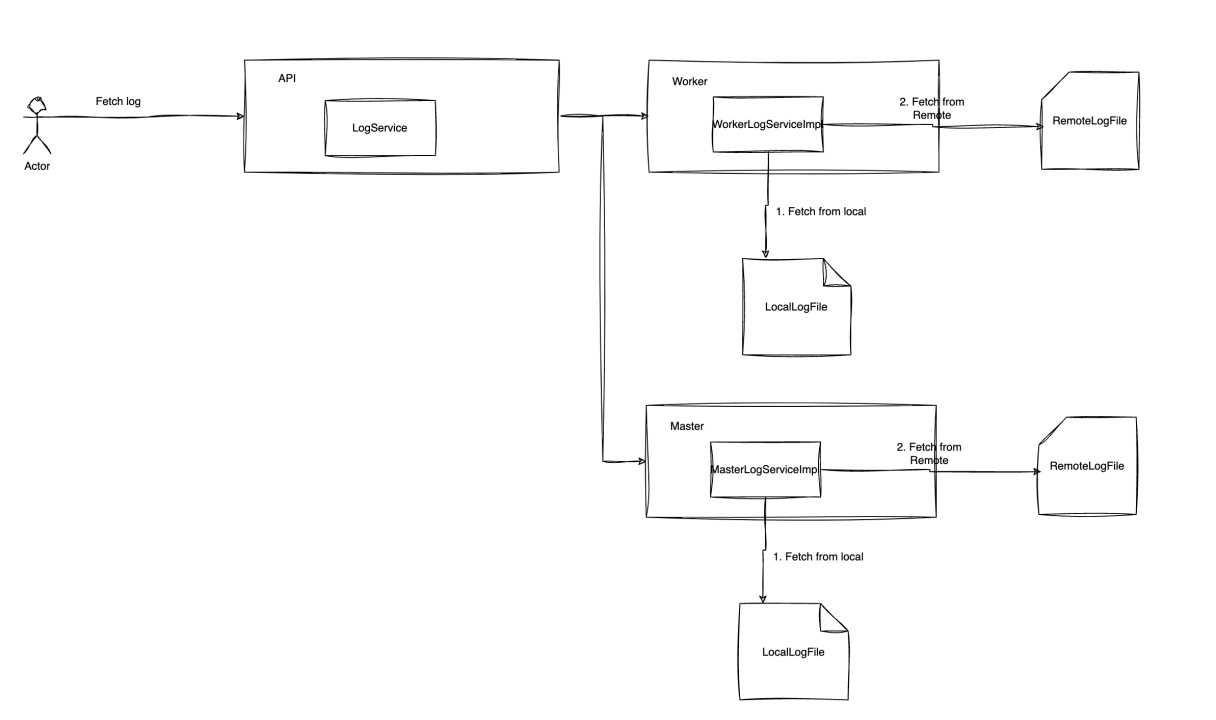
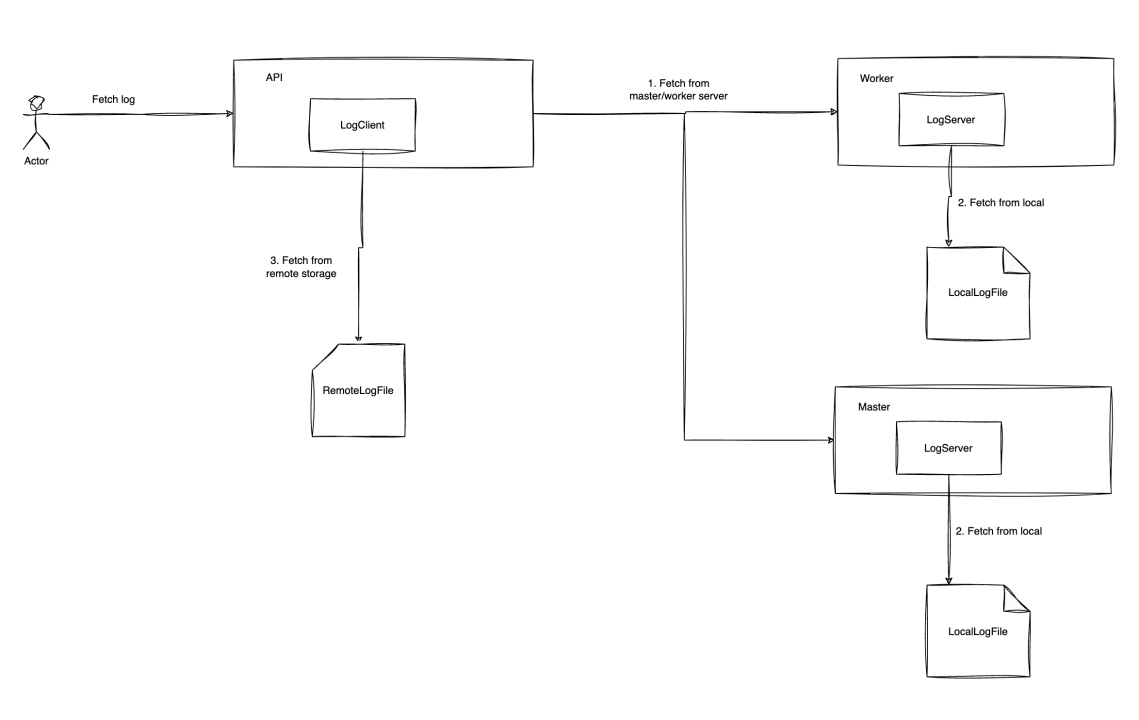
在生产环境中,天翼云团队基于DolphinScheduler进行了多项定制化优化:
-
结果集标准化 将节点输出统一为CSV格式,降低内存占用、提高落盘效率。
-
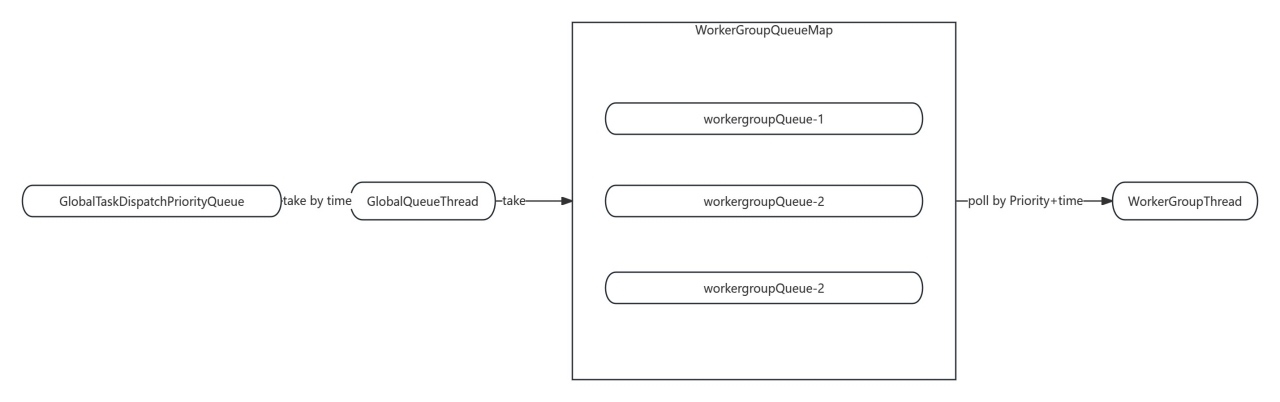
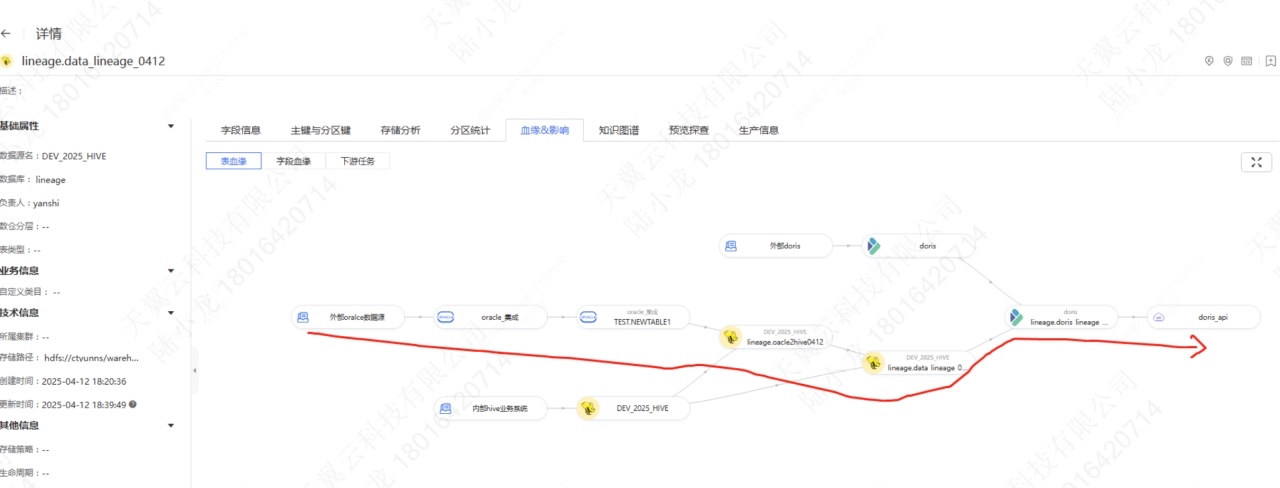
全链路血缘追踪 可视化展示数据从采集、加工到输出的全路径,支持任务间依赖分析与审计。 ![]()
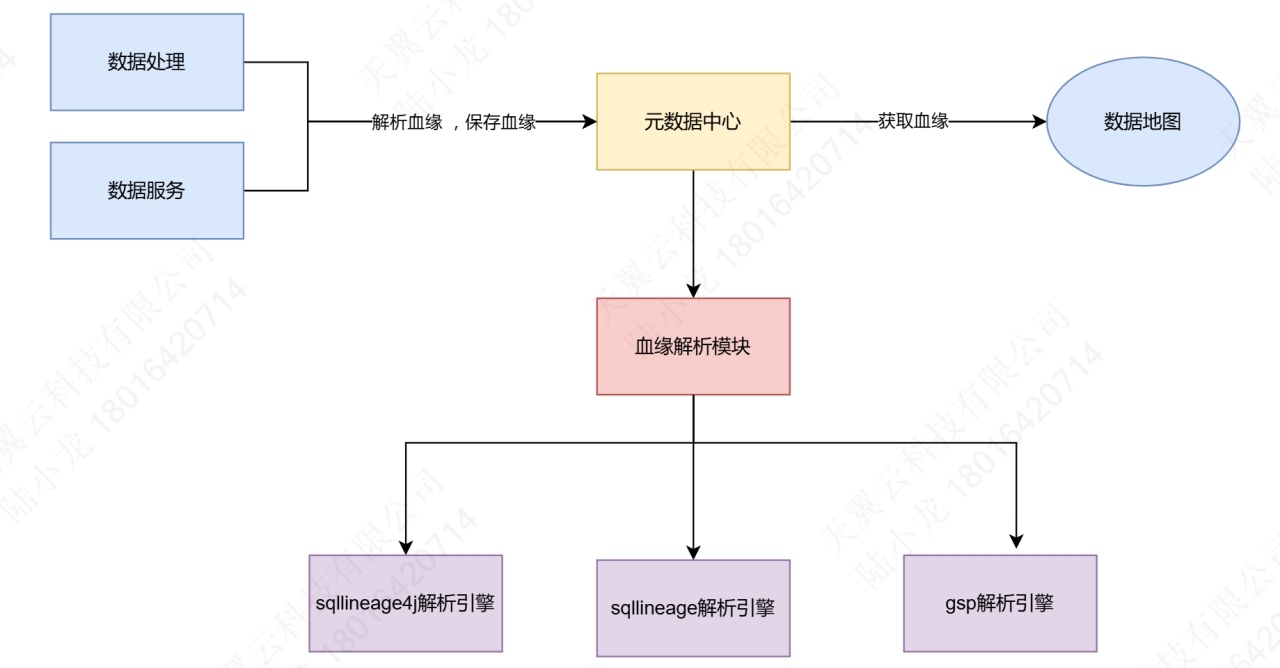
通过 SQLLineage4J、SQLLineage 和 GSP 三大解析引擎,把各类 SQL 脚本解析成血缘关系,保存到元数据中心;随后由数据地图、数据服务等下游模块消费这些血缘信息,实现数据资产的可视化、查询和影响分析。 ![]()
-
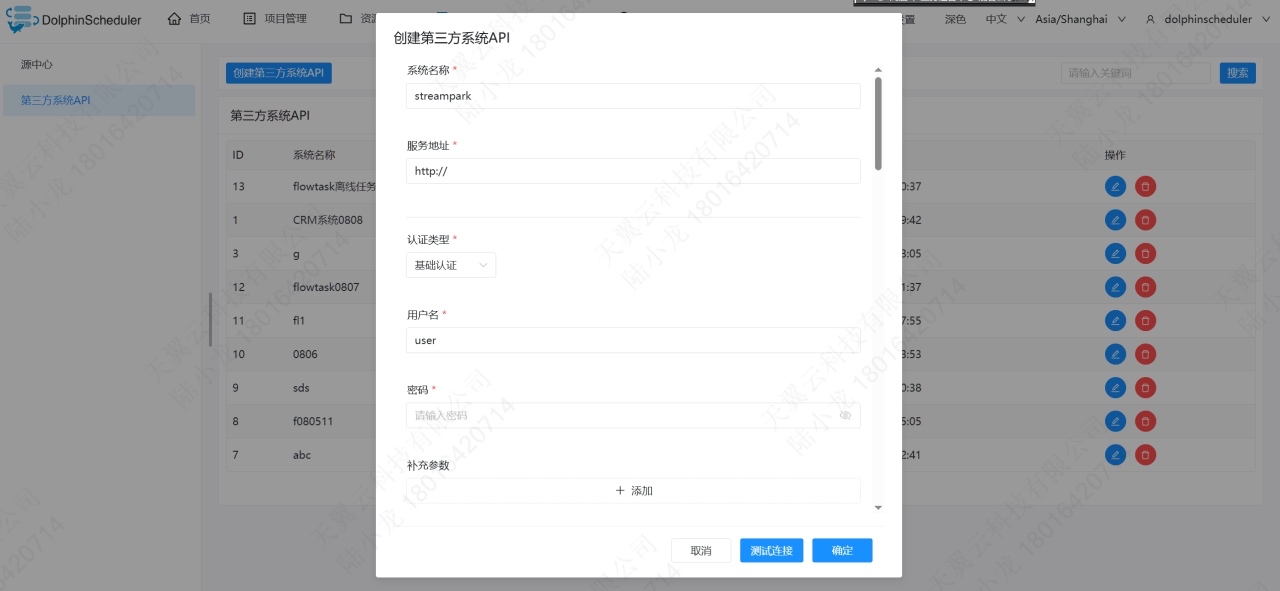
第三方任务系统集成 支持通过界面化注册接入第三方任务系统(如 Dinky、AWS EMR),并可借助 OpenAPI 直接提交任务,减少接入开发成本。 ![]()
这些优化大幅提升了任务调度的灵活性与可维护性,也为不同类型的业务提供了统一的调度中枢。
面向AI时代的展望
最后,我想分享一下我关于在 Agentic AI 趋势下,DolphinScheduler 的展望。在 Agentic AI 时代,用户对 Dolphinscheduler 的要求,或者说使用方式正在发生变化。例如在 6 月份的 Meetup 上,社区分享了 DolphinScheduler 的 MCP(Model Context Protocol)相关探索,这意味着未来DolphinScheduler的"用户"可能从人类开发者延伸到AI Agent。
也许不久的将来,Dolphincheduler 的目标用户会变成 agent,调度平台将不再只是面向人类的 Web 控制台,而是 AI 工作流中的一环。当然,我觉得 Dolphinscheduler 在这个环节中具有天然优势,因为虽然大数据各种组件都在搞自己的 MCP Server,但是 Dolphinscheduler 作为一个集成了几乎所有大数据组件的调度平台,相比让各个组件自研 MCP Server,由DolphinScheduler 作为统一调度入口,它会更加高效、更易维护,也更轻量。
理想很丰满,那么这些想法该如何落地呢?我认为,正如代立冬在issue #17334提出的那样,引入大模型能力,是迈向这一未来的第一步。作为社区的一份子,我呼吁大家积极加入到这个话题的探索之中,群策群力,共同早日把我们的设想落实下去。
写在最后
天翼云翼 MR 与 Apache DolphinScheduler 的结合,是一次社区与企业的双向奔赴,也是在 AI 浪潮下对调度平台角色的新思考。未来,随着 Agentic AI 的发展,这一组合将在更多场景中释放价值。
如果你对大数据调度、AI 工作流感兴趣,欢迎通过公众号、Slack、GitHub 加入 Apache DolphinScheduler 社区,一起探索数据调度的更多可能。