在Pulsar broker中, 消息的Retention, Expiry和Backlog quota是比较重要的功能,它们表现的是Pulsar对于流经它的数据的管理。
但是受限于复杂度和文档语言等因素,使用者可能无法在第一时间很直观的了解它们。 因此本文将对这三个功能进行详细的介绍,包括概念、行为、应用、实现和注意事项等方面,希望能够对大家有所帮助。
另外,这三个特性属于Pulsar的高级特性,阅读本文之前,建议先对Pulsar的基本概念有所了解。
文章较长,并且偏向工具类,建议大家先收藏,如果暂时没耐心看完,也可以在后续时间慢慢阅读。
话不多说,直接开冲!
一、Retention
1. 概念
Retention是Pulsar对消息的保留策略,它针对于所有消息,包含已经消费的消息和未消费的消息。
Pulsar的消息保留略有一点反直觉,我们一般会认为消息保留针对已经消费完毕的消息,在消费完毕后保留一段时间之后再进行清理,腾出磁盘空间。很多资料以及之前版本的Pulsar官网都是这样理解和表达的,但是实际并非如此。
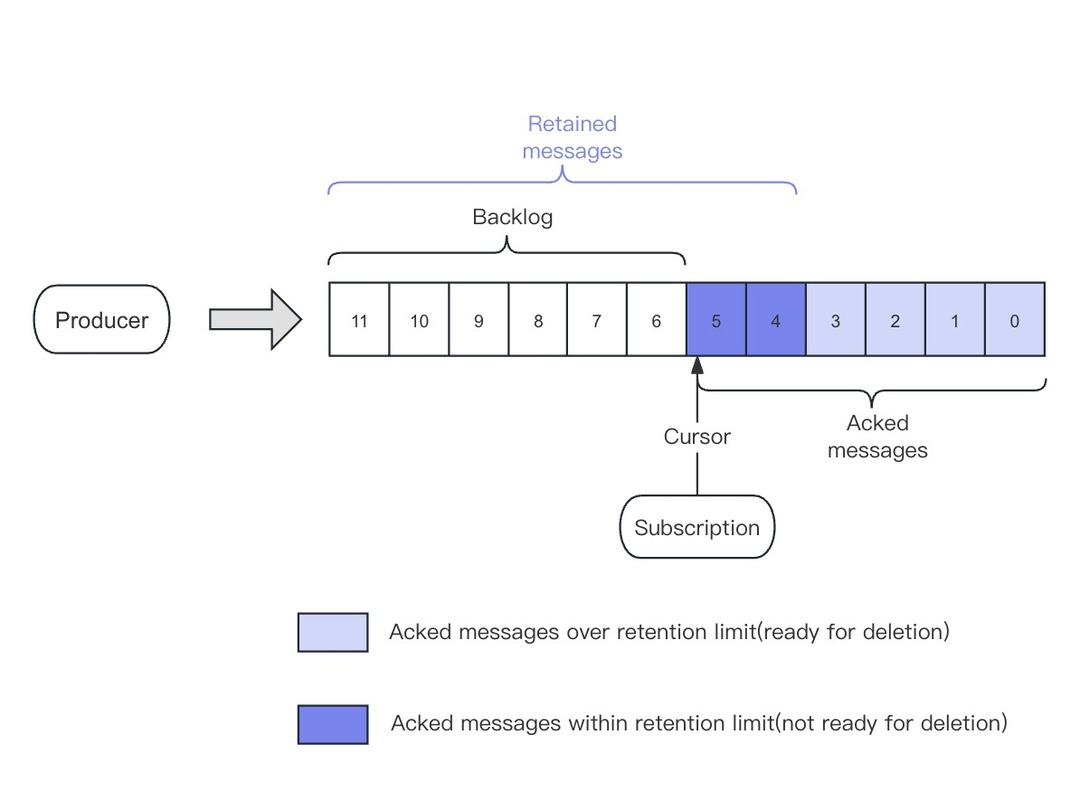
Retention首先保证的是消息回溯,比如将保留策略设置为3天,用户一定能够回溯3天之内的消息。在此之后再考虑删除更早的消息,以腾出磁盘空间。 由于不同Subscription的消费进度可能不同,有的较快,有的较慢,因此Pulsar对数据的删除是以该Topic中消费最慢的Subscription为基准,被它消费过后的数据才是可删除的。但是,删除与否还需要看Retention如何设置。同时,无论未被消费的消息是否超出了Retention的限制,它们都会保留,不会删除。
总结一下:如果未消费的消息超出了Retention限制,则保留所有未消费的消息,删除所有已消费的消息;如果未被消费的消息没有超出Retention限制,则保留所有未消费的消息以及一部分已经消费的消息,删除其余已消费的消息。
![]()
2. 行为
Pulsar的数据清理由定时任务驱动,每隔一段时间Broker会检查当前实例上的所有Topic,如果Topic设置了Retention策略,它会根据相应的策略来检查该Topic中的数据,并清理数据。 Retention策略包含了两项限制,分别是:retentionTimeInMinutes(单位:分钟)和retentionSizeInMB(单位:MB)。如果有任意一项条件满足,Pulsar将执行清理流程。
数据清理的维度在Topic级别,粒度在Ledger级别。即:
- 如果旧数据清理完成,该Topic所有的Subscription的所有Consumer将无法消费已经清理的旧数据,即使调用
seekAPI重置游标;
- Broker无法按照
retentionTimeInMinutes和retentionSizeInMB来完全精确地清理磁盘,Pulsar对于数据的管理是在Ledger维度,因此,如果在一个Ledger中有些数据应该被清理而另一些数据应该被保留,这个Ledger也会被保留,不做清理。在最差的情况下,会为每个Topic/Partition额外保存2GB数据(精度取决于broker.conf的managedLedgerMaxSizePerLedgerMbytes(default=2GB))。
对于消费者们来说,数据清理是在清理流程之后立即生效的,也就意味着在清理流程完成之后,Consumer便无法消费更早的数据;但是在磁盘的角度来看,Pulsar的数据清理流程和实际的磁盘空间清理之间会有一个短暂延迟,这是因为磁盘清理流程是由Bookkeeper异步调度的。这个延迟通常不会太久,在Pulsar的清理流程完成之后,很快就能看到数据磁盘空间的释放。
3. 应用
a.监控
Pulsar并未专门为Retention暴露指标,但是可以通过一些指标来间接的监控Retention的情况:
pulsar_storage_size:该指标表示Pulsar的存储空间使用情况,如果该指标持续增长,可能是Retention策略没有生效,需要检查一下Retention策略是否设置正确。正确的Retention策略应该是周期性的清理旧数据,pulsar_storage_size表现为周期性的上下波动;Topic internal stats: Pulsar提供了一些Topic的内部指标,它暴露了当前Topic的Ledger大小,Ledger关闭时间等指标,可以通过这些指标间接监控Topic的数据清理情况(通过size和timestamp计算该Ledger是否应该删除):
pulsar-admin topics stats-internal persistent://my-tenant/my-ns/my-topic
{
...
"ledgers" : [
{
"ledgerId" : 20,
"entries" : 50000,
"size" : 500000,
"timestamp": 1627584000000
},
{
"ledgerId" : 21,
"entries" : 50000,
"size" : 500000,
"timestamp": 1627585000000
}
],
...
}
b. 设置
Retention的设置分为namespace和topic两个级别(实际上有3个,还有一种是Broker级别,本文不讨论该级别)。在Namespace级别设置了Retention之后,该Namespace的所有Topic都会继承它;但是我们可以在Topic级别对其进行覆盖,使该Topic使用自定义的Retention策略。
- Namespace级别
pulsar-admin namespaces get-retention my-tenant/my-ns
{
"retentionTimeInMinutes": 10,
"retentionSizeInMB": 500
}
pulsar-admin namespaces set-retention my-tenant/my-ns --time 10 --size 500
pulsar-admin namespaces remove-retention my-tenant/my-ns
- Topic级别
pulsar-admin topicPolicies get-retention persistent://my-tenant/my-ns/my-topic
{
"retentionTimeInMinutes": 10,
"retentionSizeInMB": 500
}
pulsar-admin topicPolicies set-retention persistent://my-tenant/my-ns/my-topic --time 10 --size 500
pulsar-admin topicPolicies remove-retention persistent://my-tenant/my-ns/my-topic
4. 实现
Retention执行的入口是BrokerService#startConsumedLedgersMonitor(), 这里不对实现做详细分析,只是简单的介绍一下Retention策略的执行流程,如果各位感兴趣,可以自行查看源码。
a. Retention Checker初始化
Pulsar broker启动时,向线程池注册一个定时任务,执行周期是broker.conf的retentionCheckIntervalInSeconds(default=120s)。 Broker每120s会检查一次所有的Topic,如果Topic设置了Retention策略,则执行数据清理。
b. 清理流程
Retention的执行流程如下:
- 遍历所有的Topic,如果Topic设置了Retention策略,执行后续流程。否则,跳过该Topic;
- 找到该Topic中消费最慢的Subscription,得到它的消费位置;
- 根据上一步得到的消费位置,找出在它之前的所有Ledger,得到所有消费完毕的Ledger列表;
- 由创建时间从远到近遍历上一步得到Ledger列表,并根据当前Ledger的元数据做相应的计算。注意:当前正在写入的Ledger不会进入清理流程:
- 累加当前Ledger的size,如果Topic数据的总大小减去累加的size大于等于
retentionSizeInMB,将该Ledger加入待清理列表;
- 根据当前时间和Ledger元数据中
timestamp(即Ledegr的关闭时间)计算当前Ledger的存活时间(当前时间减去Ledger关闭时间),如果存活时间大于retentionTimeInMinutes,将该Ledger加入待清理列表;
- 待清理列表中的Ledger分为两部分,一部分是存在于Bookkeeper中,另一部分是存在于Tiered storage的中(如果设置了Ledger offload)。 针对这两部分Ledger,Pulsar会分别调用不同的清理接口(Bookkeeper或者Tiered storage接口)清理数据。
5. 注意事项
- 如果Namespace和Topic都设置了Retention策略,Topic的Retention策略会覆盖Namespace的Retention策略;
- 如果Namespace设置了Retention策略,但是Topic没有设置,Topic会继承Namespace的Retention策略;
- 如果Topic没有一个持久订阅,不对该Topic的数据做任何保留,所有数据将被删除;
retentionTimeInMinutes和retentionSizeInMB的单位分别是分钟和MB,它们之间的关系如下所示:
|time|size|说明| |-|-|-| |0|0|不保留任何数据| |-1|-1|保留所有数据| |-1|>0|基于size计算数据是否保留| |>0|-1|基于time计算数据是否保留| |0|>0|不生效| |>0|0|不生效| |>0|>0|满足任意条件即可|
- 如果Topic中有长时间未活跃的过期Subscription,会导致数据无法被清理。如果发现这种情况,可以通过以下命令来手动删除过期的Subscription:
pulsar-admin topics unsubscribe persistent://my-tenant/my-ns/my-topic --subscription my-sub
二、Expiry
1. 概念
Expiry定义了一种数据的过期策略,在Pulsar中,它通常的表现形式是TTL(Time to live)。
在某些场景中,数据具有时效性,如果数据生产了一段时间之后还没有被消费者消费,后面再继续去消费它就不再具有业务意义。
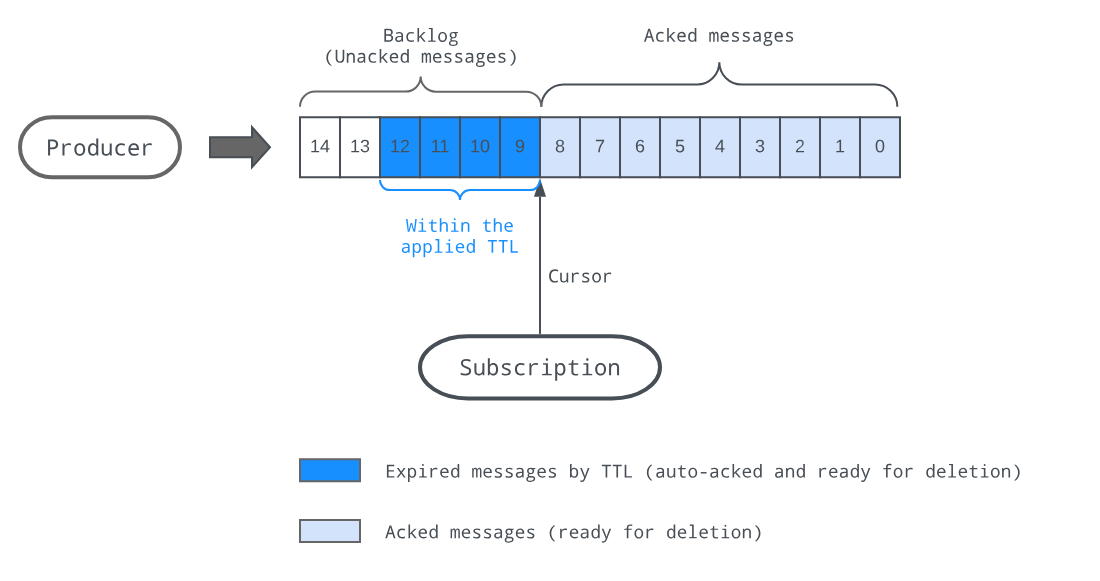
为了满足此类应用场景,Pulsar提供了Expiry机制。用户可以为一个Topic设置消息的存活时间(TTL),如果消息超过了这个时间还未被消费,在Expiry机制的作用下,它们会被认定过期并且被Pulsar自动确认,消费者不会再收到这些消息。
![]()
2. 行为
和工作在Topic级别的Retention不同,Expiry工作在Subscription级别。它同样由定时任务驱动,每隔一段时间Broker会检查当前实例上的所有Topic,如果设置了该Topic的messageTTL,Pulsar会根据messageTTL检查该Topic下的所有Subscription中的数据,如果发现有消息超时未被消费,Pulsar将自动移动Subscription的游标(自动确认超时消息),使得过期消息对消费者不可见。
3. 应用
a. 监控
- 在Prometheus级别,Pulsar为Expiry暴露了
pulsar_subscription_msg_rate_expired和pulsar_subscription_total_msg_expired 等指标, 一般来说只需要关注pulsar_subscription_msg_rate_expired 即可, 它表示每秒过期的消息数量。如果它始终为0,可能是Expiry机制没有生效或者所有消息都被及时消费;
- 同样可以通过
Topic stats 来监控Expiry的情况:
pulsar-admin topics stats persistent://my-tenant/my-ns/my-topic
{
...
"msgBacklog" : 0,
"msgRateExpired" : 0.0,
...
"subscriptions" : {
"test_sub" : {
...
"msgRateExpired" : 0.0, // 每秒过期的消息数量
"totalMsgExpired" : 0, // 总共过期的消息数量
"lastExpireTimestamp" : 0,
...
}
},
}
b. 设置
和Retention一样,Expiry机制的设置也分为namespace和topic两个级别。在Namespace级别设置了之后,该Namespace的所有Topic都会继承该策略;在Topic级别设置了之后,会覆盖Namespace的设置。
- Namespace级别
pulsar-admin namespaces get-message-ttl my-tenant/my-ns
{
"messageTTLInSeconds": 10
}
pulsar-admin namespaces set-message-ttl my-tenant/my-ns --messageTTLInSeconds 10
pulsar-admin namespaces remove-message-ttl my-tenant/my-ns
- Topic级别
pulsar-admin topicPolicies get-message-ttl persistent://my-tenant/my-ns/my-topic
{
"messageTTLInSeconds": 10
}
pulsar-admin topicPolicies set-message-ttl persistent://my-tenant/my-ns/my-topic --messageTTLInSeconds 10
pulsar-admin topicPolicies remove-message-ttl persistent://my-tenant/my-ns/my-topic
4. 实现
Message Expiry的实现的入口是BrokerService#startMessageExpiryMonitor(),这里不对实现做详细分析,只是简单的介绍一下Expiry策略的执行流程,如果各位感兴趣,可自行查看源码。
a. Expiry Checker初始化
在Pulsar broker启动时,向线程池注册一个定时任务,定时任务的执行周期是broker.conf的messageExpiryCheckIntervalInMinutes(default=5m)。
Broker每5分钟检查一次所有的Topic,如果Topic设置了messageTTL,则执行Expiry检查。
b. Expiry执行流程
- 遍历所有Topic,如果该Topic设置了
messageTTL,执行后续流程。否则,跳过该Topic;
- 遍历所有Subscription,如果该Subscription满足条件(有消息积压、有活跃的Consumer、最早未消费的消息已经过期),执行后续流程。否则,跳过该Subscription;
- 获取当前Broker的时间戳,再根据
messageTTL计算出消息的过期时间戳;
- 根据上一步中计算出的过期消息时间戳,使用二分查找算法找到相应的消息位置;
- 移动Subscription的游标到过期消息的位置,使得过期消息对消费者不可见。
5. 注意事项
在使用Expiry机制的时候,需要注意以下几点:
- 客户端需要保证本地时钟和Broker时钟同步,否则可能会导致消息过早或者过晚过期,因为对于过期消息的判定是以Broker时间为基准的;
- Expiry机制只会移动游标,不会删除消息,因此过期消息仍然会占用磁盘空间,如果需要删除过期消息,需要使用Retention机制;
- Expiry机制只会移动游标,不会删除消息,即使过期消息被移动到游标之后,消费者仍然可以通过
seekAPI来消费过期消息;
- 由于Expiry机制对于过期消息位置的查找是使用二分查找算法,因此在消息量较大的情况下,可能会导致性能问题;
- 同样因为Expiry的二分查找机制,如果消息的时间戳是乱序的(在使用Shared模式的Producer的情况下,这很可能发生), 可能会导致Expiry机制无法正确的移动游标,从而导致某些过期消息会被继续消费。如果遇到这种情况,可以通过设置
broker.conf 的brokerEntryMetadataInterceptors为org.apache.pulsar.common.intercept.AppendBrokerTimestampMetadataInterceptor解决;
- Expiry由定时任务驱动,因此它的精度会存在一定限制,无法保证100%准确。
四、总结
- Retention是Pulsar对于过期数据的保留和清理策略,它工作在Topic级别,通过定时任务清理过期数据,将全部Subscription都消费过后的数据从存储介质上删除来清理存储空间;
- Expiry即为Message TTL,它工作在Subscription级别,通过定时任务来检查Subscription中超时未消费的消息,并自动的将这些消息确认,使其对消费者不可见;
本系列下篇将为大家带来关于 Backlog quota 的解析,欢迎关注我们,第一时间获取相关动态;也欢迎加入社群讨论或在评论区留言,与我们交流更多关于 Pulsar 的问题。