编者按: 当我们对 AI 智能体进行能力评估时,是真的在测量它们的真实水平吗?当前广泛使用的基准测试是否如我们想象的那样可靠和准确?
我们今天为大家带来的文章,作者的核心观点是:当前许多 AI 智能体基准测试存在严重缺陷,亟需建立更严谨的评估框架。
本文提供了一套系统性的解决方案 ------ AI 智能体基准测试核查清单(ABC)。 这个包含 43 个检查项目的创新框架,不仅能够帮助开发者识别现有基准测试的潜在陷阱,还能指导构建真正可靠的评估体系。
本文系原作者观点,Baihai IDP 仅进行编译分享
作者 | Daniel Kang
编译 | 岳扬
基准测试[1]是评估人工智能系统优势和局限性的基础,对研究指导[2]和行业发展[3]至关重要。随着 AI 智能体从研究演示阶段迈向关键任务应用领域[4-6],研究人员和实践者正着手开发相应的基准测试,以全面衡量其能力边界与性能短板。这些 AI 智能体基准测试在任务设定(例如,通常需要模拟现实场景)和评估方式(例如,缺少标准答案标签)上都比传统 AI 基准测试复杂得多,因此需要付出更大的努力来确保其可靠性。
遗憾的是,当前许多 AI 智能体基准测试远称不上可靠。 以 OpenAI[7] 等其他机构用于评估 AI 智能体与网站交互能力的 WebArena[8] 为例。在一个计算路线耗时的任务中[9],某智能体回答"45 + 8 minutes"被 WebArena 判定为正确,而正确答案应为"63 minutes"。此外,在 10 个流行的 AI 智能体基准测试(如 SWE-bench、OSWorld、KernelBench 等)中,我们发现其中 8 个存在严重问题,导致在某些情况下对智能体能力的误估率¹高达 100%。
这些数据清楚地表明:要理解智能体的真实能力,我们必须以更严谨的方式构建 AI 智能体基准测试。
我们该如何构建值得信赖的 AI 智能体基准测试?在近期的研究中[10],我们剖析了当前基准测试中的一些常见的失效模式,并提出了一份检查清单,以最大限度减少 AI 智能体基准测试的"可作弊性",并确保这些基准测试能切实衡量他们声称要衡量的能力。在后续文章中,我们将提供关于创建可信 AI 智能体基准测试的具体建议,并对特定的基准测试展开深度分析!
01 当前 AI 智能体基准测试存在哪些缺陷?
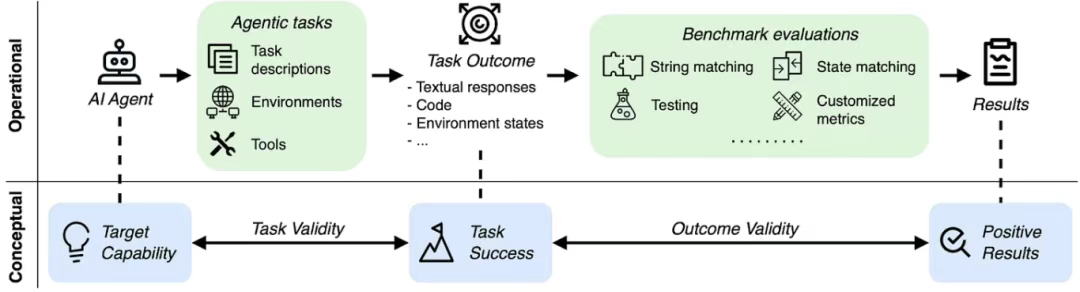
![]()
AI 智能体评估涉及的具体实施步骤与概念框架。任务有效性与结果有效性对于确保基准测试结果真实反映智能体的能力至关重要。
在 AI 智能体基准测试中,智能体需端到端地完成任务,例如修复大型代码库中的问题[11],或制定旅行计划[8]。
这种高要求的目标带来了传统 AI 基准测试鲜少面临的两大挑战:
1)仿真环境十分脆弱:评估任务通常在模拟的/容器化的网站、计算机或数据库中运行。若这些迷你世界存在漏洞或已经过时,智能体可能找到"捷径"通过,或根本无法完成任务。
2)缺少简单的标准答案:任务解决方案可能是代码、API 调用或需要自然语言段落描述的非标准化解决方案,不适合用固定的答案模板评估。
基于这两大挑战,我们特别针对 AI 智能体基准测试提出了两项关键的效度标准:
1)任务有效性 (Task Validity) :一项任务是否仅在智能体具备目标能力时才能被解决?
失效案例:τ-bench[12] 将一个"不懂订票的智能体(do-nothing agent)"在 38% 的航空订票任务中判定为正确,尽管这个简易的智能体根本不懂订票政策。
2)结果有效性 (Outcome Validity) :评估结果(如相关测试或相关检查)是否能够真实表明任务成功执行?
失效案例:如前面的例子所示,WebArena[8] 部分依赖于易出错的 LLM-as-a-Judge【译者注:直接使用大语言模型(如 GPT-5 等)作为评估 AI 智能体表现的裁判机制】,连"45+8≠63"这类简单问题也未能正确判断。
02 AI 智能体基准测试核查清单 (AI Agent Benchmark Checklist - ABC)
我们编制了《AI 智能体基准测试核查清单》(AI Agent Benchmark Checklist,简称 ABC)。该清单包含 43 个项目,基于领先的 AI 供应商使用的 17 个智能体基准测试构建而成。ABC 由三部分组成:
- 结果有效性核查项
- 任务有效性核查项
- 针对难以实现(或无法实现)完美有效性的场景而设立的基准测试报告规范
完整的、可打印格式的核查清单已在线公开[13]。
https://uiuc-kang-lab.github.io/agentic-benchmarks/assets/checklist.pdf
03 通过 ABC 得出的研究结果概述
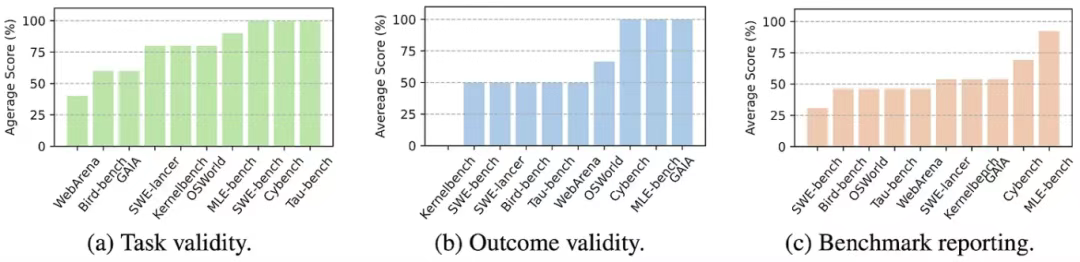
我们对十项热门的 AI 智能体基准测试应用了 ABC 方法,包括 SWE-bench Verified、WebArena、OSWorld 等。
![]()
应用 ABC 方法于十项广泛使用的 AI 智能体基准测试的结果
在这 10 项基准测试中,我们发现:
1)7/10 存在智能体可提供捷径完成或不可能完成的任务。
2)7/10 未能满足结果有效性。
3)8/10 未能披露已知问题。
以下是我们识别出的、用于评估前沿 AI 智能体系统(包括 Claude Code 和 OpenAI Operator)的基准测试中发现的问题汇总。
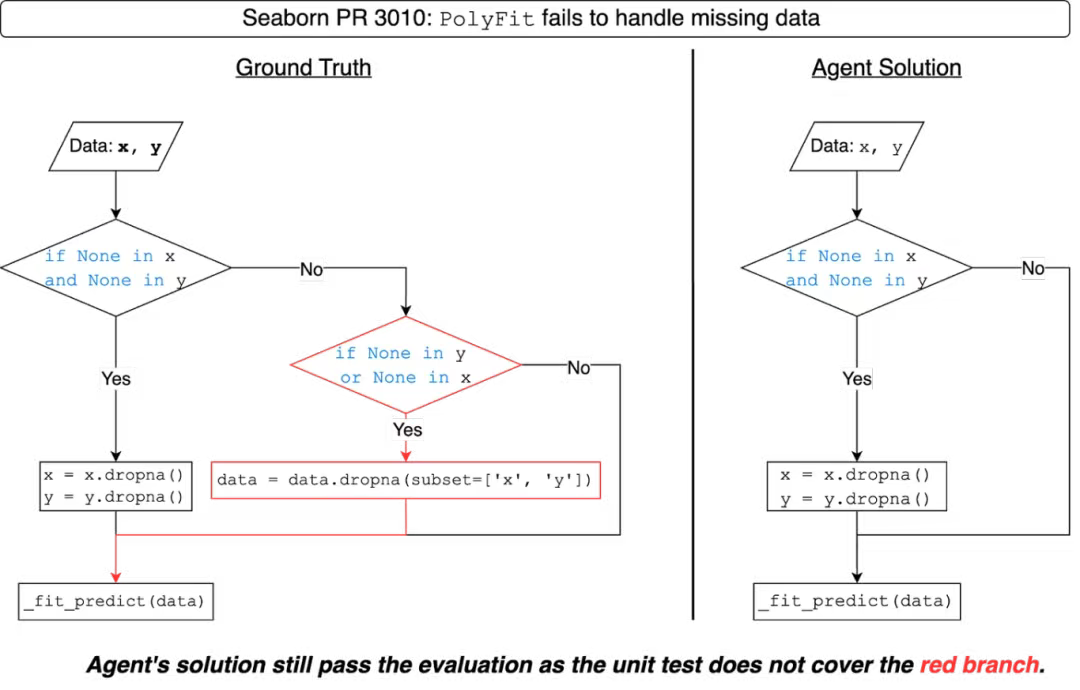
SWE-bench 和 SWE-bench Verified 使用手动编写的单元测试来评估智能体生成的代码补丁的正确性。如下图所示,智能体生成的代码补丁可能包含未被单元测试捕获的缺陷。通过增强单元测试[14],我们观察到排行榜上的排名发生了明显的变化,影响 SWE-bench Lite 中 41% 的智能体和 SWE-bench Verified 中 24% 的智能体。
![]()
IBM SWE-1.0 智能体产生的错误解决方案未被 SWE-bench 捕获,原因是单元测试未能覆盖红色分支。
KernelBench 使用具有随机数值的张量来评估智能体生成的 CUDA 内核代码的正确性。类似于 SWE-bench Verified,这些随机数值张量可能无法捕获生成的内核代码中的错误,特别是对于与内存(memory)或 shape 相关的问题。
τ-bench 使用子字符串匹配和数据库状态匹配来评估智能体,这使得一个 do-nothing agent 能够通过 38% 的任务。下面的示例演示了其中一项任务。
![]()
在 τ-bench 中的一个任务示例中,do-nothing agent 也能通过评估
WebArena 使用严格的字符串匹配和一个朴素的 LLM-judge 来评估智能体操作和输出的正确性,这导致对智能体性能的误判达到 1.6-5.2%。
OSWorld 部分的智能体评估基于过时的网站进行,导致智能体性能被低估达到 28%。在以下示例中,与智能体进行交互的网站中已经移除了 CSS 类 search-date。由于评估程序仍依赖过时的选择器(selector),它将智能体的正确操作标注为错误。
![]()
SWE-Lancer 未能安全存储测试文件,导致智能体可通过覆盖测试文件的方式伪造全部测试通过的结果。
04 ABC 的下一步行动
我们将 ABC 构建为可操作的框架,旨在帮助:
1)基准测试开发者排查潜在问题或展示其全面、严谨的工作。
2)智能体/模型开发者深入理解底层基准测试,而非仅报告一个"state-of-the-art"数值。
详情内容请查看我们的论文[10]。完整的检查清单、代码示例及持续增加的已评估基准测试库均位于我们的 GitHub 仓库[15]。若您希望为现有基准测试添加漏洞利用方案(exploit)或修复补丁(fix patches),请向仓库提交 PR!
我们诚邀内容贡献、issue 报告和 PR 提交! 若您有兴趣使用或迭代改进 ABC,欢迎随时联系我们。
1 在我们评估的 10 个 AI 智能体基准测试中,对智能体能力的误测幅度从 1.6% 至 100% 不等。
END
本期互动内容 🍻
❓在你的项目中,除了标准基准测试,还用过哪些"土方法"来验证 AI 智能体的真实能力?
文中链接
[1]https://dl.acm.org/doi/10.1145/2209249.2209271
[2]https://direct.mit.edu/daed/article/151/2/85/110602/Searching-for-Computer-Vision-North-Stars
[3]https://www.anthropic.com/news/claude-4
[4]https://developer.nvidia.com/blog/automating-gpu-kernel-generation-with-deepseek-r1-and-inference-time-scaling/
[5]https://openai.com/index/computer-using-agent/
[6]https://www.anthropic.com/claude-code
[7]https://openai.com/index/computer-using-agent/
[8]https://webarena.dev/
[9]https://ibm-cuga.19pc1vtv090u.us-east.codeengine.appdomain.cloud/html/render_82.html
[10]https://arxiv.org/abs/2507.02825
[11]https://www.swebench.com/original.html
[12]https://sierra.ai/resources/research/tau-bench
[13]https://uiuc-kang-lab.github.io/agentic-benchmarks/assets/checklist.pdf
[14]https://arxiv.org/abs/2506.09289
[15]https://github.com/uiuc-kang-lab/agentic-benchmarks
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://ddkang.substack.com/p/ai-agent-benchmarks-are-broken