作者:洪岩、等闲、陈才、刘军、王灏廷
Dify 是一个用于构建 AI 原生应用的开源平台,一个结合了后端即服务(BaaS)和 LLMOps 的综合性开发平台。由于其可视化的 AI 应用开发模式(支持聊天助手、工作流等)而获得了广泛的应用,受众群体包括开发者、运营、产品、公司人员等。
Spring AI Alibaba(SAA) 是一款以 Spring AI 为基础,深度集成百炼平台,支持 ChatBot、工作流、多智能体应用开发模式的 AI 框架。Spring AI Alibaba 提供了完全对等于 Dify 平台的应用开发能力,作为框架,它更强调用户基于 SDK 开发自己的应用。
在当前市场下,两款开源框架/平台分别有各自适用的开发场景,且都得到了开发者和企业的广泛采用。在这篇文章中,我们将深度讲解两个框架的结合:如何将在 Dify 平台上开发的应用导出为 Spring AI Alibaba 工程,至于为什么这么做?扩展性、性能、稳定性提升?请通过接下来的示例和企业实践测试数据了解详情。
通过一个示例了解如何从 Dify 生成 Spring AI Alibaba 工程
首先,我们会使用 Dify 平台提供的可视化界面快速的绘制一个叫做商品评价分类系统的示例应用。这是典型的低代码开发模式,通过 UI 界面、代码生成工具的支持,为用户快速搭建一个工作流应用提供有效支持。
使用 Spring AI Alibaba Studio 可以帮助我们将 Dify 等低代码开发平台上的可视化 AI 工作流一键导出为 Spring AI Alibaba 代码工程。
使用 Dify 绘制"商品评价分类系统"
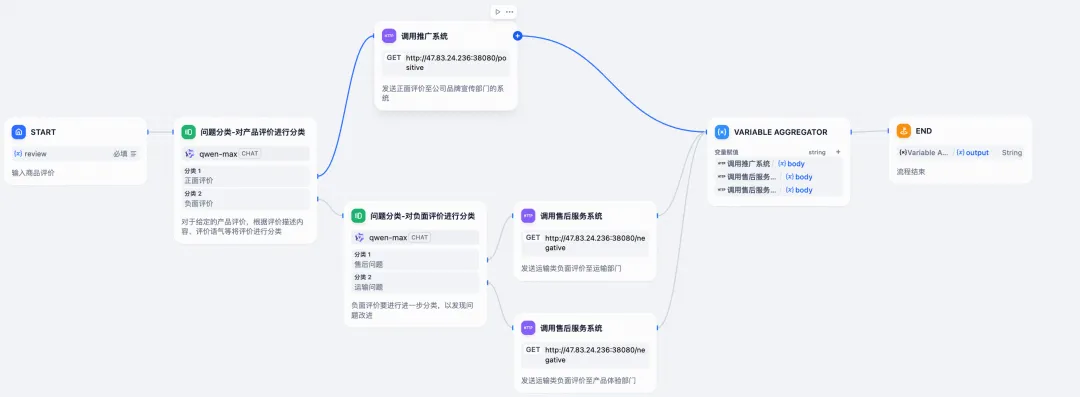
以下是使用 Dify 平台绘制的商品评价分类示例系统的流程图:
![]()
商品评价分类系统的基本逻辑如下,它根据用户提交的商品评论内容,自动进行问题分类,总共有两级问题分类:
- 第一级分类节点(feedback_classifier),将评论分为 positive 和 negative 两种。如果是 positive 评论则进行系统记录后结束流程;如果是 negative 评论则进行第二级分类。
- 第二级分类节点(specific_feedback_classifier),根据 negative 评论的具体内容识别用户的具体问题,如 "after-sale service"、"product quality"、"transportation" 等,根据具体问题分流到具体的问题处理节点。
- 最后问题处理节点进行处理并记录后,流程结束。
导出 Dify DSL 文件
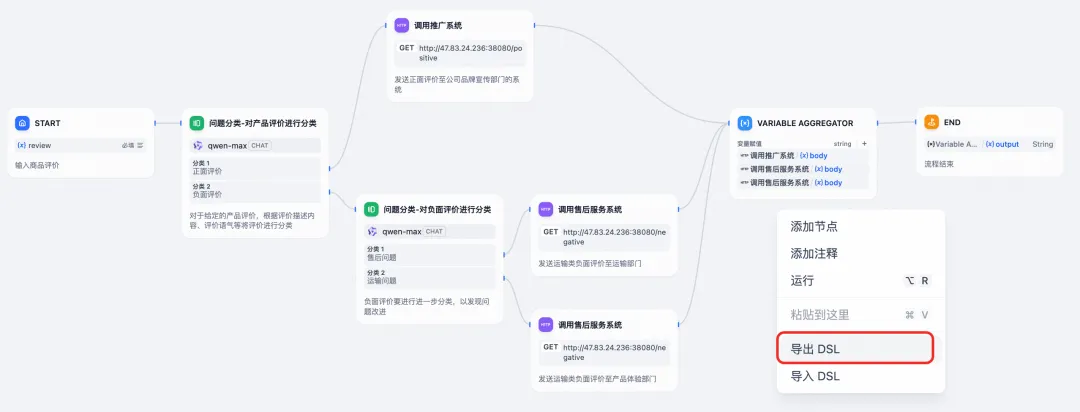
通过在 Dify 平台上测试业务系统工作正常后,我们接下来尝试将其导出为 Spring AI Alibaba 工程。
首先,第一步是导出 DSL 文件。
![]()
示例 DSL 文件格式样例如下:
app:
description: ''
icon: 💭
icon_background: '#D1E9FF'
mode: workflow
name: 客户评价处理工作流
use_icon_as_answer_icon: false
dependencies:
- current_identifier: null
type: marketplace
value:
marketplace_plugin_unique_identifier: langgenius/openai:0.0.26@c1e643ac6a7732f6333a783320b4d3026fa5e31d8e7026375b98d44418d33f26
kind: app
......
......
基于 DSL 生成 Spring AI Alibaba 工程
有了 DSL 描述文件后,借助 Spring AI Alibaba Studio 就可以快速生成 Spring AI Alibaba 工程。由于 Studio 相关脚手架页面还在开发中,我们可以通过以下命令行式指令快速体验 Studio 转换过程。
下载并运行 Studio 工具
git clone git@github.com:alibaba/spring-ai-alibaba.git
cd spring-ai-alibaba/spring-ai-alibaba-graph/spring-ai-alibaba-graph-studio
mvn spring-boot:run
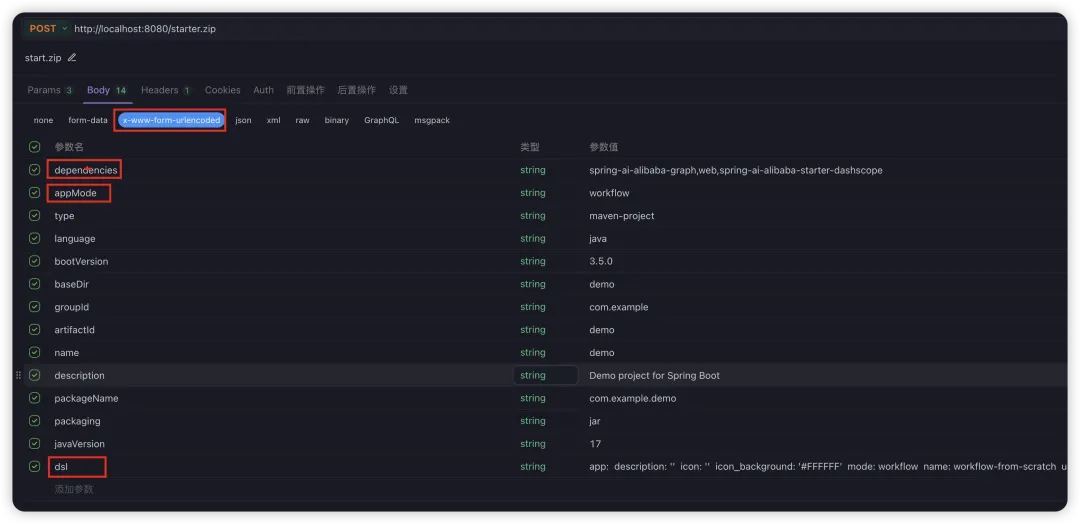
调用 studio api 完成转换
使用 postman 等工具调用刚刚启动的 Spring AI Alibaba Studio 服务,传入 DSL 文件内容并生成完整的 Spring AI Alibaba 工程。
![]()
将工程代码导入 IDE
解压 ZIP,编译并运行生成项目:
# 注意,这里的工程名称取决于您传入的参数,请根据需要调整
unzip workflow-review-classifier.zip && cd workflow-review-classifier
# 像其他 Spring AI Alibaba 工程一样,设置 API kEY 后就可以直接运行项目
./mvnw spring-boot:run
您也可以将生成的工程导入 IDE,项目大体结构如下。
![]()
从 Dify 迁移到 Spring AI Alibaba 的收益
通过将 Dify 可视化开发的应用转换为 Spring AI Alibaba,既能充分的利用 Dify 可视化界面高效搭建 AI 应用的优势,又能充分利用 Spring AI Alibaba 框架带来的灵活性与高性能,可以更灵活的应对更复杂多变的 AI 业务开发场景。
1. 扩展灵活度。 使用低代码平台的可视化 UI 界面可以快速的绘制工作流,将脑海中的思路变成可运行的 AI 系统,但低代码平台存在很多开发约束,这可能会给生产落地过程中带来改造成本或障碍。而使用 Spring AI Alibaba 开发的工程,开发者具备完全掌控权,因此对于任何功能几乎都不存在扩展障碍。有了这一套转换系统,开发者可以享受可视化绘制的便捷性,同时在转成代码工程后可享受开发、部署的灵活度。
2. 性能提升。 根据社区的初步压测效果,对比 Dify 平台的开发部署模式,使用 Spring AI Alibaba 部署的智能体应用,能带来至少 10 倍的性能提升(同时具备更大的调优空间)。
更广泛的适用场景
比如,对于以下场景,非常适合从 Dify 迁移到 Spring AI Alibaba 应用开发。
- 开发者或不熟悉开发的产品经理,使用 Dify 来快速验证业务想法,搭建出可以快速运行 AI 应用,大家可以在此基础上讨论与决策;而在进入真正的业务开发阶段时,利用一键导出能力快速生成 Spring AI Alibaba 应用,在此基础上继续调整和部署应用逻辑。
- 已经有使用 Dify 平台开发部署的应用,处于维护灵活度、语言栈、性能等方面的因素需要往代码态迁移,此时可以一键导出 Spring AI Alibaba 工程,大幅简化迁移成本。
相比 Dify 性能提升 10 倍
经过压测,与直接在 Dify 平台上运行 AI 应用相比,Spring AI Alibaba 应用在最大并发数、吞吐量、大流量场景下稳定性等方面均明显优于 Dify 平台。
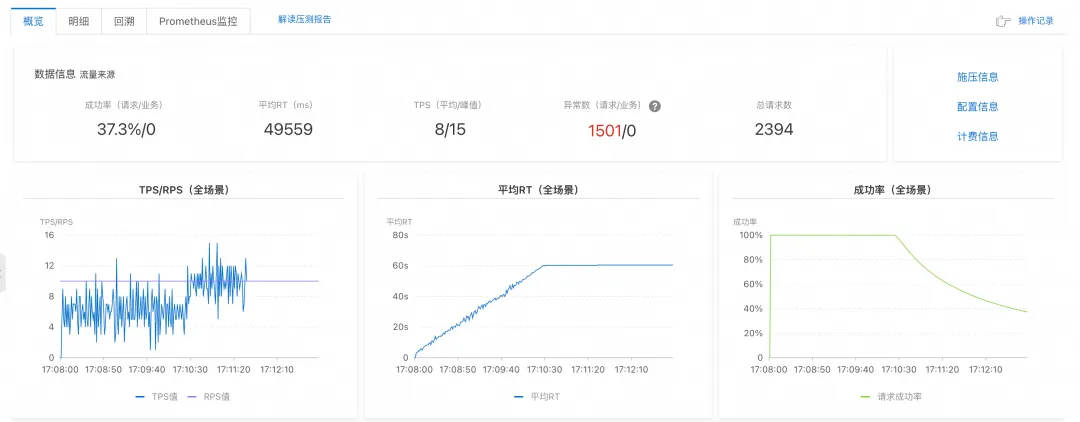
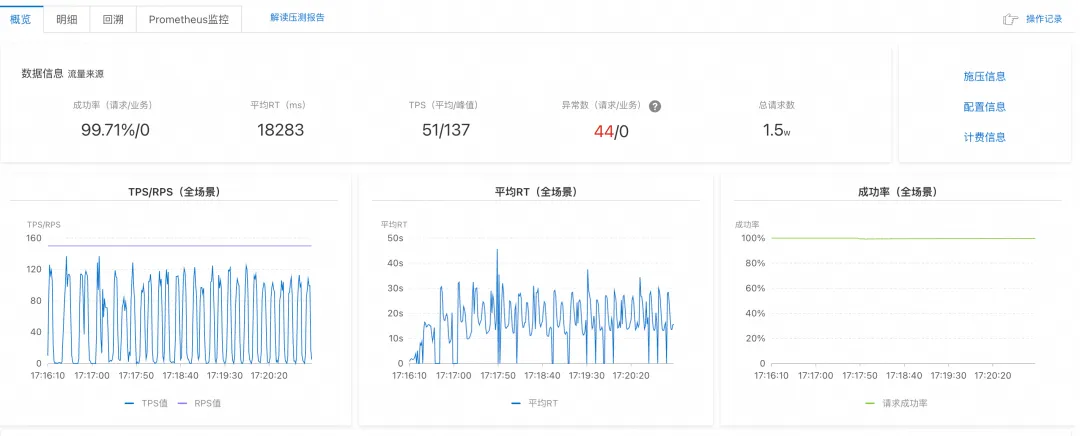
压测场景一:逐步加压最大 QPS
- 压测方式: 每个场景从 10 个 RPS(Request Per Second)开始,逐步提升,直到提升 RPS 值并不能带来 TPS 提升、成功率答复下降。
- 结论: Dify 能处理的上限 RPS < 10;Spring AI Alibaba 能处理的上限 RPS 约 150。
![]()
Dify 平台压测结果
![]()
Spring AI Alibaba 应用压测结果
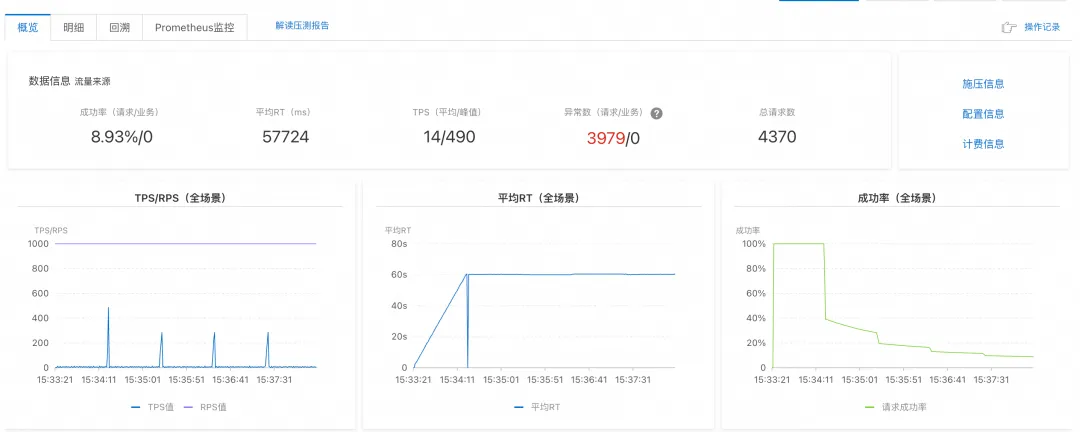
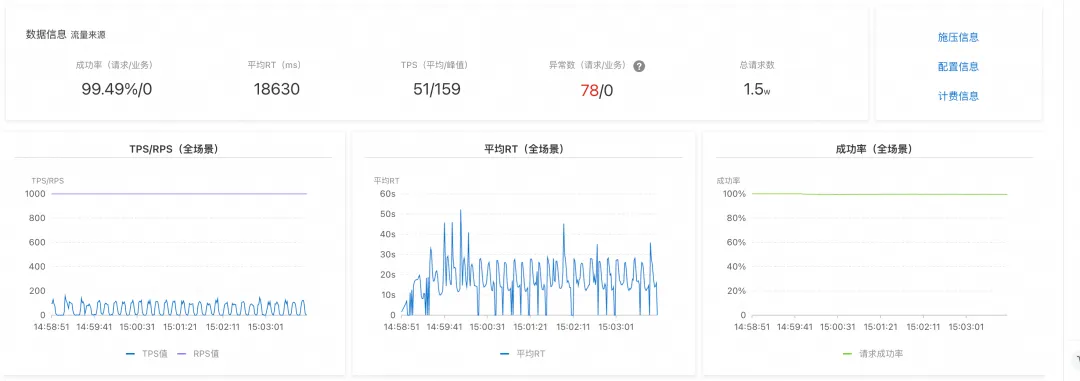
压测场景二:极限场景下的吞吐量与稳定性
- 压测方式: 给集群远高于合理并发的压测请求量(测试场景为 1000 RPS),看集群的吞吐量、成功率变化。
- 结论: Dify 在此场景下成功率小于 10%,平均 RT 接近 60s,大部分请求出现超时(响应大于 60s);Spring AI Alibaba 成功率变化不大,维持 99% 以上,平均 RT 也在 18s 左右。
![]()
Dify 平台压测结果
![]()
Spring AI Alibaba 应用压测结果
以下压测过程均使用两个框架/平台安装时的默认值,部署集群/实例规格如下:
-
SAA 工程:独立部署的容器,2个POD,规格 2C4G
-
DIFY 平台:官方部署方式,每个组件都拉起2个POD,规格 2C4G
更高的应用开发灵活性
毫无疑问,相比于在 Dify 平台上开发应用,使用 Spring AI Alibaba 开发应用将带来更高的灵活性、可扩展性,您将对自己的应用逻辑具备完全的控制权。
总结与未来规划
Spring AI Alibaba 定位为一款 Agentic AI 开发框架,通过简单的 API 降低复杂度、提升研发效率,使用框架可以快速开发包括聊天助手、工作流、多智能体等 AI 应用。
Spring AI Alibaba Studio 作为生态工具,可以进一步简化从应用原型搭建、Debug 调试到运行效果监控等多个环节。本文提到的 Dify 应用转换是 Studio 兼容计划中的重要一环,接下来 Spring AI Alibaba 会发布完整的可视化 Studio 模块,加速整个 Java Agent 体系开发效率,同时兼容 Dify、百炼等低代码开发平台。
相关链接
-
https://github.com/alibaba/spring-ai-alibaba
-
https://github.com/alibaba/spring-ai-alibaba/blob/main/spring-ai-alibaba-graph/spring-ai-alibaba-graph-studio/