准备出一系列故障定位的经验分享文章
-
-
-
-
-
-
故障定位系列-5-DB基本故障
-
故障定位系列-6-DB调用次数故障
-
故障定位系列-7-网络延迟类故障
-
故障定位系列-8-根因接口类故障
1 故障场景
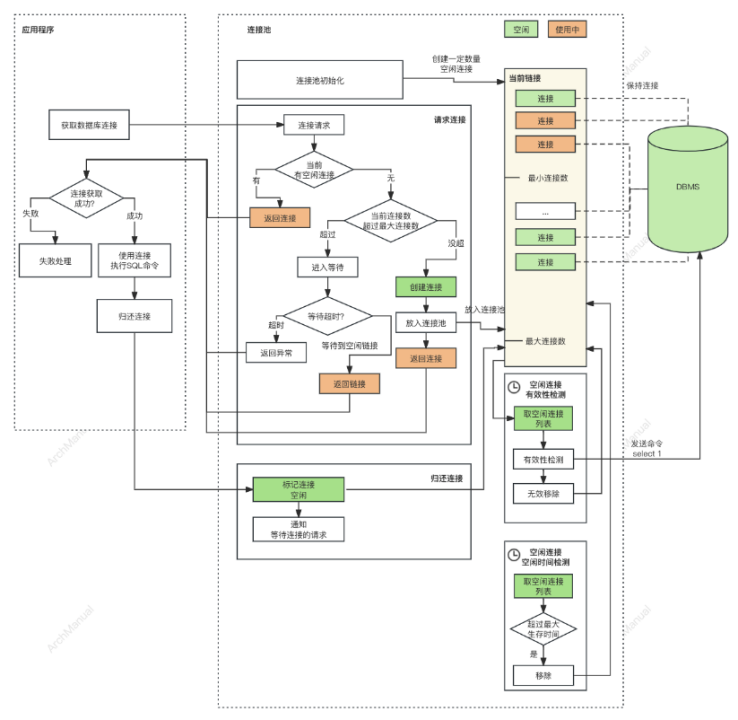
访问DB这个场景下到底有哪些故障呢?要想回答这个问题,我们必须研究下访问DB这个场景中各个环节,如下所示
![]()
主要有如下2个核心环节
-
从数据库连接池中获取连接
-
如果有空闲连接,直接返回该连接
-
创建新的连接,返回新的连接
-
超过连接限制,则锁等待空闲的连接,等待到则返回空闲连接
-
等待超时则抛出异常
-
连接池异步任务检查:对空闲连接进行有效性检查,如果不可用或者空闲时间过长则删除该连接
-
使用连接执行SQL命令
-
使用连接执行SQL命令
-
归还连接
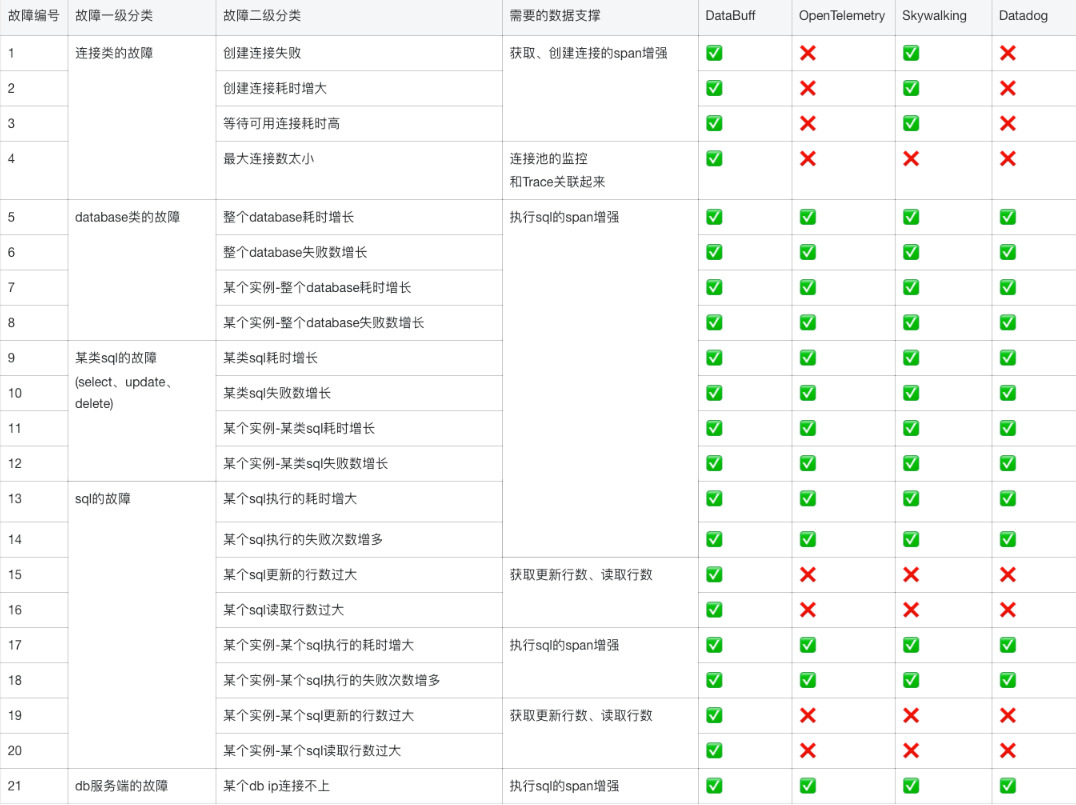
从上述2个核心环节中,总结出常见的故障案,及其所需要数据支撑例如下所示
![]()
2 定位难点
主要有如下2个难点
2.1 完善的数据采集和关联
比如案例场景:服务端mysql连接数增加限制,导致后续创建连接时失败,进而导致后续的sql都没执行
一些采集器比如OpenTelemetry和DataDog都没有去采集获取连接这一过程,那这一过程的故障案例自然是无法定位到的
比如案例场景:连接数控制的很低,在某次大查询时,并发度很高,连接数达到最大值无法创建,连接全部活跃,只能等待,进而造成整体响应时间变慢
这里就需要对某个数据库连接池的监控(比如最大连接数、活跃连接数等指标)、以及从这个连接池获取连接的监控紧密关联起来,从而达到因果可解释
比如案例场景:某次sql很慢,根本原因在于返回了1万条数据
这里就需要对每个sql的读取行数或者更新行数进行检测,这一点开源的基本都没有采集,自然也无法解释和定位
2.2 如何全面的覆盖上述故障案例
总结的最佳实践如下所示:
3 实战案例
我们到RootTalk Sandbox上进行上述故障场景的复现。
RootTalk Sandbox是一个故障演练和定位的系统,可以进行多种故障场景的复现,目前开放注册。
地址:https://sandbox.databuff.com
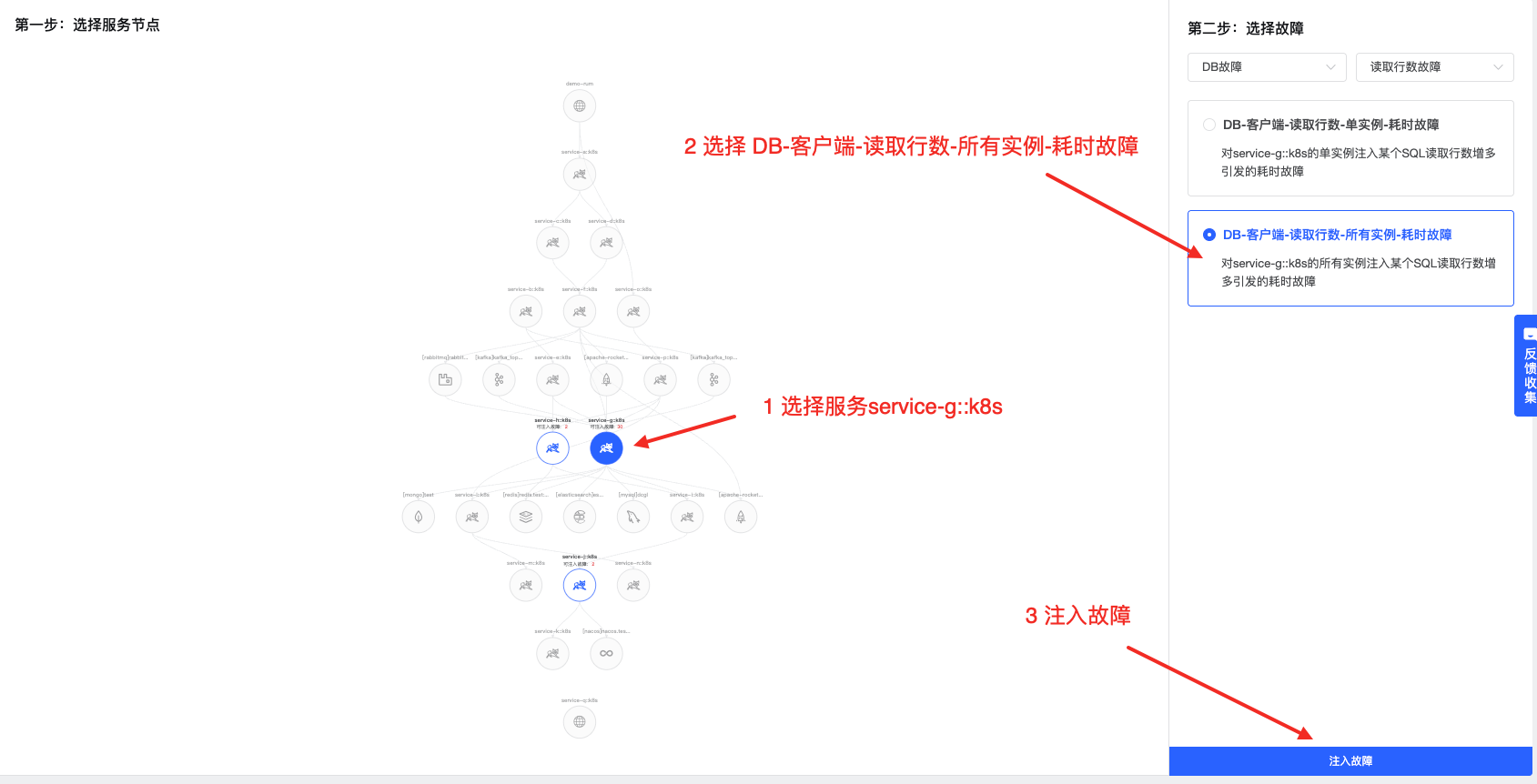
针对访问DB的2个核心环节,分别注入如下2个故障
3.1 故障注入-DB客户端-读取行数-所有实例-耗时故障
![]()
注入后等待2~3分钟,可直接点击跳转到Databuff的故障定位平台
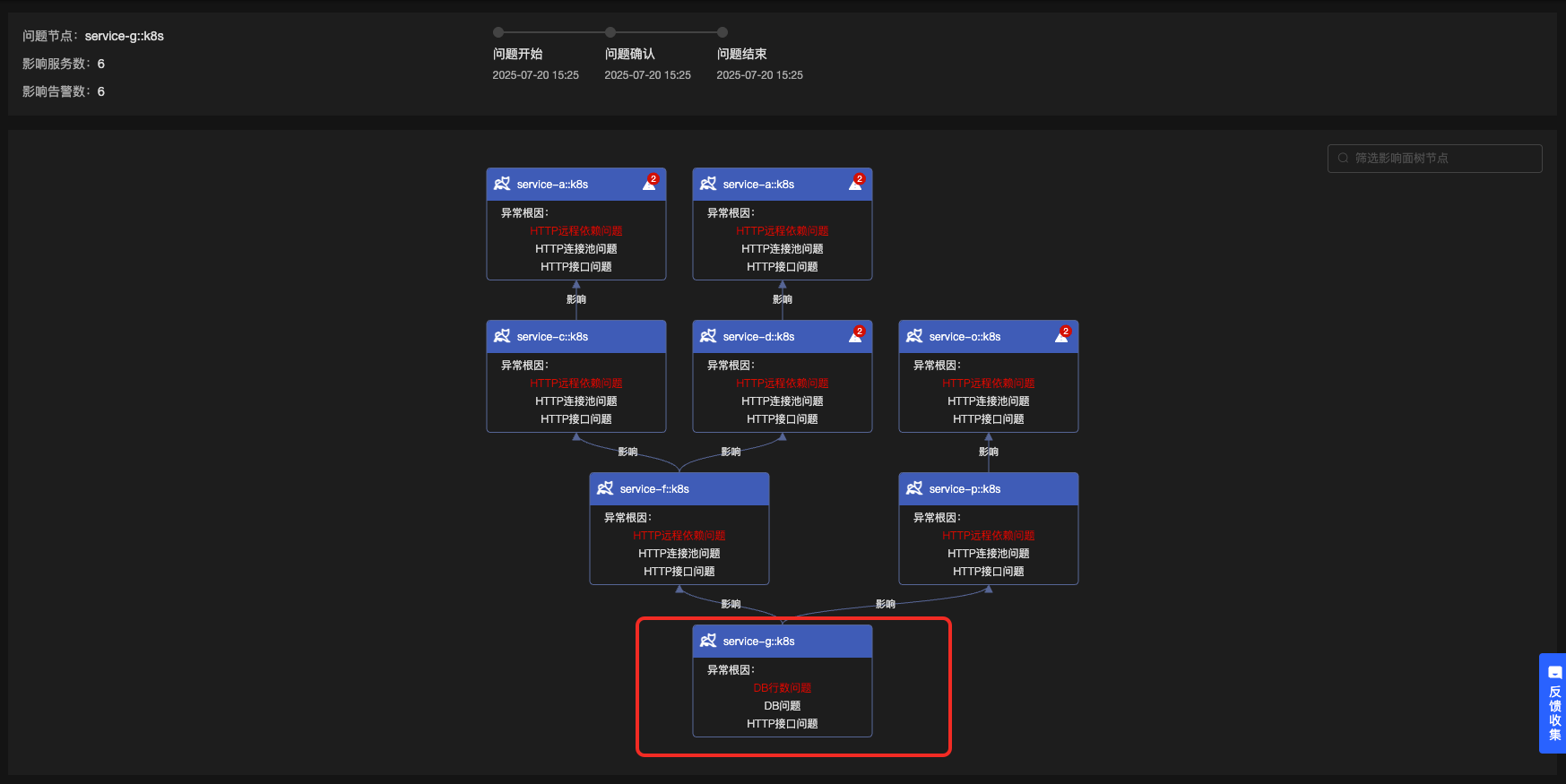
3.2 故障定位-DB客户端-读取行数-所有实例-耗时故障
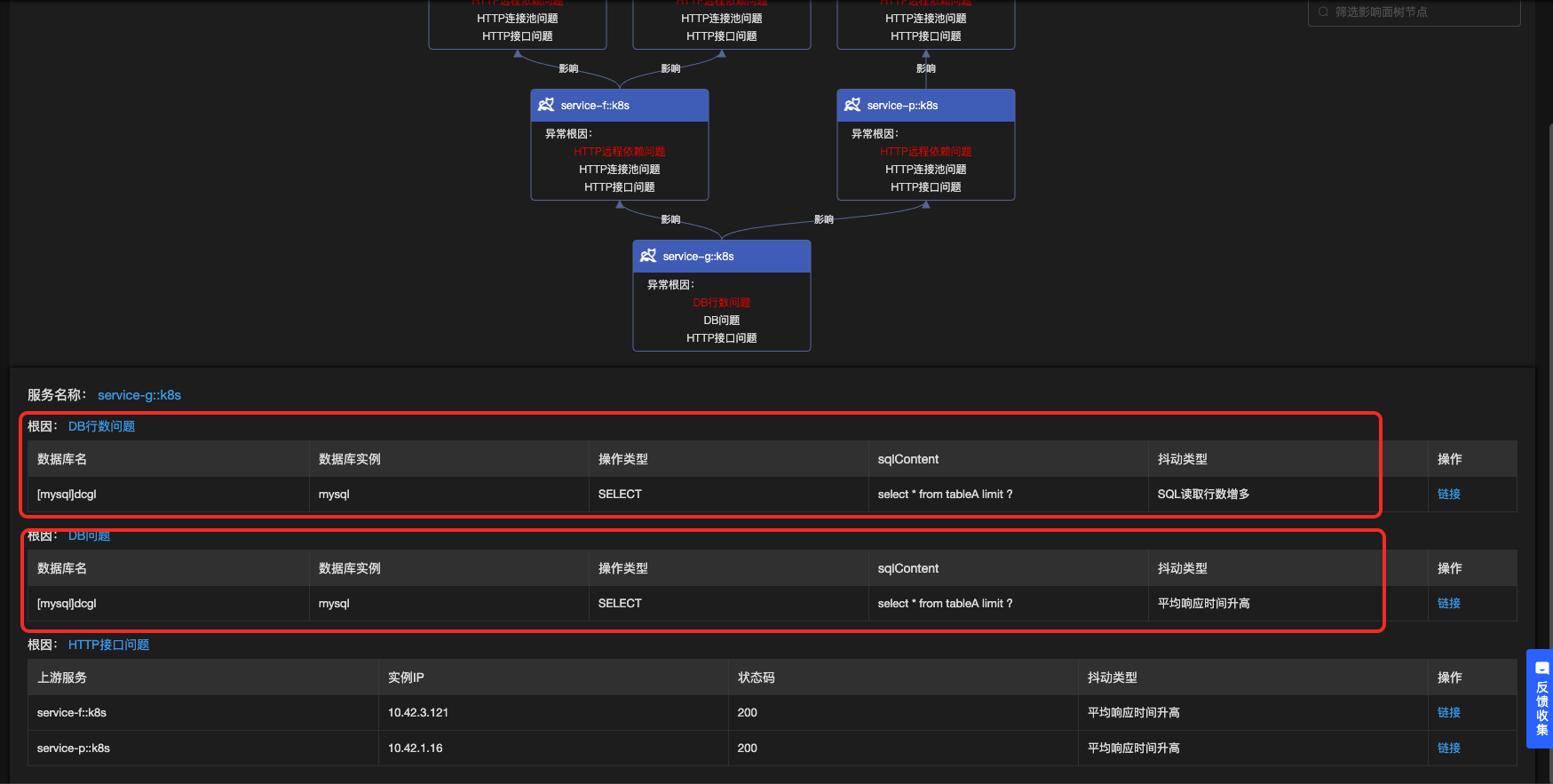
定位结果如下所示:
![]()
明确给出了是DB行数的问题,点击根因节点
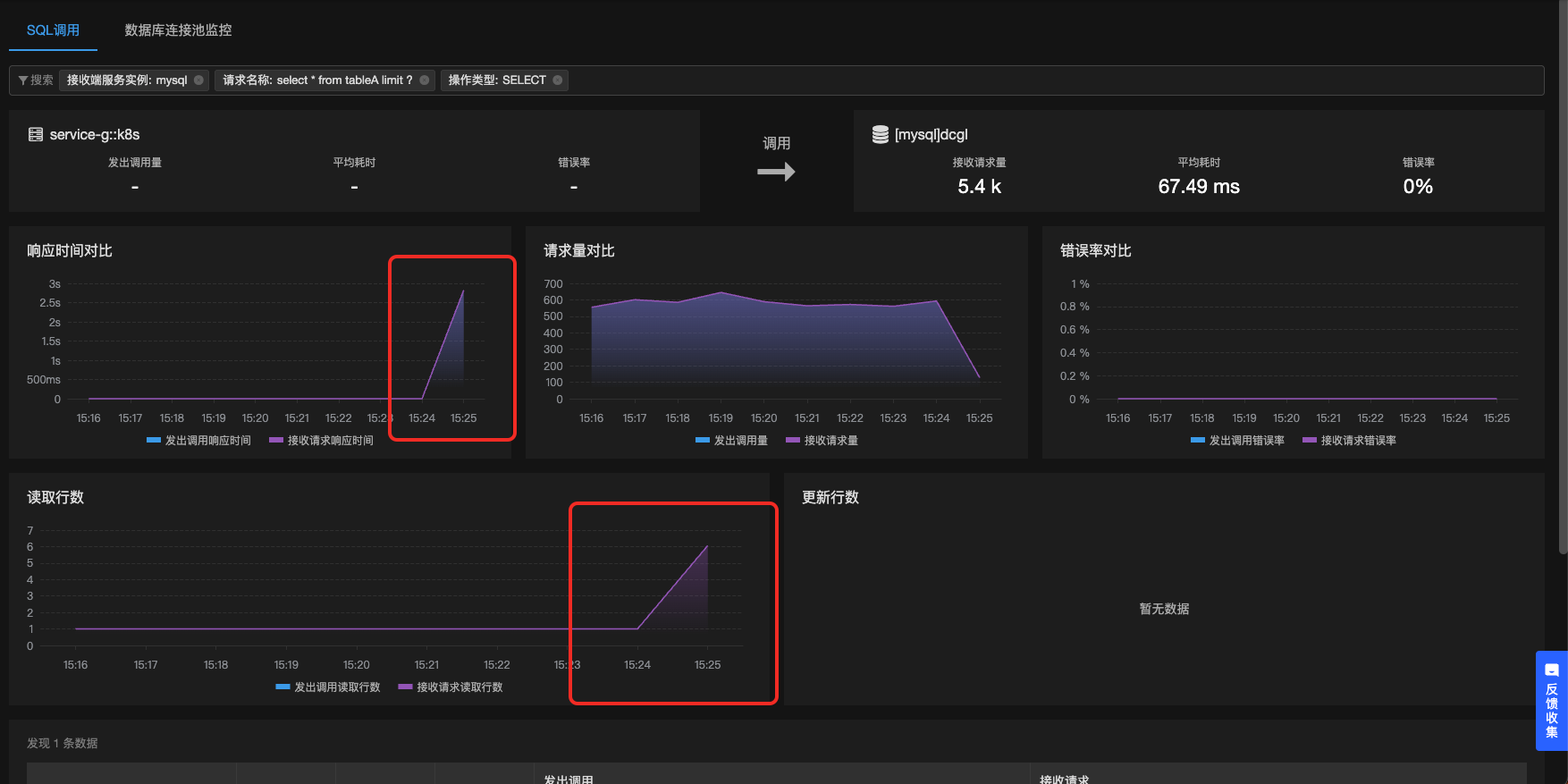
![]()
先解释了某个SQL耗时突增,然后又进一步解释了这个SQL耗时突增的原因是SQL读取行数增多导致的,点击上述连接可进一步验证
![]()
3.3 故障注入-获取连接耗时突增的故障
![]()
注入后等待2~3分钟,可直接点击跳转到Databuff的故障定位平台
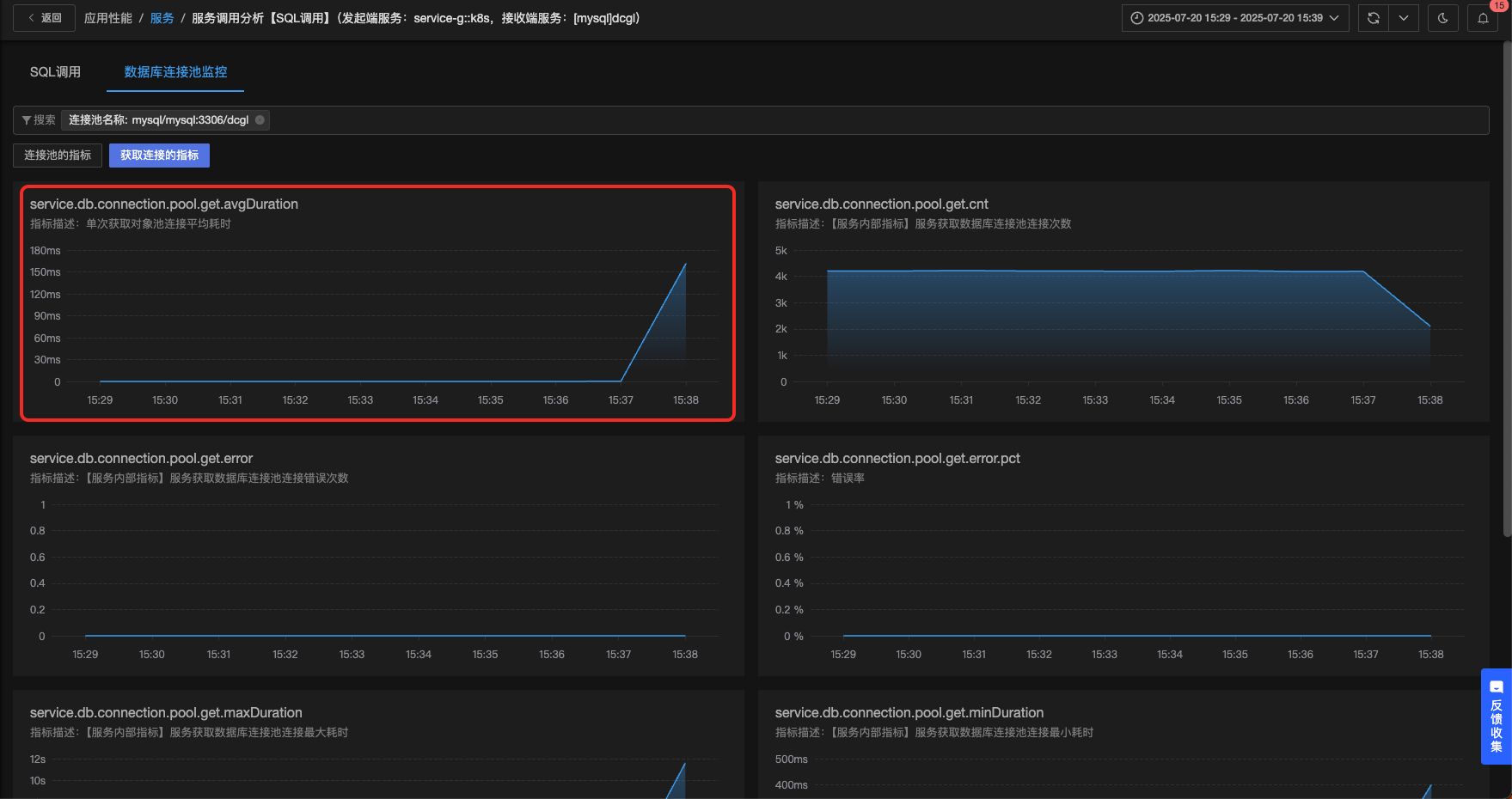
3.4 故障定位-获取连接耗时突增的故障
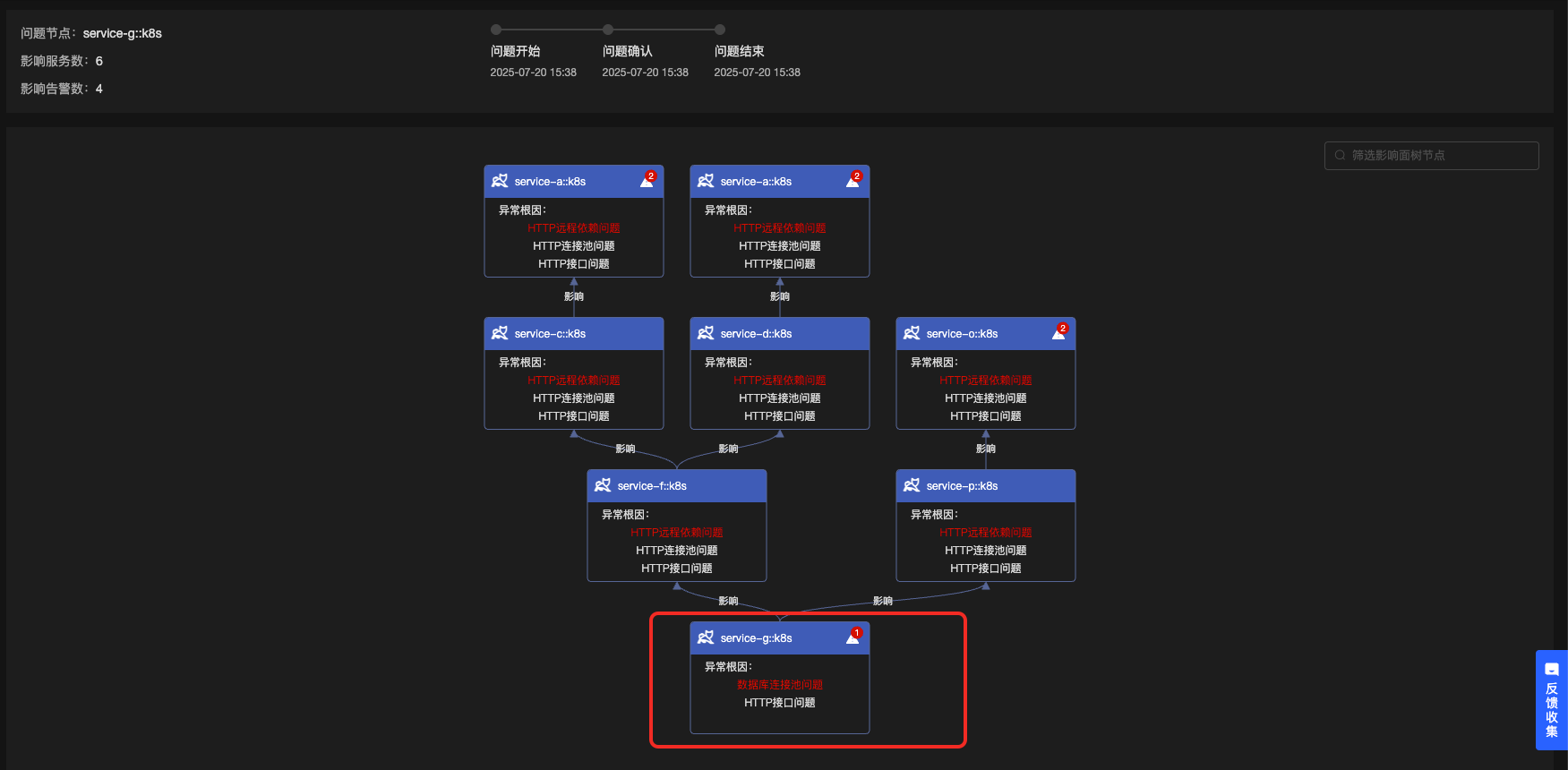
定位结果如下所示:
![]()
![]()
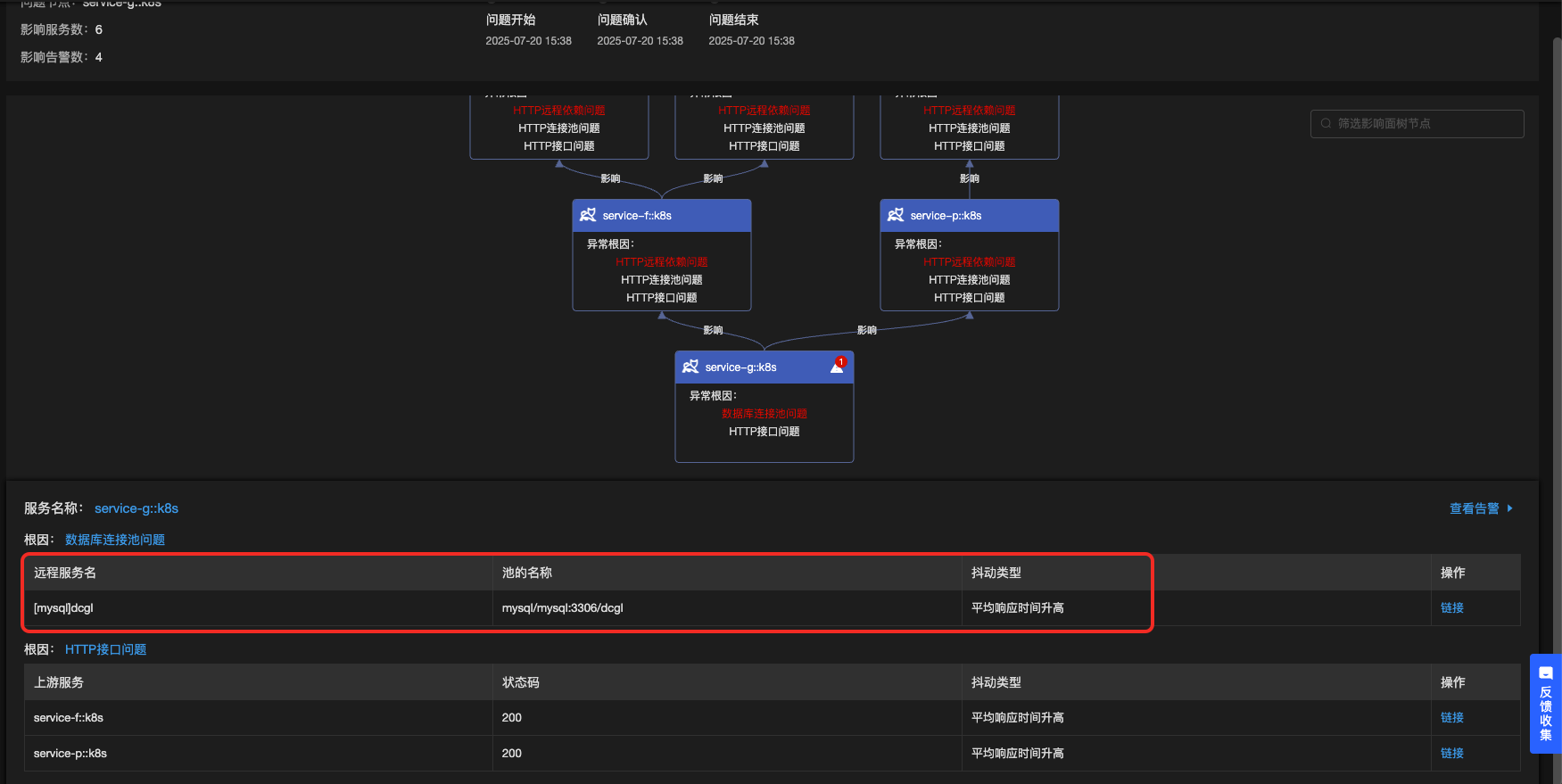
明确给出了这个数据库连接池获取连接耗时突增的问题,点击链接,可进一步验证结果
![]()
的确是获取连接的耗时突增了