此前,快手发布2025年一季度财报时,一个数字引发关注:成立仅两年的 AI 业务线“可灵 AI”单季度贡献营收1.5亿元,同比增长320%。而可灵 AI 正是一个多模态应用的典型产品,涉及到语言、视频、音频等交互。
前不久,在 OSCHINA 和小度教育技术负责人丁小晶的对话中。丁小晶表示,多模态技术非常重要,甚至可以说,没有多模态技术效果的快速提升,教育行业不可能如此迅猛发展。比如 AI 作业批改和 AI 讲题答疑方向的应用,完全靠纯文本大模型是无法满足需求的,非常依赖对大模型的图片理解能力。还比如超拟人 AI 老师,语音情感大模型就起来非常关键的作用。
百度最新发布的发布文心快码 Comate AI IDE 产品,其中也提到了多模态能力的增强,比如支持 Figma 设计稿一键转换为高可用代码,能实现图层的精准还原。百度工程效能部前端研发经理杨经纬告诉开源中国,无论是从自然语言、图片还是设计稿生成代码,最终都是为了能更加接近人类工程的意图,因为人类去描述自己想要实现的想法的方式与形态是多种多样的,也就对应了研发过程中的多模态形式。
![]()
人类从不会只用一种感官认知世界。人工智能也势必不能仅有一种交互途径。
我们闻到咖啡香气的瞬间,脑海里会立刻浮现深褐色液体与白瓷杯的画面;听到“猫”这个词时,脑海中自动补全毛茸茸的触感和呼噜声。这种多模态信息融合,正是人类智能的底层逻辑。而单一模态交换的 AI 模型的信息处理能力有限,例如文本生成模型难以理解图像语义,无法根据文字生成图像,视频生成工具则无法同步解析声音与画面逻辑。这种时候,就需要多模态模型或是能力的配合。
多模态,比文本慢一步
智源研究院院长王仲远不久前公开指出,当前多模态大模型的学习路径,尤其是多模态理解模型,通常是先将语言模型训练到很强的程度,再学习其他模态信息。在这个过程中,模型的能力可能会出现下降。
比单一模态更难的是,多模态模型还需解决一个核心问题:如何将图像、文本、音频等异构数据在语义层面对齐并融合。
文本、图像、声音等模态的数据结构天然异构——文本是离散符号序列,图像是连续像素矩阵,音频是时间序列信号。比如要让模型理解“猫”的文本描述与猫的图片、叫声之间的关联,需构建跨模态的共享语义空间。
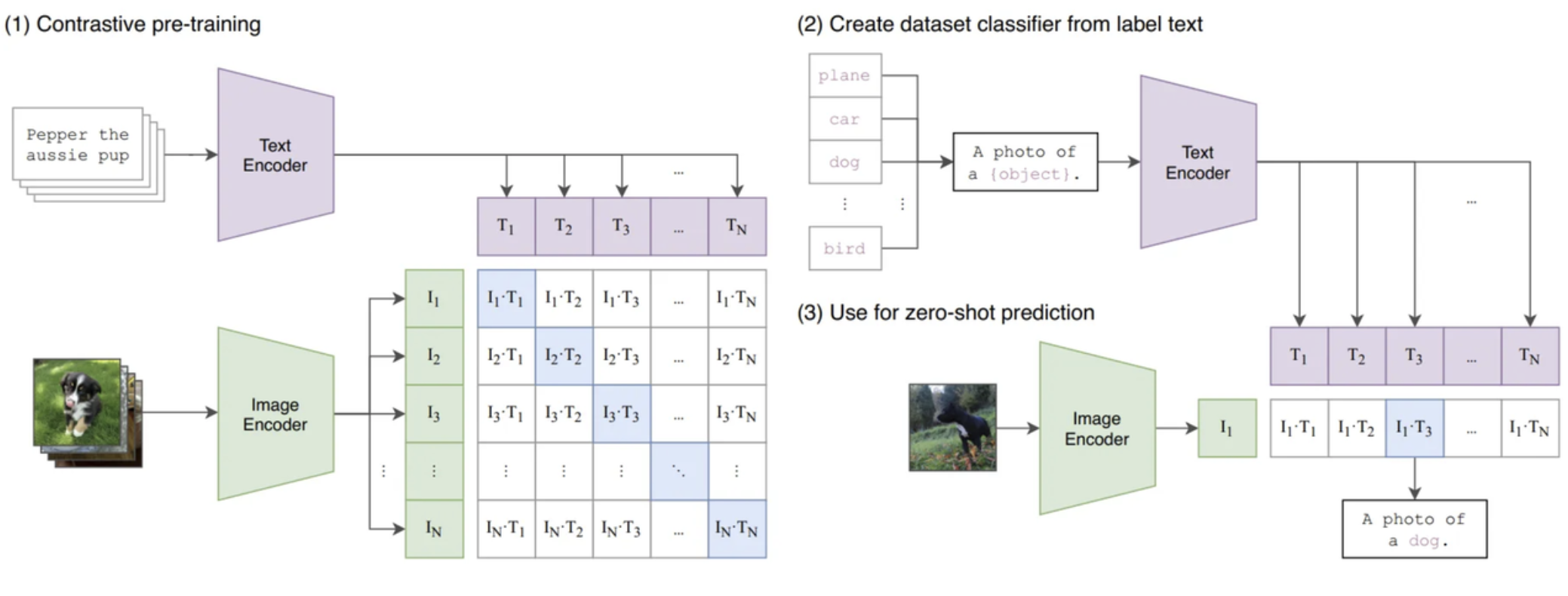
早期,有研究尝试通过数据级拼接,将图像像素和文本特征直接拼接,实现跨模态融合,但由于图像和文本的时空特性差异较大,导致特征对齐困难,最终效果不佳。直到对比学习和注意力机制的出现,才实现跨模态语义映射。比如 OpenAI 2021年推出的一种基于对比学习只的多模态预训练模型 CLIP,它通过大规模的图像和文本数据进行训练,使得模型能够理解图像内容和相关文本之间的语义关系。CLIP 的核心贡献在于它打破了传统的固定类别标签范式,通过对比学习的方式,将图像和文本映射到同一个向量空间中,从而实现跨模态的检索和分类。但是 CLIP 模型的训练数据规模庞大,据 OpenAI 披露,其使用了约 4 亿图像-文本对进行训练,训练成本高达数千 GPU 日,远超 GPT-3 等纯文本模型。
![]()
CLIP 模型方法概述 Learning Transferable Visual Models From Natural Language Supervision
多模态融合需处理高维数据,如4K视频的像素量是文本的百万倍,传统 Transformer 的二次方计算复杂度成为致命短板。对此,业界也有一些解决方式,比如此前 Mamba 架构通过状态空间模型 SSM 将计算复杂度降至线性,2025 年扩展动态融合模块 FusionMamba,在其中实现多模态特征高效交互,推理速度提升3倍。
不仅如此,相较于文本的资料库和数据集,高质量多模态数据集也更加稀缺,收集难度更大。比如医疗影像、工业质检的报告中的缺陷描述等,就需专家级别的标注人员。
落地需求更多
虽然技术上还有诸多难点,但是多模态能力正在逐步提升,并且带来非常可观的价值和效果。
比如,从图片或者是 Figma 设计稿直接生成代码可以帮助许多开发者或是产品经理完成一些开发工作。这项能力此前在一些低代码或是辅助编程工具中也存在,但往往是通过 Figma DSL 进行设计稿解析,通过节点虚拟化技术实现像素级还原,其不足在于不一定适配当前项目,比如转了一套 Vue 框架的代码,就无法在 React 框架项目中使用。
杨经纬介绍,此次文心快码 Comate AI IDE 的发布以及相关功能更新后,通过大模型能力增强了 Figma to Code 和当前项目的融合度。首先在 IDE 里进行操作,天然就可以理解用户当前环境和本地优势,而 IDE 内智能体 Zulu 的接入,会更深入到本地项目中了解当前的框架、能力、代码风格等,再结合 Image to Code 的能力,可以实现较高的还原度,并且适配当前的项目。
而根据一些公开信息显示,可灵 AI 的多模态技术,支持通过图片、文字、声音甚至手绘轨迹等输入生成视频。在上半年的2.0模型的迭代中,可灵 AI 也发布了 AI 视频生成的全新交互理念 Multi-modal Visual Language(MVL),让用户能够结合图像参考、视频片段等多模态信息,将脑海中包含身份、外观、风格、场景、动作、表情、运镜在内的多维度复杂创意,直接高效地传达给 AI。MVL 由TXT(Pure Text,语义骨架)和 MMW(Multi-modal-document as a Word,多模态描述子)组成,能从视频生成设定的基础方向以及精细控制这两个层面。此外,其技术也结合了类 Sora 的 DiT 结构和 Flow 扩散模型,提升在物理模拟和细节上的表现。
基于这些技术特征。商业化层面,截至今年6月,可灵 AI 已为超过1万家企业客户提供 API 服务,覆盖广告营销、影视动画等领域,企业客户续费率较高。
此外,一些传统行业或场景也在结合多模态能力,实现与 AI 的加速融合。比如迪瑞医疗近期采用的多模态 AI 大模型算法技术为临床诊断带来了重要的技术革新,结合多种检测结果和患者的多维信息,如尿常规、血常规、生化和化学发光免疫,以及患者的个人背景、临床表现、现病史与既往病史等,进行全面分析。
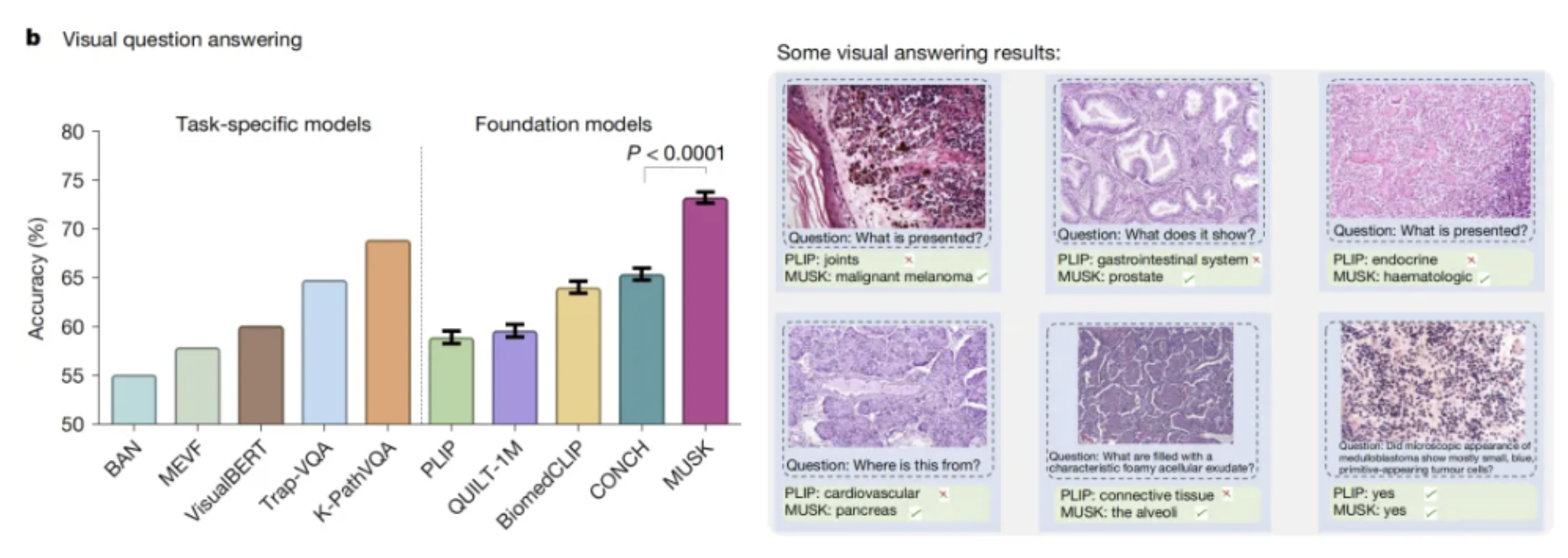
这种跨学科的信息整合使得诊断提示更加精准,对于减少漏诊、误诊的概率具有显著的作用,并进一步提升了医疗诊疗的整体效率。大洋彼岸,斯坦福医学院的科研团队研发出了一种名为 MUSK 的 AI 模型,将视觉数据,如病理图像和文本数据的病历和临床记录相结合,为癌症治疗带来了新的可能。MUSK 模型不仅提高了预测癌症患者预后和治疗反应的准确性,而且通过分析数千个数据点,更准确地确定了哪些疗法对个体患者最有效。
![]()
视觉问答测试,图片来源于网络
在金融领域。江苏银行通过本地化部署微调 DeepSeek-VL2多模态模型、轻量 DeepSeek-R1推理模型,分别运用于智能合同质检和自动化估值对账场景中,通过对海量金融数据的挖掘与分析,重塑金融服务模式,实现金融语义理解准确率与业务效率双突破。具体而言,DeepSeek-VL2多模态模型采用了最新的Transformer架构,结合多层次的特征融合机制,有效提升了金融合同、账单等复杂文本与图像信息的理解能力。模型在智能合同质检场景中表现出色,准确率较传统方法提升了15%以上,显著降低了人工审核成本。同时,轻量化的DeepSeek-R1推理模型则在自动化估值与对账场景中展现出极佳的实时响应能力,推理速度提升了30%,为金融业务流程的自动化提供了坚实支撑。
新的基础设施
应用边界在不断拓宽的同时,多模态模型的能力也在成长。
而随着应用场景的深化,模型架构也在同步进化,从基础感知迈向复杂推理成为必然趋势。OpenAI 在2025年4月发布了多模态模型O3和O4-mini,实现了“用图像思考”的突破性能力。这些模型不仅能够识别图像内容,还能将图像信息整合进推理思维链,支持多步推理和因果分析,比如够处理模糊、倒置或复杂的图像输入,并给出合理的推理结果。
其背后的关键技术包括分层注意力机制,将图像分解为局部细节、全局关系和时序逻辑三层结构,从而提升对图像内容的理解能力;动态工具链调用,在推理过程中,模型可以自主选择Python分析、知识图谱检索、图像生成等工具辅助决策,以及安全约束模块,通过对抗训练减少模型的幻觉输出。
就在本月,中国科学院自动化研究所等单位的科研人员首次证实,多模态大语言模型在训练过程中自己学会了“理解”事物,而且这种理解方式和人类非常像。
科研人员借鉴人脑认知的原理,设计了一个巧妙的实验:让大模型和人类玩“找不同”游戏。实验人员会给出三个物品概念(选自1854种常见物品),要求选出最不搭的那个。通过分析高达470万次的判断数据,科研人员绘制出了大模型的“思维导图”——“概念地图”。通过实验证实多模态大模型具备类人“概念理解”能力。研究团队设计“找不同”游戏,基于470万次判断数据绘制大模型“概念地图”,提炼66个理解维度(如物体功能、文化意义),发现其与人脑神经活动高度一致,证明多模态模型比纯文本模型更接近人类思维模式。
据谷歌云在2024年年底发布的《2025年人工智能商业趋势报告》,预测到2025年,多模态 AI 将成为企业采用 AI 的主要驱动力。这种技术通过整合图像、视频、音频和文本等多种数据源,使 AI 能够以前所未有的准确性从更广泛的上下文源中学习,提供更精确、定制化的输出,创造自然直观的体验。报告预计,全球多模态 AI 市场规模将在2025年达到24亿美元,到2037年底达到989亿美元。
2025 进度已经过半,我们也能看到市面上许多多模态技术和产品的进展,而这场变革的终极图景,或许正是让 AI 真正成为理解世界、服务人类的“多模态智能伙伴”。