导语
2025年6月起,腾讯云 TDMQ RabbitMQ 版正式推出 Serverless 版本,该版本基于自研的存算分离架构,兼容 AMQP 0-9-1 协议和开源 RabbitMQ 的各个组件与概念,且能够规避开源版本固有的不抗消息堆积、脑裂等稳定性缺陷,具有稳定、安全、灵活扩缩容等优势。本文将全面解析 TDMQ RabbitMQ Serverless 版的核心特性、技术优势及售卖形态。
TDMQ RabbitMQ Serverless 版推出的背景
2021年,腾讯云推出自研消息队列服务 TDMQ RabbitMQ 版,全面兼容 AMQP 0-9-1 协议及开源 RabbitMQ 生态。产品以开源托管版形态提供服务,按照节点进行售卖。
相比传统自建方案,TDMQ RabbitMQ 开源托管版不仅免除了用户部署运维的负担,并通过架构优化实现了跨可用区高可用部署、一键弹性扩缩容等生产级能力,同时内置了完善的监控告警、巡检诊断等企业级运维功能,在保持协议完全兼容的基础上,针对企业实际应用场景进行了深度优化,为用户提供了更稳定可靠的消息服务体验。
在当前数字化转型加速的背景下,用户对成本优化提出了更高要求,同时业务快速迭代也催生了对弹性能力的强烈需求。用户极需突破传统资源预留式运维的局限,充分释放云原生的技术红利。
为更好地满足用户对弹性扩展和成本优化的需求,腾讯云消息队列 TDMQ RabbitMQ 版正式推出 Serverless 版本。该版本采用存储和计算分离的架构设计,在完全兼容 AMQP 0-9-1 协议及开源 RabbitMQ 生态的同时,有效规避了开源版本固有的不抗消息堆积、脑裂等稳定性缺陷,又解决了开源版本性能受限于底层机型和扩展性不足等问题,为用户提供更安全可靠、弹性灵活的消息服务体验。
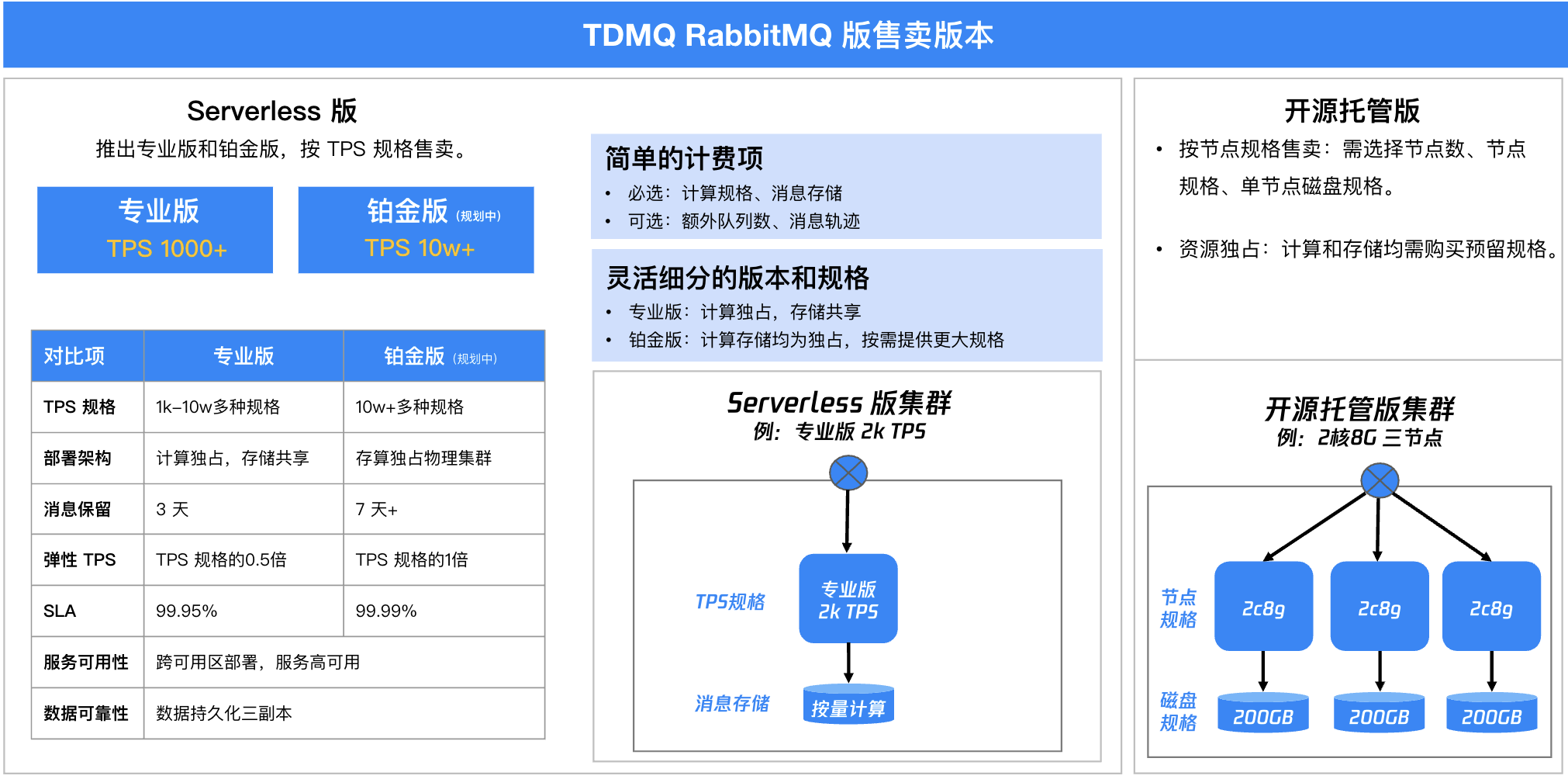
在产品设计上,Serverless 版本提供专业版(1000+ TPS)和铂金版(10w+ TPS)两种规格,用户只需根据业务吞吐量需求选择对应版本,无需关心底层资源运维。在计费模式上,同时支持包年包月和按小时计费两种方式,其中计算资源按流量规格计费,存储资源无起步门槛,按实际使用量进行计费,成本整体可降低约 30%。
TDMQ RabbitMQ Serverless 版核心特性解析
1、 兼容开源、开箱即用
支持开箱即用,一键自动创建集群,无需手动安装和部署。兼容 AMQP 0-9-1 协议及开源 RabbitMQ 客户端,业务代码无需任何改造即可平滑上云。同时提供多种 TPS 规格供用户选择,用户可以在控制台上自助灵活扩容和缩容,无需关注底层资源。
2、 可观测能力增强
提供全面的监控告警能力,支持集群、VHost、Exchange 和 Queue 4 个维度,覆盖 6 大类、90+ 细粒度监控指标,帮助您实时了解集群运行状态。同时支持消息查询和消息轨迹能力,清晰展示消息的完整生命周期,便于快速定位问题,提升运维效率。
3、 高可用高可靠
通过架构升级有效解决了开源版本常见的稳定性问题,包括消息堆积和脑裂等场景。服务采用多可用区分布式部署架构,可自动容灾切换,轻松应对机房级故障,提供不低于 99.95% 的 SLA 服务可用性保障。同时通过三副本数据持久化机制,确保消息数据的持久可靠。
4、 灵活适配多业务场景
提供多种路由方式,例如 Direct、Fanout、Topic、 Header 和 X-Delayed-Message 等,可灵活组合不同的交换机类型,满足复杂业务需求。同时支持多种消息类型,例如广播消息、延迟消息、死信队列等,满足订单超时处理、事件通知、异步解耦等典型业务场景,提供高度灵活的消息解决方案。
TDMQ RabbitMQ Serverless 版对比开源的八大关键优势
1、监控告警丰富度高
开源自建 RabbitMQ 方案需通过 Management UI 手动采集指标,并自行搭建指标存储和展示系统;或者通过接入外部 Prometheus 和 Grafana 实现监控指标展示,运维难度和成本显著增加。
而 TDMQ RabbitMQ Serverless 版提供白屏化监控大盘,支持集群/VHost/Exchange/Queue 4个监控维度,涵盖6大类,90+ 指标,实时了解集群运行状态,提升自主运维效率。
2、支持全链路消息轨迹
开源自建 RabbitMQ 方案需要在服务器里的 log 文件中查询文本格式的消息轨迹信息,查询和定位问题效率较低。
TDMQ RabbitMQ Serverless 版支持通过 Message ID 精准查询或按队列检索消息,并且可以可视化展示消息完整生命周期,快速定位消息收发问题。
3、 灵活无感扩缩容
传统开源的 RabbitMQ 方案扩缩容需要停机升级底层机型,并需要重启开源控制台,操作复杂且影响业务连续性。
TDMQ RabbitMQ Serverless 版支持灵活扩缩容,通过控制台简单操作即可实现资源扩展,变更过程平滑无感,客户侧的应用无需做停机处理。
4、 消息抗堆积能力强
开源自建 RabbitMQ 集群抗消息堆积能力较弱,容易因消息堆积导致内存过载,需人工干预。
TDMQ RabbitMQ Serverless 版采用高性能架构,具备强大的抗堆积能力,即使在高并发消息堆积场景下,仍能保持稳定的吞吐性能,避免消息积压导致的服务不可用风险。
5、 默认支持跨可用区容灾
传统开源的 RabbitMQ 方案存在固有的不抗消息堆积和脑裂等架构风险,且单可用区部署模式难以保障故障出现时的业务连续性。
TDMQ RabbitMQ Serverless 版默认跨可用区部署,确保服务的高可用性。采用先进的存算分离架构,规避不抗消息堆积和脑裂问题,既保证集群高可靠和数据持久化,又具备灵活扩缩容优势。承诺不低于 99.95% 的服务可用性 SLA,为用户提供强有力的稳定性保障。
6、 可无限横向扩展
开源 RabbitMQ 集群的队列和单节点绑定,受限于单机硬件配置,镜像队列副本数量增多会降低集群 TPS 值,增加节点不能扩展集群吞吐量。
TDMQ RabbitMQ Serverless 版通过存算分离架构,突破了传统方案的性能瓶颈,理论上支持无限 TPS 扩展能力,服务可按需横向扩容,为业务增长提供持续的性能保障。
7、秒级精度延时消息
开源 RabbitMQ 通过延时消息插件实现,该开源插件设计存在局限性,不适用于大量延时消息或长时间延时消息的场景,集群节点异常时会导致延时消息丢失,还存在不支持强制标志等问题。
TDMQ RabbitMQ Serverless 版免去开启延时消息插件的步骤,直接对消息设置 delay 属性即可,不仅便捷,还可以解决开源实现方式的局限性,支持长时间、大量的延时消息,且海量消息堆积不影响集群高可用。
8、灵活消息重试策略
开源 RabbitMQ 默认只支持消息无限立即重试机制,需要开发者自行实现重试逻辑,消费失败的消息需人工定位原因,开发和运维成本高。
TDMQ RabbitMQ Serverless 版默认支持消息重试策略,当消息消费达到"消费超时时间"而消费者还未响应时,消息将被重新投递,并且支持不同的重试间隔,当重新投递次数达到上限时,消息会被投递到死信队列或者被丢弃。
TDMQ RabbitMQ Serverless 版售卖形态
当前 TDMQ RabbitMQ Serverless 版提供专业版和铂金版两种规格,以满足不同业务场景的需求,按照 TPS 规格对外售卖。
![]()
在性能方面,专业版支持消息 TPS 在1000到10万之间的多种规格,铂金版则提供更高的规格,支持10万 TPS 以上的消息处理能力。
在部署架构上,专业版计算资源是独占的,但存储层是共享的;而铂金版提供完全独占的计算和存储资源,相比专业版稳定性会更强。
消息保留时间方面,专业版默认支持3天的消息保留时间,铂金版则支持7天以上,满足更严格的数据留存需求。
服务可靠性方面,两个版本均采用跨可用区部署架构,并配备三副本数据持久化机制。专业版提供99.95%的 SLA 保障,与开源托管版持平;铂金版则承诺更高的99.99%服务可用性,为关键业务提供更强保障。
后续我们还将推出弹性 TPS 功能,允许用户在购买的基础 TPS 规格范围上可以超出一部分用量。对于超出基础规格的部分,按照实际使用量进行独立计费。具体弹性扩展空间方面,专业版最高可支持超出基础规格的50%,铂金版则支持100%的超量扩展,为用户业务的突发激增流量提供保障。
总结与展望
腾讯云推出的 TDMQ RabbitMQ Serverless 版基于自研的存算分离架构,有效兼容开源生态并解决了其固有稳定性问题(如脑裂、不抗堆积),提供高可用、弹性扩缩和按量计费的核心优势,同时大幅增强监控告警、消息轨迹等可观测能力,显著简化运维负担。
未来腾讯云 TDMQ RabbitMQ Serverless 版将持续优化,推出弹性 TPS 功能以更好应对突发流量,同时做好开源兼容性增强、管控能力升级和可观测工具完善,并深化行业场景应用,助力用户以更低成本、零运维负担享受高性能消息服务。