导读
BaikalDB作为服务百度商业产品的分布式存储系统,支撑了整个广告库海量物料的存储和OLTP事务处理。随着数据不断增长,离线计算时效性和资源需求压力突显,基于同一份数据进行OLAP处理也更为经济便捷,BaikalDB如何在OLTP系统内实现适合大数据分析场景的查询引擎以应对挑战?
01 BaikalDB应对OLAP场景的挑战
BaikalDB是面向百度商业产品系统的需求而设计的分布式存储系统,过去多年把商业内部几十套存储系统全部统一到BaikalDB,解决了异构存储带来的各种问题,支撑了整个广告库的海量物料存储和复杂的业务查询。BaikalDB核心特点包括:
-
兼容mysql协议,支持分布式事务:基于Raft协议实现三副本强一致性,通过两阶段提交协议保障跨节点事务的原子性与持久性。
-
丰富检索能力:不仅支持传统的结构化索引、全文索引等,为解决LLM应用的向量需求,BaikalDB通过内置向量索引方式实现向量数据的存储和检索,一套系统支持结构化检索、全文检索、向量检索等丰富的检索能力,综合满足LLM应用的各种记忆存储和检索需求。
-
高可用,弹性扩展:支持自动扩缩容和数据均衡,支持自动故障恢复和迁移,无单点。当前管理数千业务表与数十万亿行数据,日均处理百亿级请求。
![]()
△BaikalDB架构
随着业务发展,离线分析难以满足诉求,实时多维分析需求对BaikalDB大数据处理能力的要求显著提高。BaikalDB的查询引擎主要面向OLTP(联机事务处理)场景设计的,以下双重关键瓶颈使其应对OLAP (联机分析处理)有很大的挑战:
-
计算性能瓶颈:传统火山模型使用行存结构破坏缓存局部性、逐行虚函数调用风暴频繁中断指令流水线、单调用链阻塞多核并行扩展等等弊端,导致大数据分析性能呈超线性劣化。
-
计算资源瓶颈:Baikaldb单节点计算资源有限,面对大规模数据计算,单节点CPU、内存使用容易超限。
BaikalDB从OLTP向HTAP(混合事务/分析处理)架构演进亟需解决当前OLTP查询架构在面向大规模数据的计算性能瓶颈、计算资源瓶颈,并通过如向量化查询引擎、MPP多机并行查询、列式存储等技术手段优化OLAP场景查询性能。
02 BaikalDB OLAP查询引擎的目标
2.1 向量化查询引擎:解决OLTP查询引擎性能瓶颈
2.1.1 火山模型性能瓶颈
设计之初,由于BaikalDB主要面向OLTP场景,故而BaikalDB查询引擎是基于传统的火山模型而实现。
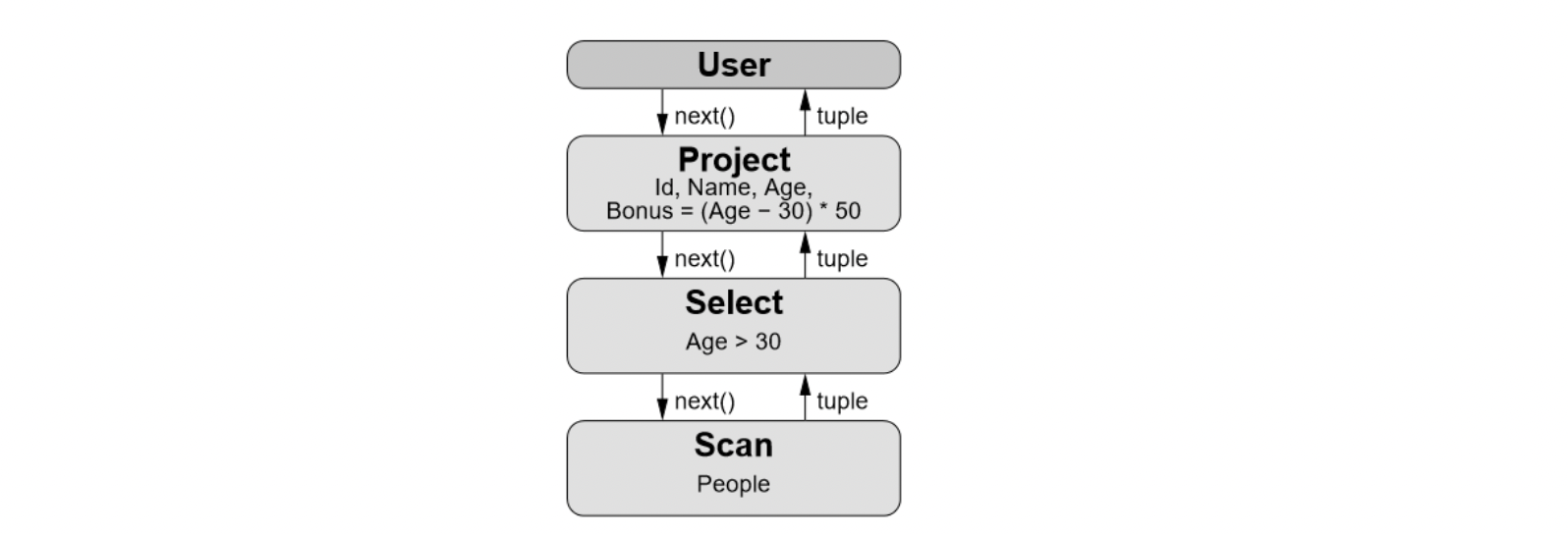
如下图所示,在火山模型里,SQL的每个算子会抽象为一个Operator Node,整个SQL执行计划构建一个Operator Node树,执行方式就是从根节点到叶子节点自上而下不断递归调用next()函数获取一批数据进行计算处理。 由于火山模型简单易用,每个算子独立实现,不用关心其他算子逻辑等优点,使得火山模型非常适合OLTP场景。
![]()
△select id, name, age, (age - 30) * 50 as bonus from peope where age > 30 火山模型执行计划
但当火山模型处理大量数据时有着以下三大弊端,这些弊端是导致火山模型面对大数据量分析场景查询性能差的元凶。
-
行式存储引发的缓存失效问题
-
数据局部性缺失:行式存储(Row-based Storage)将整行数据连续存放,当查询仅需部分列时,系统被迫加载整行冗余数据,容易造成Cache Miss。
-
硬件资源浪费:现代CPU三级缓存容量有限,行存结构导致有效数据密度降低。
-
逐行处理机制的性能衰减
-
函数调用过载:火山模型要求每个算子逐行调用 next() 接口,处理百万级数据时产生百万次函数调用。
-
CPU流水线中断:频繁的上下文切换导致CPU分支预测失败率升高。
-
执行模型的多核适配缺陷
-
流水线阻塞:Pull-based模型依赖自顶向下的单调用链,无法并行执行相邻算子。
-
资源闲置浪费:现代服务器普遍具备64核以上计算能力,单调用链无法充分利用多核能力。
当查询模式从OLTP轻量操作转向OLAP海量扫描复杂计算时,上述三个弊端导致的查询性能衰减呈现级联放大效应。虽然能做一些如batch计算,算子内多线程计算等优化,但并不能解决根本问题,获得的收益也有限。BaikalDB寻求从根本上解决瓶颈的方法,探寻新架构方案以突破性能瓶颈!
2.1.2 向量化查询引擎
多核时代下的现代数据库执行引擎,发展出了向量化查询引擎,解决上述火山模型的种种弊端,以支持OLAP大数据量查询性能。与火山模型弊端一一对应,向量化执行引擎特点是如下:
-
列式存储与硬件加速协同优化
-
列存数据紧凑布局:采用列式存储结构(Colum-based Storage),将同类型数据连续存储于内存,有效提升CPU缓存行利用率,减少Memory Stall。
-
SIMD指令集加速:通过向量寄存器批量处理128/256/512位宽度的连续数据单元,允许CPU在单个指令周期内对多组数据进行相同的操作。
-
批量处理提升缓存亲和性
-
数据访问模式优化:算子/计算函数内部采用批量处理机制,每次处理一批连续数据块。这种连续内存访问模式提升了 CPU DCache 和ICache 的友好性,减少 Cache Miss。
-
流水线气泡消除:批处理大量减少上下文切换,降低CPU资源空闲周期占比,显著提升流水线吞吐量。
-
多核并行计算架构创新
-
Morsel-Driven Parallelism范式:将Scan输入的数据划分为多个数据块(称为morsel),morsel作为计算调度的最小单位,能均匀分发给多个CPU core并行处理。
-
Push-based流水线重构:颠覆传统Pull模型,通过工作线程主动推送数据块至下游算子(算子树中的父节点),消除线程间等待开销。数据驱动执行,将算子树切分成多个线性的Pipeline,多Pipeline之间能并行计算。
![]()
△向量化执行引擎pipeline并行计算
2.2 MPP多机并行计算的启发:进一步提升OLAP查询性能
向量化执行引擎在OLAP场景有大幅度的性能提升,却仍然无法解决单台计算节点的CPU和内存受限的问题,同时随着处理数据量增大,单节点执行时间呈指数级增长。
为了打破这一单点限制,进一步提升OLAP查询性能,MPP(Massively Parallel Processing)大规模并行计算应运而生,其核心特点有:
-
****分布式计算架构:****基于哈希、范围等策略将数据分布到不同计算节点,实现并行计算加速,能显著缩短SQL响应时间。
-
****线性扩展:****各计算节点采用无共享架构,通过高速网络实现跨节点数据交换,天然具备横向扩展能力,可通过增加节点线性提升整体吞吐量。
![]()
△MPP: 3台计算节点并行计算
03 BaikalDB HTAP查询架构落地
3.1 巧妙结合Arrow Acero实现向量化查询引擎
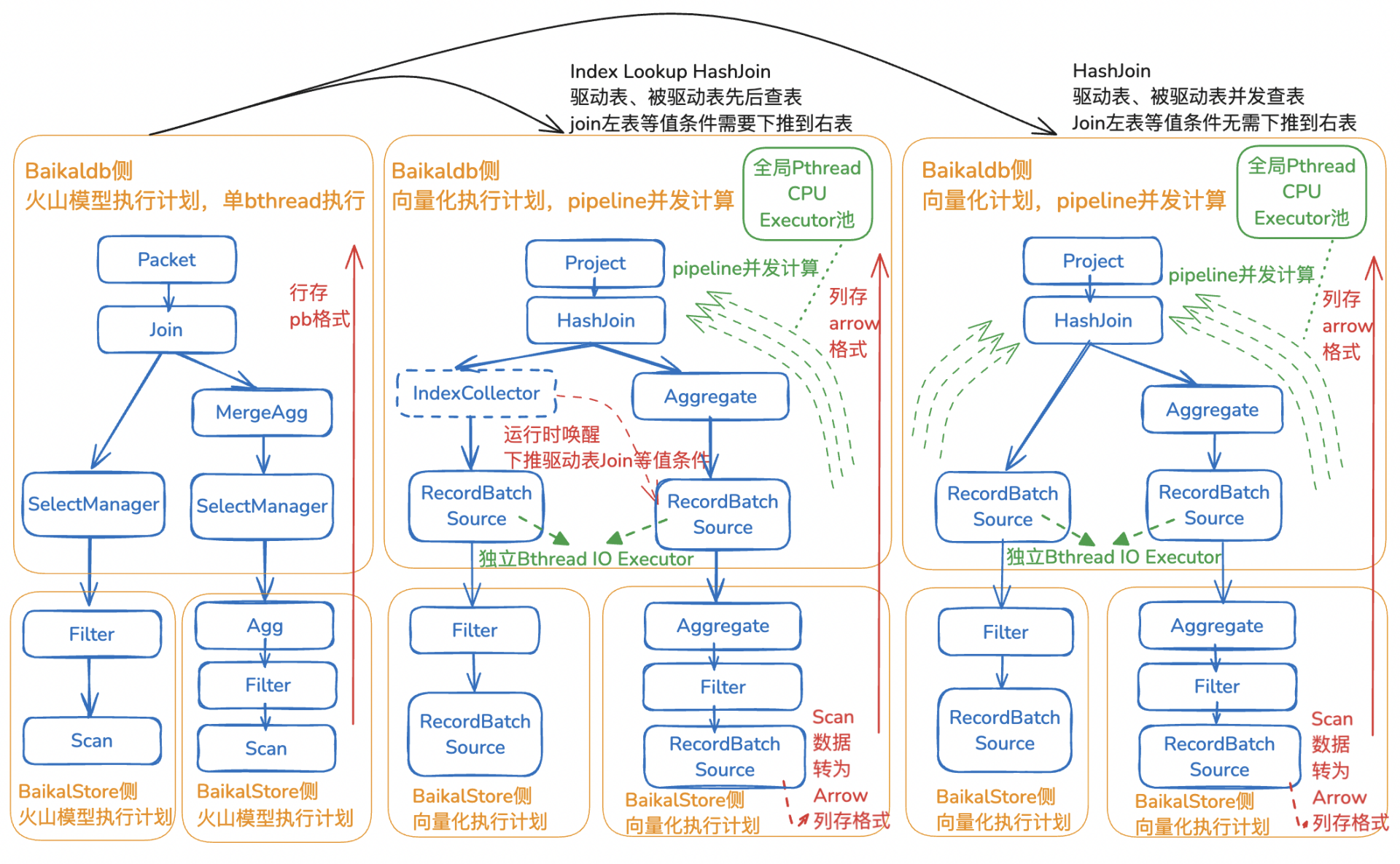
BaikalDB团队在向量化执行引擎设计过程中,秉持"避免重复造轮子"的技术理念,优先探索开源生态的优秀解决方案。基于BaikalDB已采用Apache Arrow列式存储格式实现全文索引的技术积淀,团队发现Arrow项目最新推出的Acero流式执行引擎子项目展现出三大核心功能:①支持Arrow列式存储格式向量化计算,支持SIMD加速;②Push-Based流式执行框架支持Pipeline并行计算,能充分利用多核能力;③执行框架可扩展——这些特性与BaikalDB对向量化执行引擎的需求高度契合。最终团队选择基于Arrow列存格式和Acero流式计算引擎实现BaikalDB向量化执行引擎,不仅大幅度缩短了研发周期,更充分发挥了开源技术生态的协同优势。
BaikalDB巧妙结合开源Apache Arrow列存格式和Arrow Acero向量化执行引擎,通过将火山模型计划翻译为Acero执行计划,全程使用Arrow列存格式,计算最终列存结果再列转行返回给用户,在BaikalDB内部实现了适合大量数据计算的向量化查询架构。
核心实现包括以下五点:
-
数据格式:将源头RocksDB扫描出来的行存数据直接转为Arrow列存格式,SQL计算全程使用Arrow列存,最终将列存格式的计算结果再转换成行存输出给用户。
-
计算函数:将所有BaikalDB计算函数翻译成Arrow Compute Expression,每个Arrow计算函数运行一次处理万行数据,同时能支持部分如AVX2、SSE42等SIMD指令集,支持SIMD加速。
-
执行计划:将每个SQL生成的BaikalDB原生执行计划,转换成一个Acero执行计划Exec Plan(包含所有BaikalDB算子翻译成的Acero ExecNode Declaration树),使用Acero向量化执行引擎替换火山模型执行。
-
调度器:将进行数据扫描SourceNode的IO Executor和计算的CPU Executor独立开。
-
每个Baikaldb和BaikalStore实例内置一个全局的Pthread CPU IO Executor池,支持计算阶段的Push-based Pipeline并行计算,同时支持算子内并行计算,如Agg并发聚合、Join并发Build/Probe等。
-
每个SourceNode都独自一个Bthread IO Executor,支持Hash Join或Union的各个子节点能并发查表。
-
RPC接口:Baikaldb和BaikalStore之间RPC使用Arrow列存格式替换行存pb格式进行数据传输,大幅度降低传输数据大小,同时去掉了pb序列化和反序列化的开销,加速了数据传输效率。
![]()
△BaikalDB火山模型(左) BaikalDB向量化引擎(中:Index Lookup HashJoin,右:HashJoin)
3.2 拆解执行计划实现MPP多机并行查询引擎
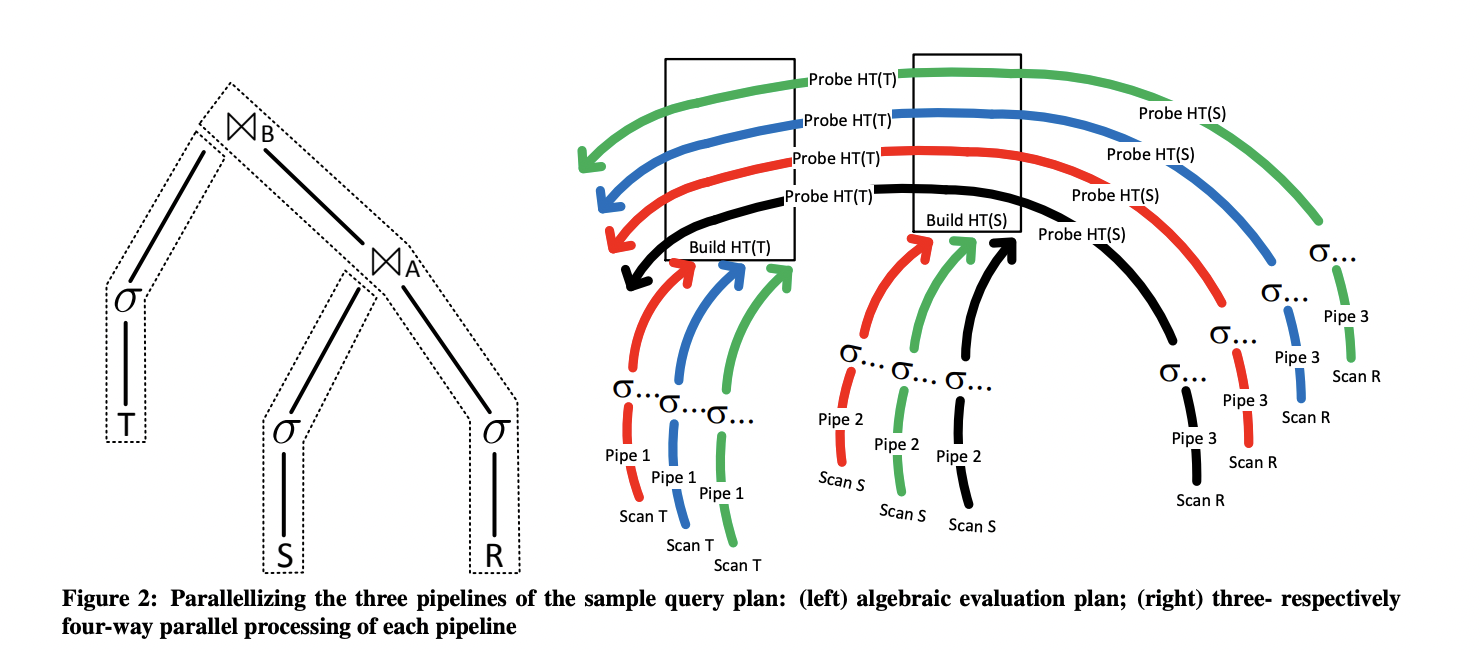
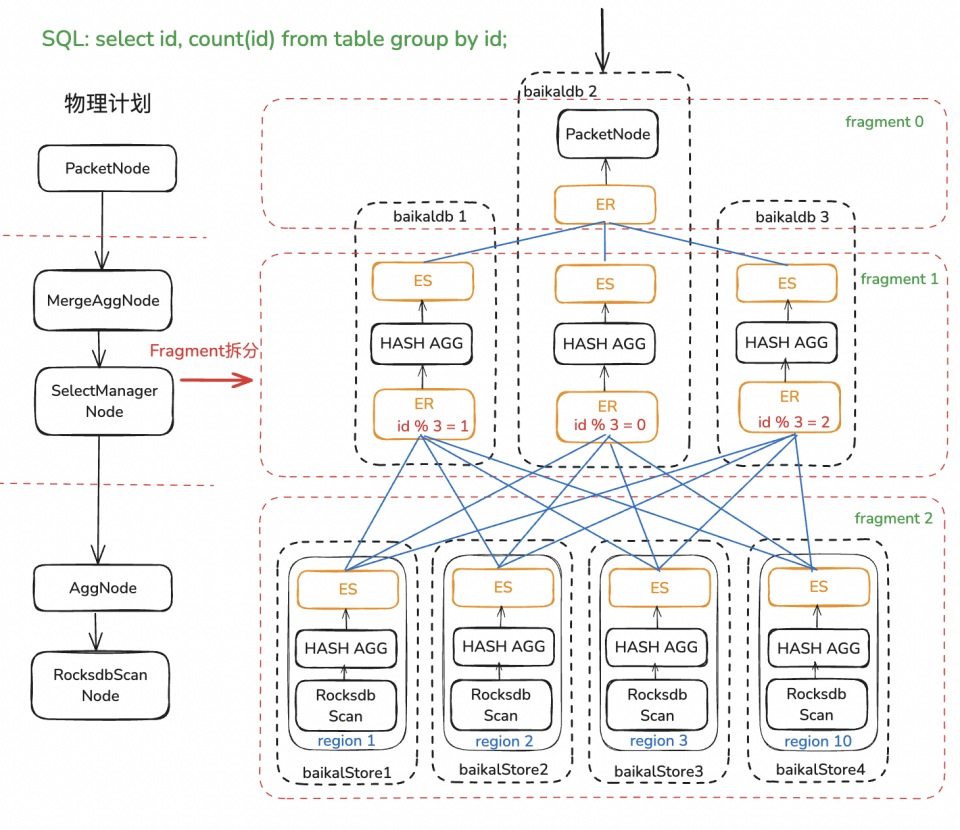
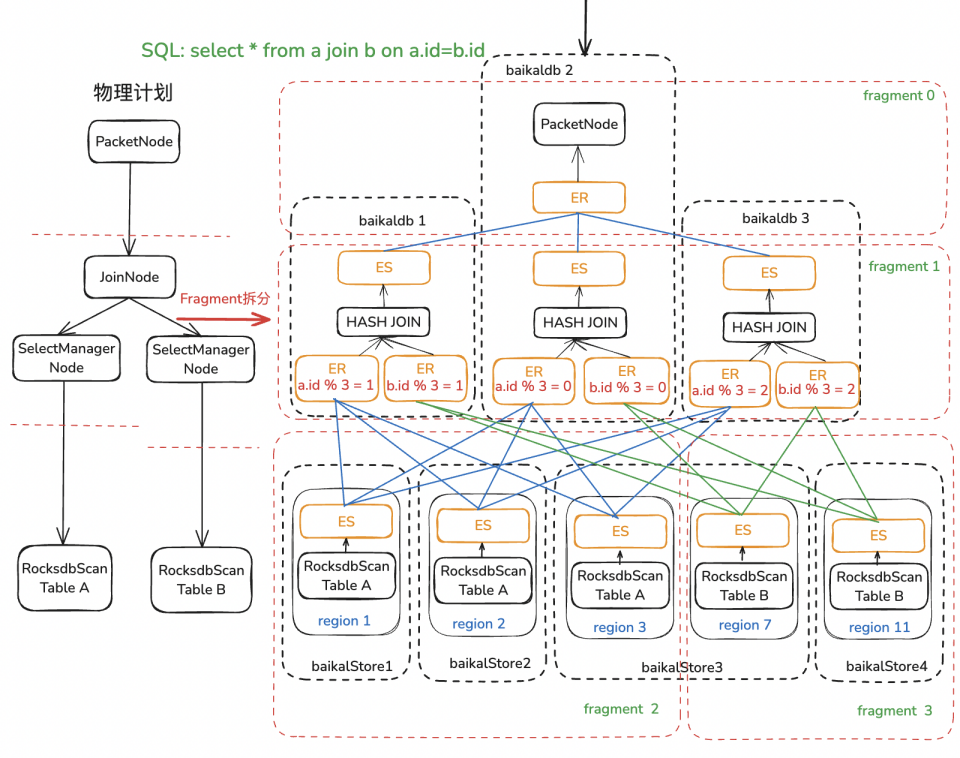
BaikalDB实现了向量化执行引擎后,大部分OLAP请求性能得到大幅度提升,但很快就遇到了受限于单计算节点资源和性能的case。团队首先对业务场景进行了分析,发现资源/性能卡点主要在集中在最后单点Agg/Join的计算上。
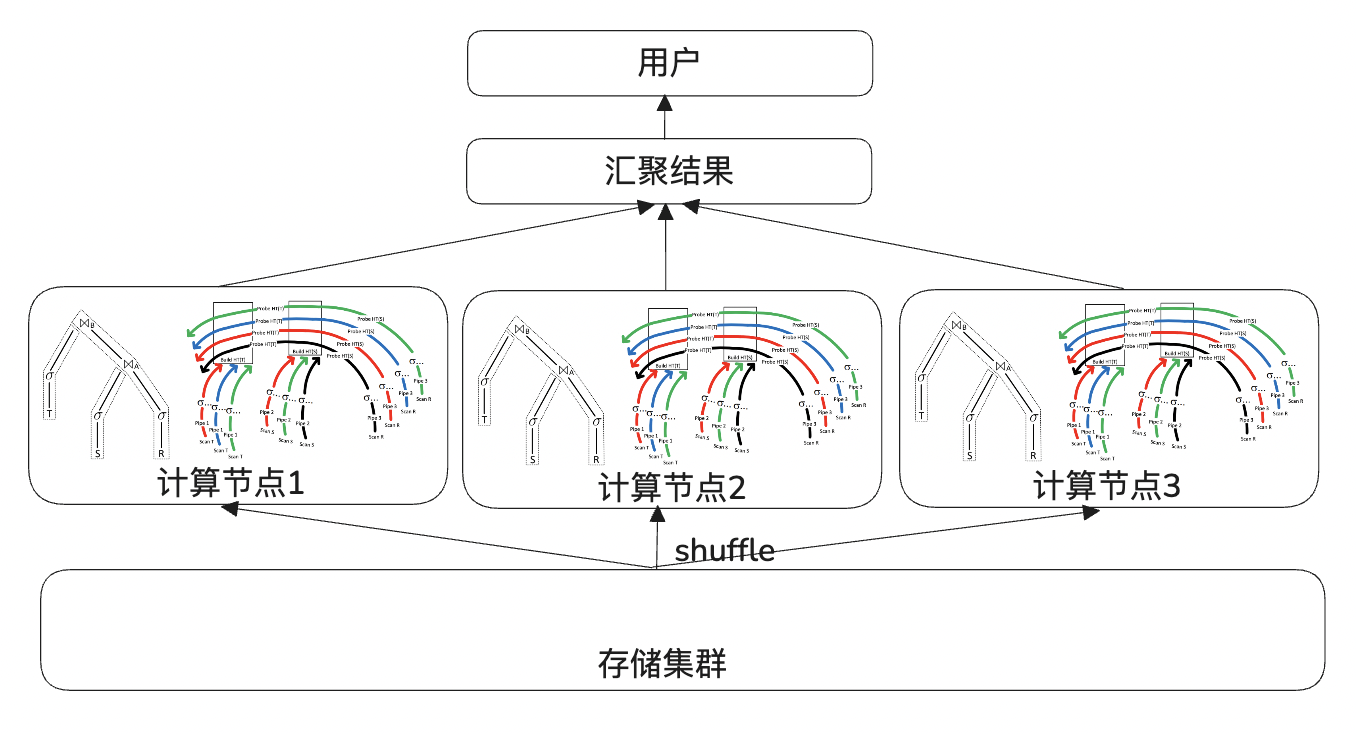
为了破除这一单点限制,因Agg/Join都依赖内部HashTable进行计算,很容易想到按照HashKey将源数据hash shuffle到不同的计算节点进行并行计算来加速计算性能,平摊计算需要的内存和CPU资源,每个计算节点依然可以使用向量化执行引擎加速单机计算性能。如下图所示,这一方案需要解决的核心问题有以下两点:
-
实现Exchange算子对进行跨节点数据Shuffle。
-
在执行计划合适的地方的插入Exchange算子对拆分为多个并行子计划Fragment。
![]()
△BaikalDB Agg Mpp执行示例
![]()
△BaikalDB Hash Join Mpp执行示例
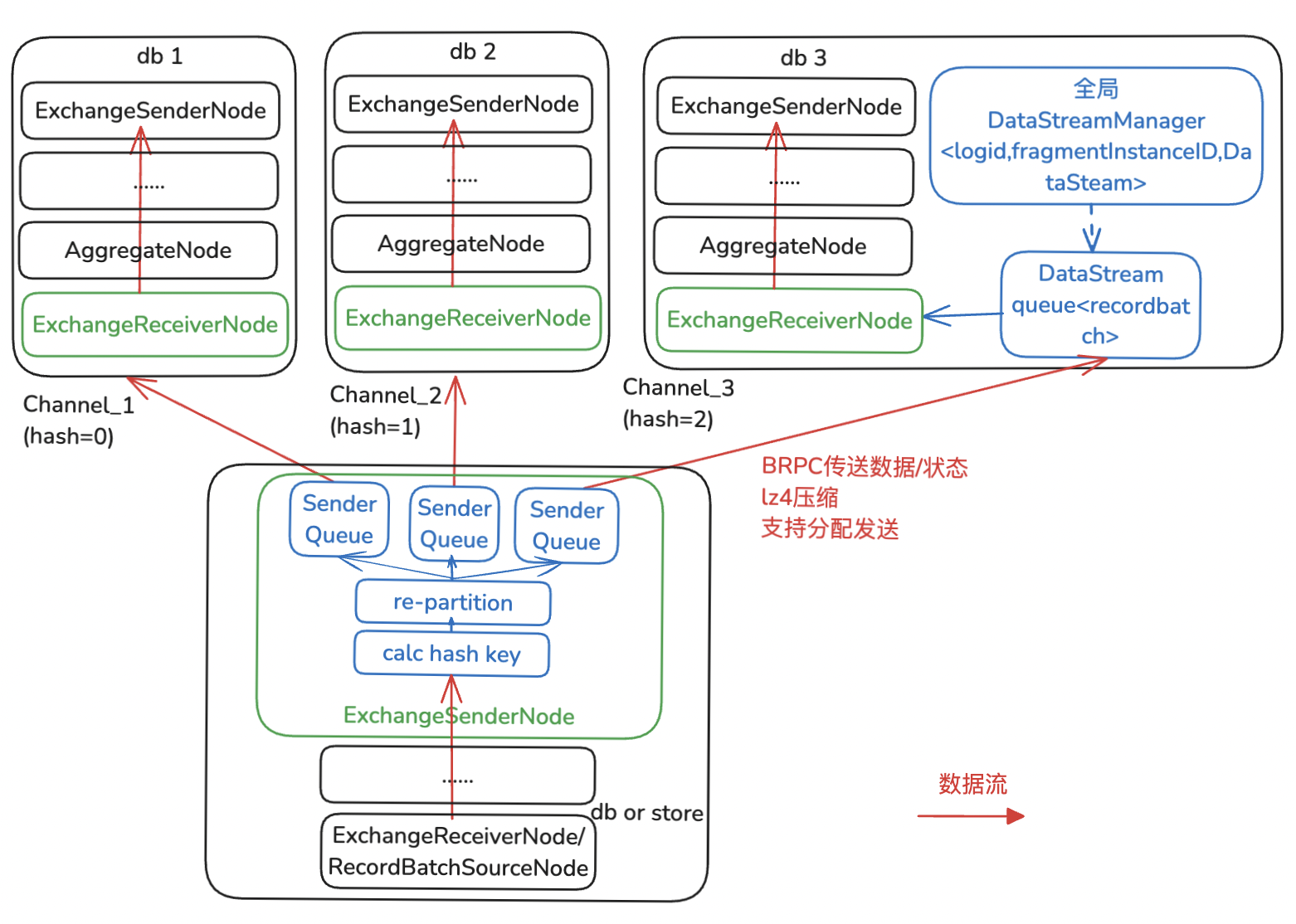
3.2.1 Exchange算子跨节点数据shuffle
Exchange算子包括ExchangeSenderNode/ExchangeReceiverNode算子对,必须成对出现,进行跨节点数据分发和接收。ExchangeReceiverNode核心功能主要是接收对应的下游Fragment所有ExchangeSenderNode发来的数据,需保证不重不丢,进行超时处理等。ExchangeSenderNode核心功能是进行数据分发,其分发模式主要有以下三种,以支持不同的场景需求。
-
SinglePartition:一个或者多个ExchangeSenderNode将所有数据直接完整发送到单个上游Fragment ExchangeReciverNode实例,使用场景如Fragment 0单个计算节点收集最终结果输出给用户。
-
HashPartition:ExchangeSenderNode将所有数据都先根据指定HashKey计算每一行hash值,根据hash值将每行数据re-partition到不同的发送队列里,最终发送到上游Fragment多个ExchangeReceiverNode,使用场景如Store Fragment将rocksdb扫描出来的数据shuffle到上游多个实例进行Agg/HashJoin计算。
-
BroadcastPartition:ExchangeSenderNode将所有数据都直接完整发送到多个上游ExchangeReciverNode,使用场景如Join小表数据直接完整发送到上游多个实例进行BroadcastJoin。
![]()
△BaikalDB Exchange算子实现(HashPartition)
3.2.2 执行计划拆解多个并行子计划Fragment
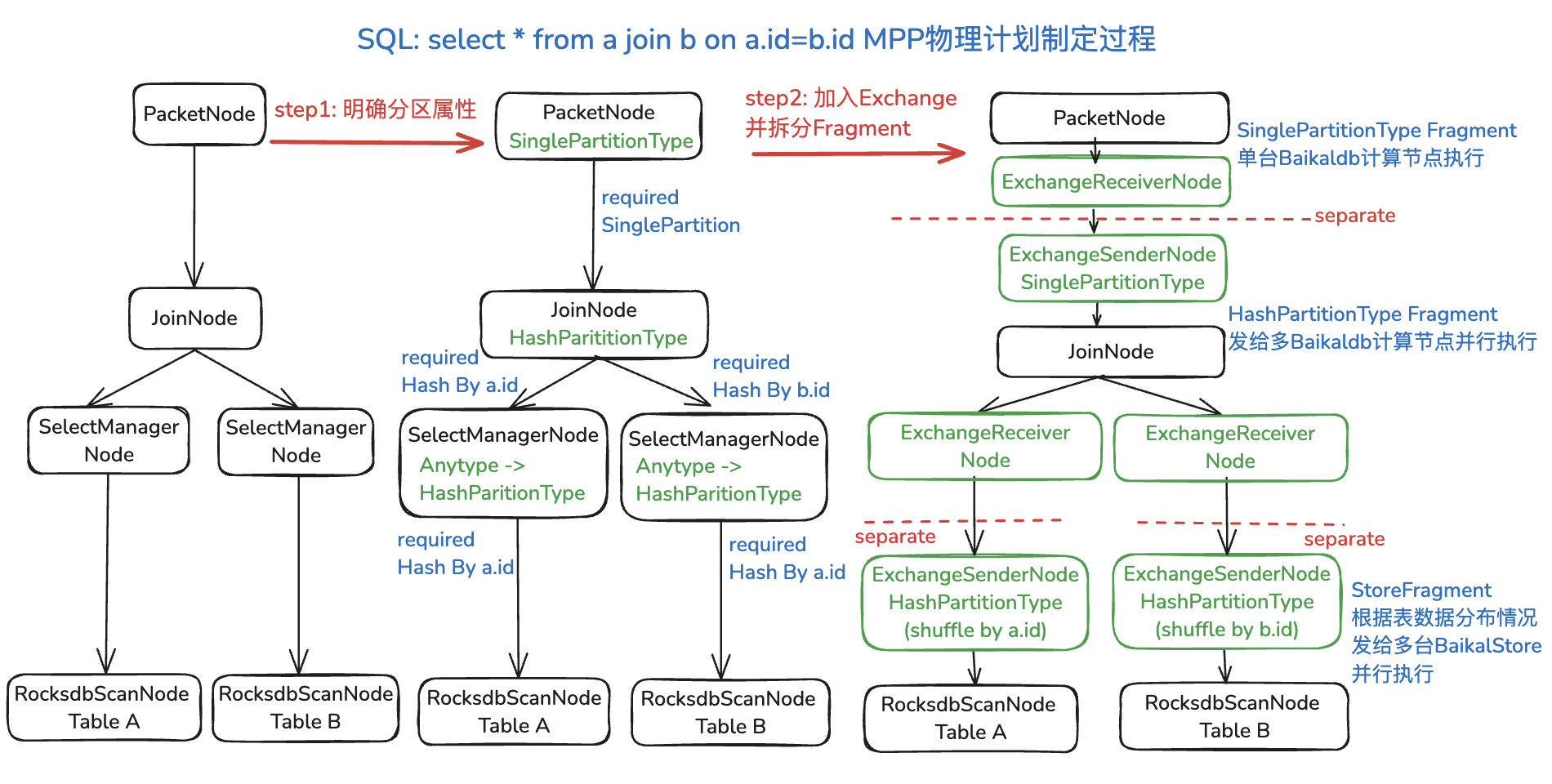
在插入Exchange算子对之前,需要给物理执行计划里的每个算子明确其分区属性PartitionProperty,标志着该算子是否可以分发到多个计算节点进行并行加速。PartitionProperty主要有三种:
-
AnyParitition:该节点没有任何要求,如FilterNode,可以根据相邻节点分区属性情况单节点或多节点执行。
-
SinglePartition:该节点必须要在单个计算节点上执行,如用于将最终数据打包发送给用户的PacketNode。
-
HashPartition:该节点可以按照指定key将数据分发到多个计算节点上并行执行,当前只有AggNode和JoinNode会产生HashPartition。
如下图所示,明确了每个算子的分区属性后,需要加入Exchange算子对的位置就很清晰明了了:分区属性有冲突的相邻算子之间。
在物理计划中插入了Exchange算子对后,在一对ExchangeSenderNode/ExchangeReceiverNode之间进行拆解,即可以将单个物理执行计划拆分为多个子执行计划Fragment。单机执行的Fragment在本机执行,多机执行的Fragment发送给多个同集群其他计算节点进行异步执行,store fragment根据表数据分布情况分发给BaikalStore存储集群并行执行。
在MPP物理计划制定过程中,为了减少数据shuffle的开销,尽可能减少SQL shuffle数据量,BaikalDB也实现了多种查询计划优化手段,如limit下推、hash partition fragment合并等等。
![]()
△MPP物理计划制定过程
3.3 自适应策略支持一套系统应对TP/AP请求
BaikalDB设计HTAP架构的核心目标是一套系统能同时兼容OLTP和OLAP请求,无需业务进行任何改造,这需要系统拥有极强的兼容性。
目前BaikalDB内部有三种执行方式:火山模型、单机向量化执行引擎、MPP多机执行引擎,不同的执行引擎适用不同数据量级的SQL。随着数据量大小从小到大,适合的计算引擎是火山模型执行 → 单机向量化执行 → MPP多机并行执行,原因有以下两点:
-
火山模型执行对比向量化执行更为轻量,导致在OLTP小请求(如SQL涉及数据行数<1024)方面,传统火山模型性能比单机向量化执行性能更好。
-
MPP执行会带来额外的网络开销(数据shuffle)、CPU开销(hash计算和re-partition),导致Baikaldb处理数据量需要超过一定阈值时,Baikaldb多机并行执行才能cover额外的网络/CPU开销,SQL性能才能提升,否则单机向量化执行是性能最优。
BaikalDB实现了智能执行引擎决策系统,支持SQL自适应选择合适的执行引擎,支持一套集群能同时满足业务OLTP和OLAP场景需求。技术实现包含两大核心机制:
-
向量化引擎动态热切换:BaikalDB支持SQL在执行过程中,随着数据量增大,从火山模型动态切换到向量化执行引擎执行。
-
统计信息驱动MPP加速:BaikalDB支持根据过去执行统计信息决策是否走MPP加速执行,当SQL统计的99分位处理数据行数/大小超过指定的阈值,则SQL直接通过MPP多机并行执行。
04 总结
4.1 项目收益
BaikalDB通过架构创新打造了HTAP架构,期望一套系统支持线上OLTP/OLAP请求,其技术演进路径呈现『混合执行引擎架构自适应选择』的特征:SQL自适应选择火山模型、向量化执行引擎、MPP多机并行执行引擎。
目前BaikalDB HTAP架构已经应用到线上多个业务,大数据量查询取得大幅度的性能提升,同时Baikaldb单点内存使用峰值也得以大幅度下降:
4.2 未来展望
BaikalDB HTAP架构目前还在不断发展,包括性能优化、丰富支持算子和计算函数等等,未来还预期结合列式存储、CBO等技术进一步提升OLAP场景性能:
-
结合列式存储提升数据扫描性能:目前BaikalDB向量化查询引擎和MPP查询引擎全程基于Arrow列存格式,但是底层数据存储仍然是行存,存在一次行转列的开销;并且OLAP场景,更适合使用列存格式作为底层数据存储格式。BaikalDB当前在发展列存引擎,未来单机向量化和MPP能直接基于底层列式存储,进一步提升OLAP场景查询性能。
-
结合CBO(Cost-Based Optimization)优化自适应MPP选择策略:当前BaikalDB是基于过去的执行统计信息判断SQL是否适合走MPP,当SQL过去执行统计信息波动巨大时,自适应判断方法可能会失效,未来可能结合代价模型来进一步优化MPP选择策略。