一项由麻省理工学院媒体实验室的Nataliya Kosmyna及其团队主导的最新研究,深入探讨了在论文写作任务中,使用大型语言模型(LLM)如OpenAI的ChatGPT可能带来的认知成本。该研究发现,尽管LLM产品为人类和企业带来了诸多便利,但其广泛应用却可能导致大脑积累“认知负债”,长远来看甚至会削弱个体的学习技能。
![]()
该研究招募了54名参与者,并将其分为三组:LLM组(仅使用ChatGPT)、搜索引擎组(使用传统搜索引擎,禁用LLM)和纯脑力组(不使用任何工具)。研究共进行了四次会话,其中在第四次会话中,LLM组的参与者被要求不使用任何工具(被称为“LLM转纯脑力组”),而纯脑力组的参与者则开始使用LLM(被称为“纯脑力转LLM组”)。
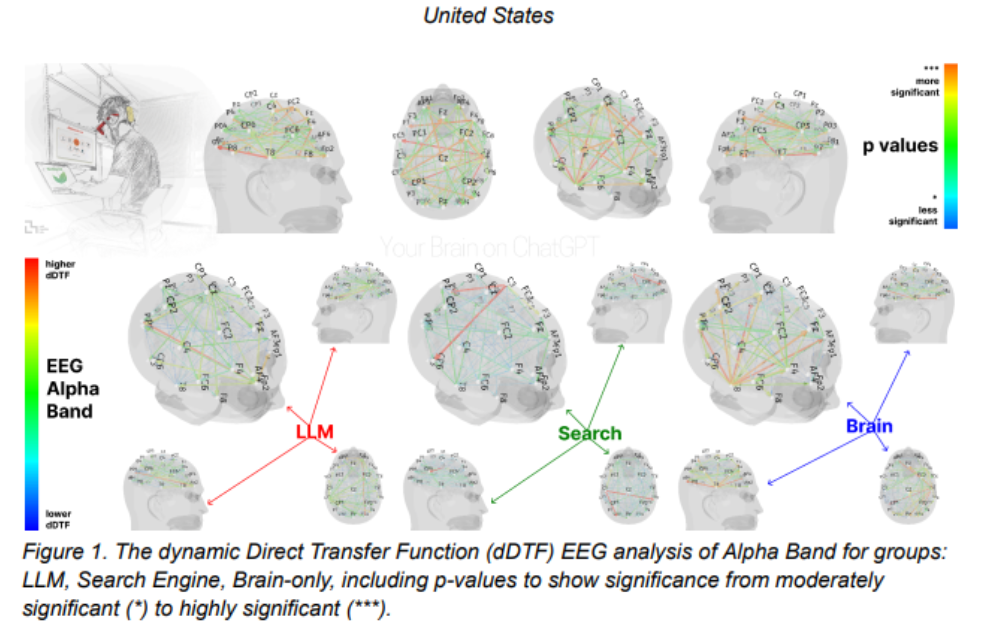
研究团队通过脑电图(EEG)记录了参与者的大脑活动,以评估其认知投入和负荷,并深入理解论文写作任务期间的神经激活模式。此外,研究还进行了自然语言处理(NLP)分析,并在每次会话后对参与者进行了访谈,同时邀请人类教师和AI评判员对论文进行打分。
![]()
核心发现:大脑连接性减弱,记忆和所有权受损
研究结果提供了确凿证据,表明LLM、搜索引擎和纯脑力组的神经网络连接模式存在显著差异,反映了不同的认知策略。大脑连接性与外部支持的程度呈系统性下降:纯脑力组表现出最强、范围最广的连接网络,搜索引擎组居中,而LLM辅助则引发了最弱的整体耦合。
特别值得关注的是,在第四次会话中,“LLM转纯脑力组”的参与者表现出较弱的神经连接性,以及阿尔法(alpha)和贝塔(beta)网络的投入不足。阿尔法波段连接性通常与内部注意力、语义处理和创造性构思相关。贝塔波段则与主动认知处理、专注注意力和感觉运动整合相关。这些结果表明,过去依赖LLM的使用者,在脱离工具后,其大脑在内容规划和生成方面的神经活动有所减少,这与认知卸载的报告相符,即依赖AI系统可能导致被动方法和批判性思维能力的减弱。
在记忆方面,LLM组的参与者在引用自己刚写完的论文时表现出明显障碍,甚至无法正确引用。这直接映射到LLM组较低的低频连接性,特别是与情景记忆巩固和语义编码密切相关的西塔(theta)和阿尔法波段。这表明LLM用户可能绕过了深层记忆编码过程,被动地整合了工具生成的内容,而没有将其内化到记忆网络中。
此外,LLM组对自己论文的所有权感知度普遍较低,而搜索引擎组拥有较强的所有权感,但仍低于纯脑力组。这种行为上的差异与神经连接性模式的变化相吻合,凸显了LLM使用对认知能动性的潜在影响。
认知负债的积累:效率与深度学习的权衡
研究指出,尽管LLM在初期提供了显著的效率优势并降低了即时认知负荷,但随着时间的推移,这种便利可能以牺牲深度学习成果为代价。报告强调了“认知负债”的概念:重复依赖外部系统(如LLM)取代了独立思考所需的努力认知过程,短期内延迟了脑力投入,但长期却导致批判性探究能力下降、更容易被操纵以及创造力减退。
纯脑力组的参与者,尽管面临更高的认知负荷,却展现出更强的记忆力、更高的语义准确性和对其作品更坚定的主人翁意识。而“纯脑力转LLM组”在首次使用AI辅助重写论文时,大脑连接性显著增加,这可能反映了将AI建议与现有知识整合时的认知整合需求,暗示了AI工具引入的时机可能对神经整合产生积极影响。
对教育环境的深远影响与未来展望
研究团队认为,这些发现对教育领域具有深远意义。过度依赖AI工具可能无意中阻碍深层认知处理、知识保留以及对书面材料的真实投入。如果用户过度依赖AI工具,他们可能会获得表面的流畅度,但却无法内化知识或对其产生所有权感。
该研究建议,教育干预应考虑将AI工具辅助与“无工具”学习阶段相结合,以优化即时技能转移和长期神经发展。在学习的早期阶段,全面的神经参与对于发展强大的写作网络至关重要;而在后续练习阶段,有选择性的AI支持可以减少无关的认知负荷,从而提高效率,同时不损害已建立的网络。
研究人员强调,随着AI生成内容日益充斥数据集,以及人类思维与生成式AI之间的界限变得模糊,未来研究应优先收集不借助LLM协助的写作样本,以发展能够识别作者个人风格的“指纹”表示。
最终,这项研究呼吁在LLM整合到教育和信息情境中时,必须谨慎权衡其对认知发展、批判性思维和智力独立性的潜在影响。LLM虽然能减少回答问题的摩擦,但这种便利性也带来了认知成本,削弱了用户批判性评估LLM输出的意愿。这预示着“回音室”效应正在演变,通过算法策划内容来塑造用户接触信息的方式。
(研究论文标题为《Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task》,主要作者为麻省理工学院媒体实验室的Nataliya Kosmyna等。)