“缓存搞定了、异步也安排了,RAG 终于跑得飞快……但它真的能看懂图了吗?”
🙋♀️ “PDF 里的图表,怎么总像谜语人?”
🙋♂️ “论文里密密麻麻的公式,是让人看,还是让人头疼?”
别急,前面几讲我们刚把 RAG 提速到起飞,这次——直接上天看图表!
第13、14讲,火力全开攻克“多模态”难题,聚焦如何让 RAG 看图识表、解读论文、图文并茂输出高质量答案!
为什么要引入多模态?
- 现实痛点:合同、论文、产品手册中,50%关键信息藏在图表里(如论文实验数据、财报统计图)
- 传统局限:纯文本RAG处理PDF时,图片=空白,表格=乱码(全靠OCR硬扛,效果看命💔)
- 解法:引入多模态大模型(MLLM),让AI像人类一样图文协同理解
基本原理
|
层级
|
核心任务
|
技术方案
|
关键突破
|
|
感知层
(特征提取)
|
多模态→统一向量化
|
• 图像:CNN/ViT
• 音频:频谱Transformer
• 文本:BERT/GPT
• 视频:帧序列编码
|
打破模态壁垒
异构数据统一表达
|
|
对齐层
(语义映射)
|
跨模态语义关联
|
• MLP投影:非文本向量→文本空间
• 跨模态注意力:图文向量互作
• 混合输入:图像Patch+文本Token融合
|
建立“猫图”=“猫”的语义等价性
|
|
理解层
(推理生成)
|
多模态协同推理
|
• LLM整合信息→语言建模驱动
• 输出:图文/音视频多态内容
• 任务:问答/描述/创作
|
实现“看CT说病情”类人认知
|
多模态智能 = 特征编码 ⊕ 语义对齐 ⊕ 语言推理(⊕ 代表跨模态融合运算符)
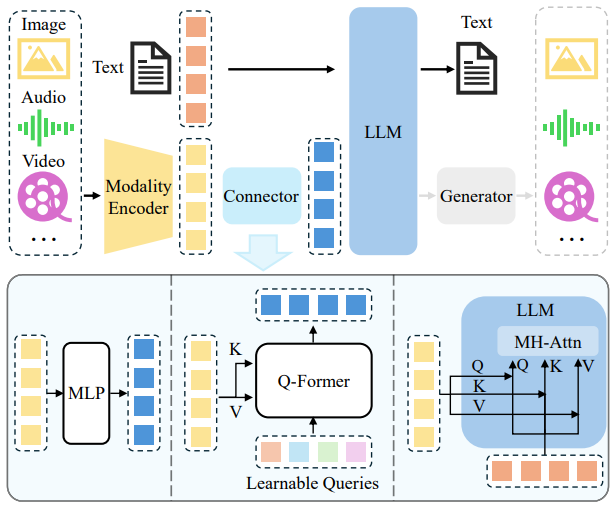
模型架构
![]()
模态编码器(Modality Encoder)
⚒️作用:将不同模态的数据(如图像、音频、视频、文本)转为向量表示(embedding)
📌特点:每种模态使用专门模型编码
-
图像:CNN / ViT
-
音频:语音模型(如 Whisper)
-
文本:语言模型(如 BERT / T5)
连接器(Connector)
⚒️作用:将非文本模态的向量,对齐到文本 embedding 的语义空间,解决“语义壁垒”问题
📌常见连接方式:
语言模型(LLM)
⚒️作用:接收已对齐的统一向量,完成理解和生成任务
📌能力体现:
主流开源模型
![]()
🎯 判别式范式(Discriminative Paradigm):以 CLIP 为代表,侧重于学习图文匹配与对齐,主要用于图像分类、检索等任务;
🧙♂️ 生成式范式(Generative Paradigm):以 OFA、VL-T5、Flamingo 等为代表,强调跨模态生成,如图像描述、视觉问答等。
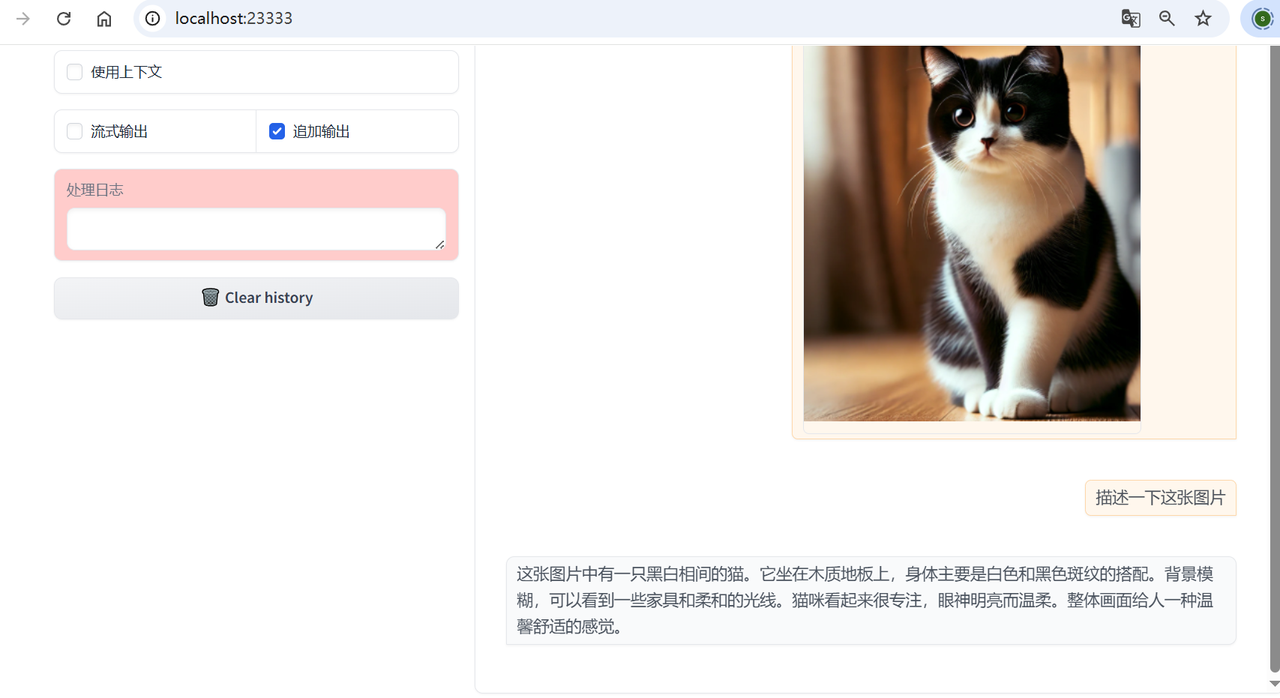
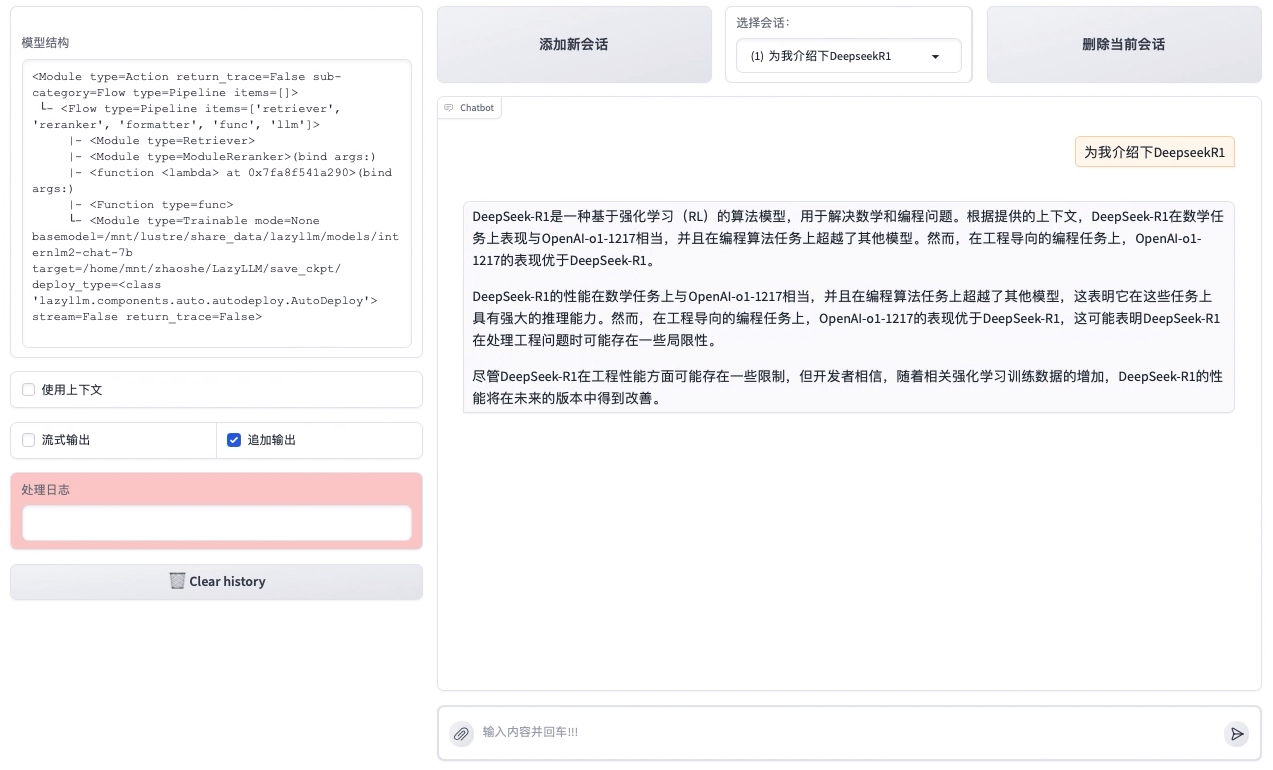
在LazyLLM中使用多模态大模型
代码实现
import lazyllm
chat = lazyllm.OnlineChatModule(source="glm", model="glm-4v-flash")
lazyllm.WebModule(chat, port=23333, files_target=chat).start().wait()
效果展示
![]()
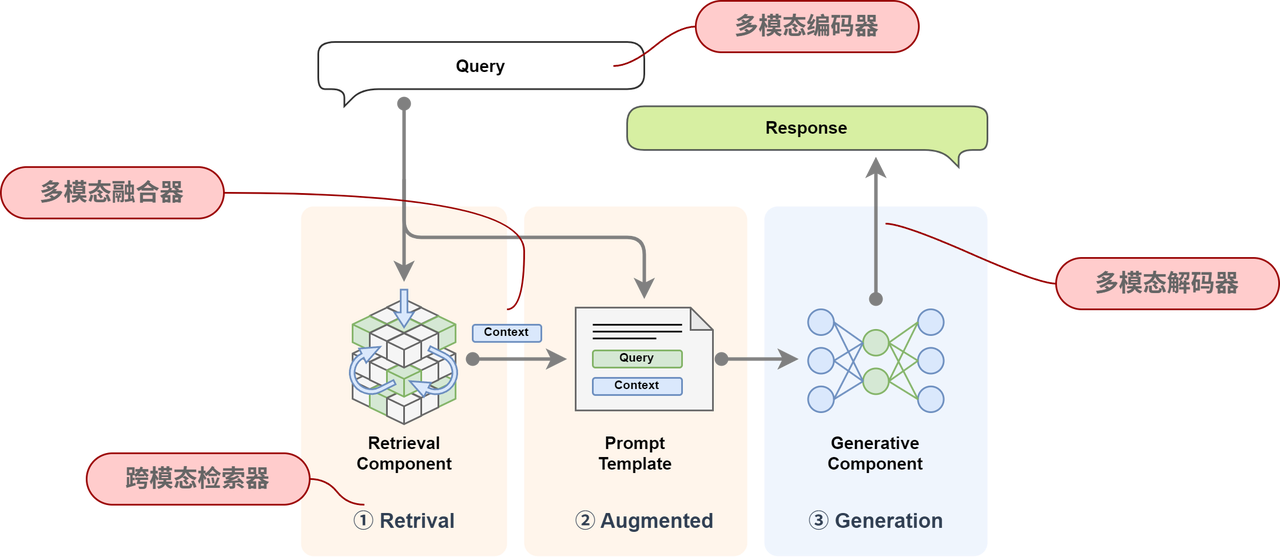
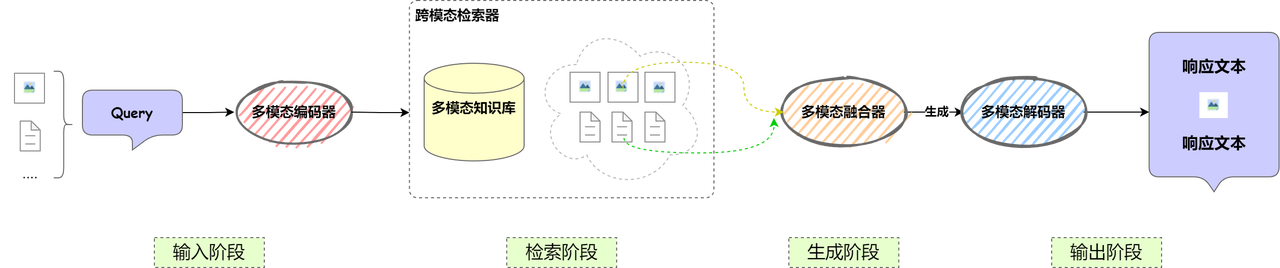
多模态RAG揭秘
整体架构
![]()
🧩 修改的模块包括:
- 检索模块:原本仅支持文本检索,现在需要扩展为支持多模态检索,例如图像、音频等信息的索引和匹配。
- 生成模块:原始 RAG 仅针对文本生成,现在需要扩展支持多模态输出,如文本结合图像、音频的生成能力。
核心组件
![]()
🌉 在原有组件上新增以下组件:
|
组件
|
功能
|
|
多模态编码器
|
用于对不同模态的数据(文本、图像、音频等)进行编码,以便统一表示并用于检索和生成。
|
|
多模态融合器
|
用于融合不同模态的信息,使其能够协同作用,提高生成内容的准确性和丰富度。
|
|
跨模态检索器
|
支持输入多种数据格式,并能在多模态知识库中找到相关信息。
|
|
多模态解码器
|
负责将生成结果解码为多种形式,如文本、图片、语音等,以适应不同的输出需求。
|
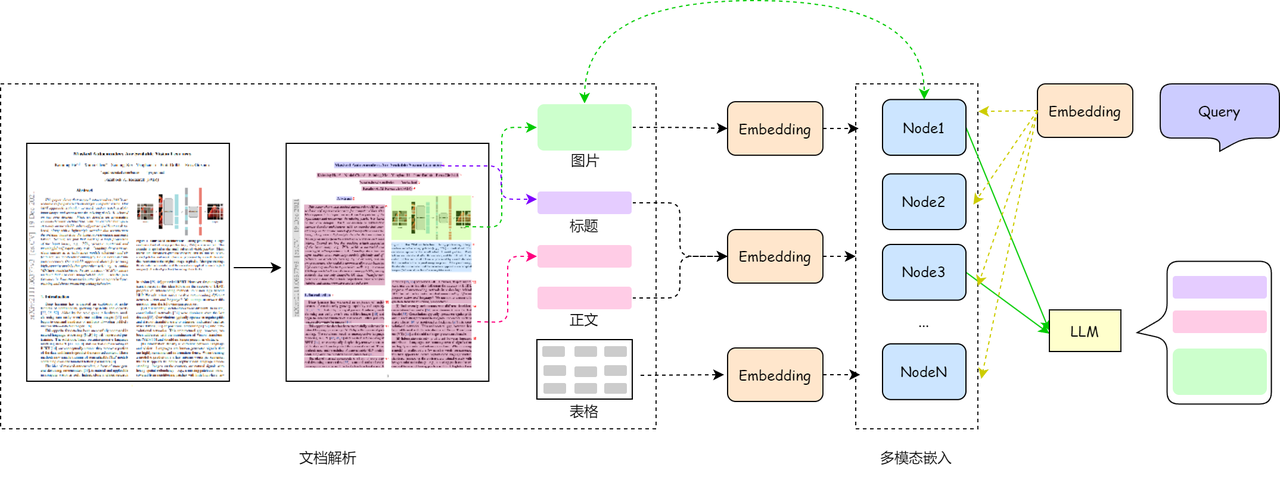
基于 PDF 文档的多模态 RAG
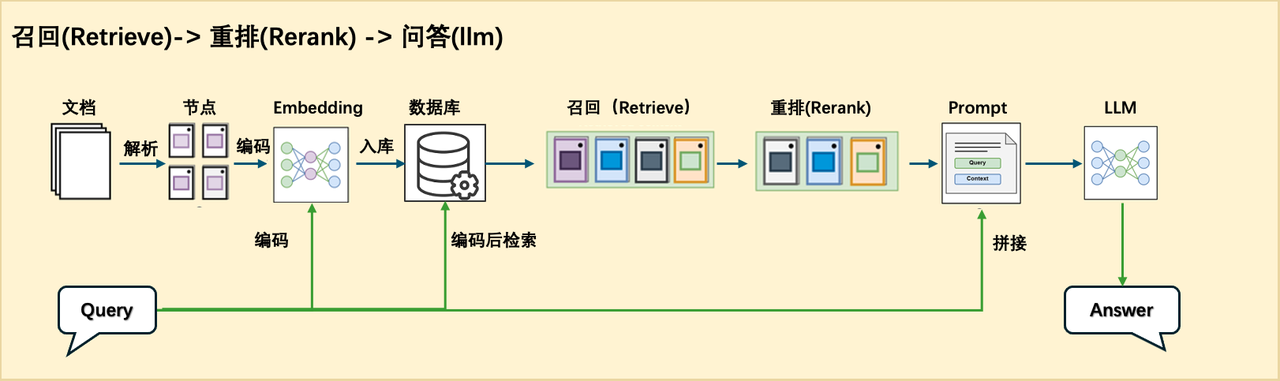
基于OCR文档解析的图文RAG系统流程包括文档解析、多模态嵌入以及查询与生成三个关键步骤。
![]()
文档解析
1️⃣ PDF 是啥?
- 一种跨平台、排版固定的文档格式,支持文本、图片、表单、视频等内容,广泛用于办公和学术场景。
2️⃣ 两种常见 PDF 类型:
- 机器生成型:内容可选中、可搜索,适合直接用工具解析。
- 扫描生成型:本质是图片,需 OCR 技术识别文字。
3️⃣ 怎么解析?
- 机器 PDF:可用
pdfminer、pdfplumber 等 Python 工具提取结构化文本、表格等信息。
- 扫描 PDF:需用 OCR 工具(如 Tesseract、PaddleOCR)识别文字,复杂场景可用 LayoutLM 等深度模型提升识别效果。
4️⃣ 结构保留也很重要:
- 仅提取文本远远不够,文档的段落结构、标题层级、表格排版等信息对语义理解同样关键,因此还需要布局分析(如使用 LayoutLM 等模型)。
5️⃣ 推荐工具:magic-pdf
- 集成了文本提取、结构恢复、表格/公式分析等功能,一站式解析 PDF,为多模态理解打好基础。
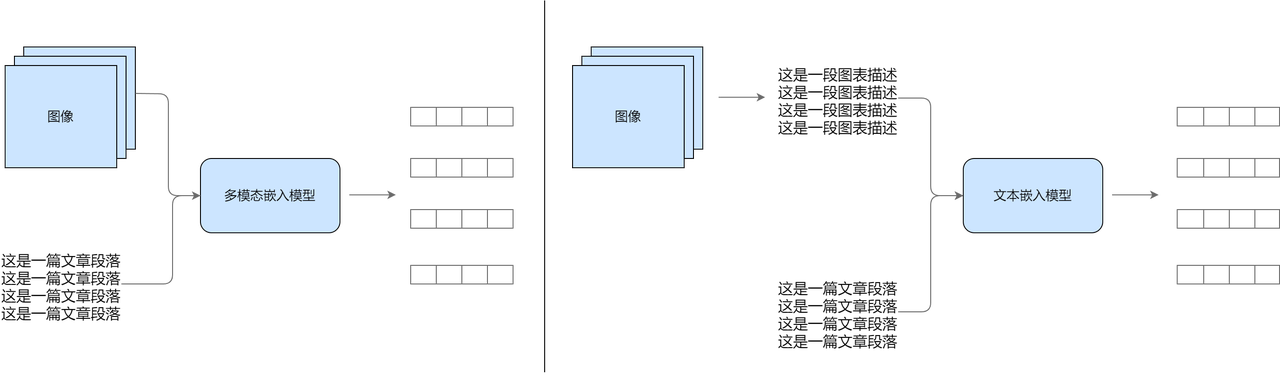
多模态嵌入
![]()
左侧为利用多模态模型进行映射方法,右侧为统一数据模态后进行向量嵌入方法
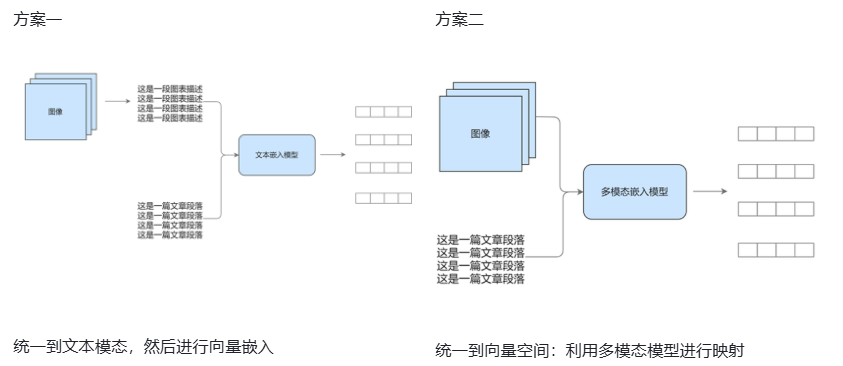
1️⃣ 直接嵌入统一空间
- 用多模态模型(如 CLIP、VisualBERT)将图像、文本一同编码进同一个向量空间,实现语义对齐。适用于图文结合的检索和生成任务,保留原始模态信息更完整。
2️⃣ 先转文本再嵌入
- 图像、表格等非文本内容先转成文本(比如描述语句或结构化语言),再用文本嵌入模型处理。可复用成熟文本工具,但可能损失部分细节。
两者选择取决于:
- 想保留原始信息 → 用第一种;
- 侧重统一处理流程 → 选第二种。
无论哪种方式,都可与文本 RAG 兼容,修改入库流程即可实现最基础的多模态 RAG。
🖼️ 图片自动生成问答对
借助如 InternVL-Chat 这样的多模态大模型,图片中的关键信息(标题、数据、趋势等)可被自动提取,并生成相关问题与答案,帮助系统理解图像内容、补足文档信息。比如看图秒懂论文结论,不再靠猜。
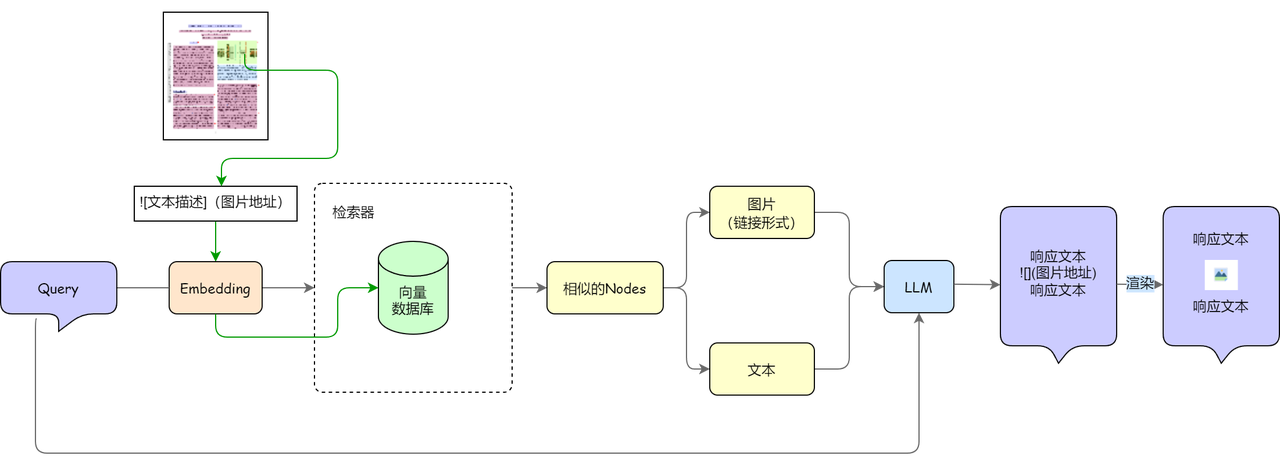
生成图文并茂的响应
![]()
- 图表格式化保存:解析文档时提取图像及其描述,并以 Markdown 格式保存(如:
),方便后续展示。
- 节点类型分类:检索返回结果后,识别哪些是图像节点,为生成环节做好准备(例如生成图像相关内容或链接)。
- 提示词优化:在生成答案时,加入指令提示大模型:如果涉及图像内容,需输出对应链接和解释说明。
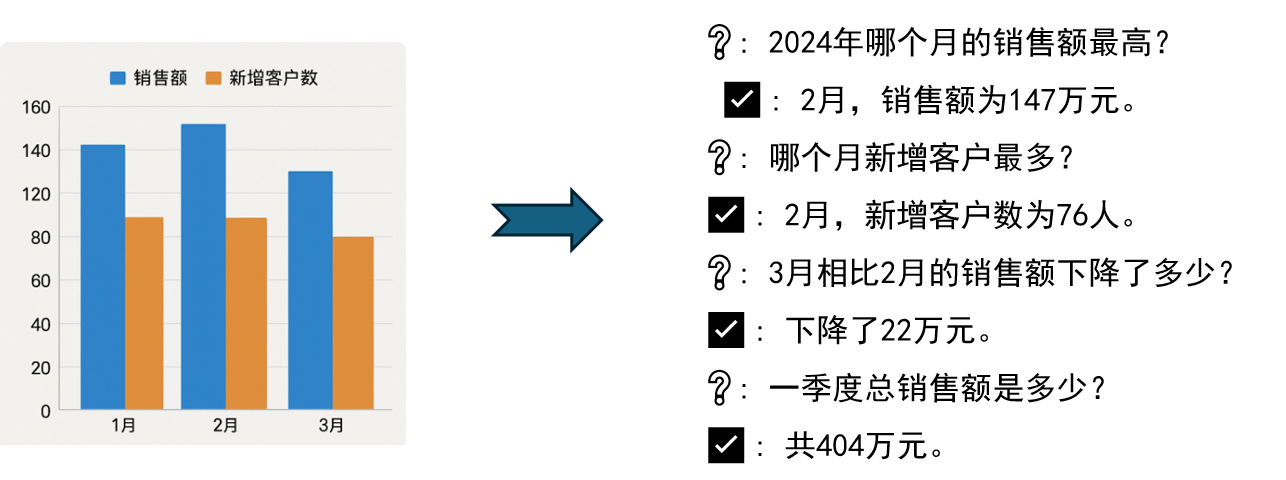
多模态内容向量化效果优化技巧
文本补全:结合图像标题与注解等文本信息
- 策略:将图像描述 + 标题 + 图注 拼接后,送入联合编码模型(如 CLIP)统一向量化。
- 示例及效果:
![]()
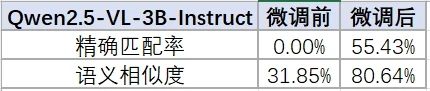
结构化生成:预先从多模态数据中提取 QA 对
- 策略:
- 用 OCR、图像解析等提取关键信息;
- 调用大模型生成 QA 对或摘要,补充至向量库。
- 示例:
![]()
效果:
上下文增强:将上下文一同编码
策略:图像与所在段落/句子拼接编码,使用多模态模型联合处理。
示例及效果:
![]()
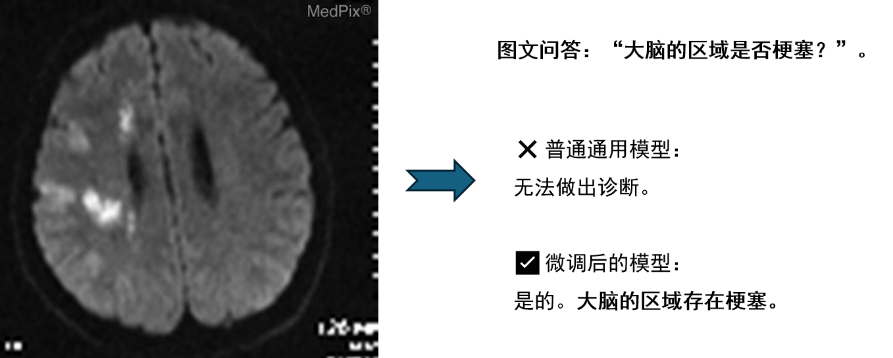
微调多模态模型:提升模型在特定多模态领域内的适应能力
实践举例:
import lazyllm
model_path = 'path/to/Qwen2.5-VL-3B-Instruct'
data_path = 'path/to/vqa_rad_processed/train.json' # 需要将环境中的transformers和llamafactory升级到最新的开发分支
m = lazyllm.TrainableModule(model_path)
.mode('finetune')
.trainset(data_path)
.finetune_method(
(lazyllm.finetune.llamafactory,{
'learning_rate': 1e-4,
'cutoff_len': 5120,
'max_samples': 20000,
'val_size': 0.01,
'num_train_epochs': 2.0,
'per_device_train_batch_size': 16,
}))
m.update()
评测
![]()
测试示例
![]()
微调前:
{
"query": "is the liver visible in the image?",
"true": "no",
"infer": "yes, the liver is visible in the image. it appears as a large, dark gray structure located in the upper left quadrant of the abdomen.",
"exact_score": 0,
"cosine_score": 0.3227266048281184
}
微调后:
{
"query": "is the liver visible in the image?",
"true": "no",
"infer": "no",
"exact_score": 1,
"cosine_score": 1.0
}
效果:
![]()
传统RAG的论文系统
![]()
How — 实施步骤
- Step 1:数据准备
- Step 2:数据处理及组件搭建
- Step 3:应用的流程编排
- Step 4:代码调试
- Step 5:效果校验
- Step 6:体验效果是否符合要求,不符合要求就返回步骤三进行迭代优化。
实践举例
代码实现
import lazyllm
prompt = 'You will play the role of an AI Q&A assistant and complete a dialogue task.'\
' In this task, you need to provide your answer based on the given context and question.'\
' If an image can better convey the information being expressed, please include the image reference'\
' in the text in Markdown format. Keep the image path in its original format.'
documents = lazyllm.Document(dataset_path=tmp_dir.rag_dir,
embed=lazyllm.TrainableModule("bge-large-zh-v1.5"),
manager=True,
store_conf=milvus_store_conf,
doc_fields=doc_fields)
documents.add_reader("*.pdf", MagicPDFReader)
documents.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
with lazyllm.pipeline() as ppl:
ppl.retriever = lazyllm.Retriever(doc=documents, group_name="block", topk=3)
ppl.reranker = lazyllm.Reranker(name='ModuleReranker',
model="bge-reranker-large",
topk=1,
output_format='content',
join=True) | bind(query=ppl.input)
ppl.formatter = (
lambda nodes, query: dict(context_str=nodes, query=query)
) | bind(query=ppl.input)
ppl.llm = lazyllm.TrainableModule('internlm2-chat-7b').prompt(
lazyllm.ChatPrompter(instruction=prompt, extra_keys=['context_str']))
lazyllm.WebModule(ppl, port=23456, static_paths="Stored Images Path").start().wait()
效果展示
![]()
朴素多模态RAG的论文系统
![]()
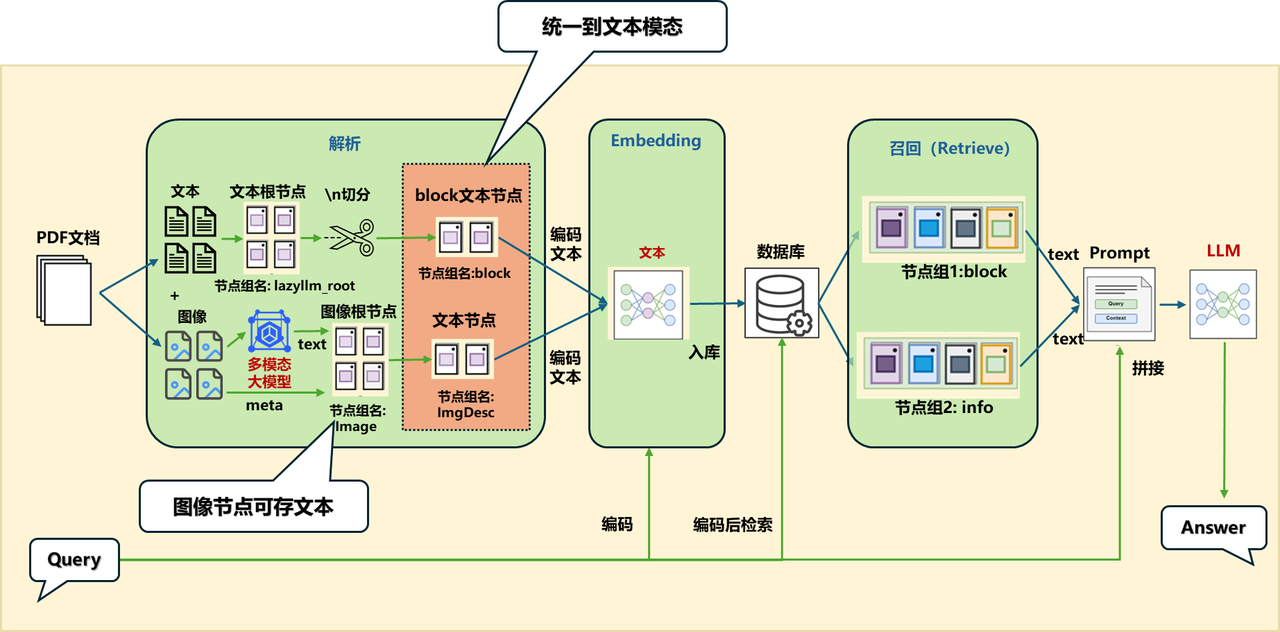
方案1:统一到文本模态
![]()
ImageDocNode节点构建
class MagicPDFReader(ReaderBase):
def __init__(self):
self.image_save_path = get_image_path()
self.model = None
self.vlm = lazyllm.TrainableModule(‘internvl-chat-v1-5’).start() # 初始化一个多模态大模型
def _result_extract(self, content_list):
......
if not content["img_path"]:
...... block['img_desc'] = self.vlm(formatted_query(block["image_path"])) # 利用VLM对图像内容进行解析生成图像的文本描述
def _load_data(self, file: Path, split_documents: Optional[bool] = True, ) -> List[DocNode]:
......
for k, v in element.items(): # 对其中的一个block
......
if "text" in element:
docs.append(DocNode(text=element["text"], metadata=metadata))
elif "img_desc" in element:
image_node = ImageDocNode(text=element["img_desc"],
image_path=element[“image_path”], global_metadata=metadata)# 构建ImageDocNode节点
docs.append(image_node)
else:
docs.append(DocNode(text="", metadata=metadata))
代码实现
documents = lazyllm.Document(
dataset_path=tmp_dir.rag_dir,
embed=lazyllm.TrainableModule("bge-m3"),
manager=False)
documents.add_reader("*.pdf", MagicPDFReader)
documents.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
with lazyllm.pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
ppl.prl.retriever1 = lazyllm.Retriever(documents, group_name="block", similarity="cosine", topk=1)
ppl.prl.retriever2 = lazyllm.Retriever(documents, lazyllm.Document.ImgDesc, similarity="cosine", topk=1)
ppl.prompt = build_vlm_prompt | bind(_0, ppl.input)
ppl.vlm = lazyllm.OnlineChatModule()
lazyllm.WebModule(ppl, port=range(23468, 23470), static_paths=get_image_path()).start().wait()
效果展示
![]()
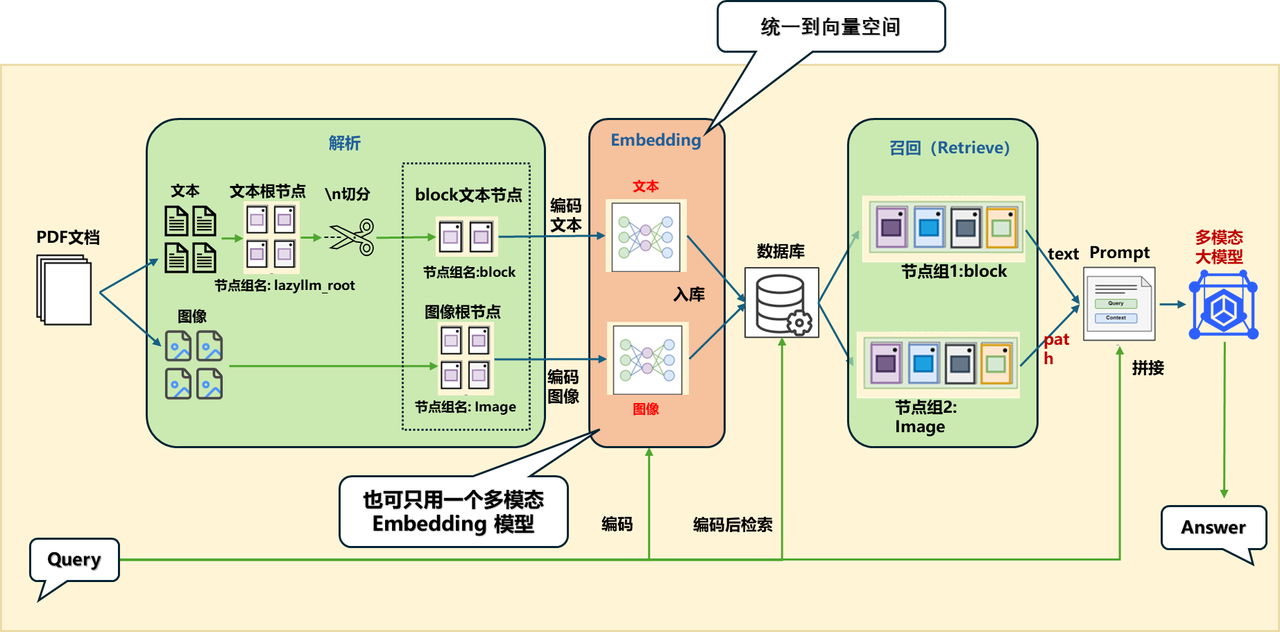
方案2:统一到向量空间
![]()
统一到向量空间的两种方案:
代码实现
- 方案A:不同模态用对应的embedding(下面展示为该方案的具体实现✅):
- 文本:用文本的embedding
- 图像:用图像的embedding
- 方案B:用多模态embedding:
代码实现
embed_multimodal = lazyllm.TrainableModule("colqwen2-v0.1")
embed_text = lazyllm.OnlineEmbeddingModule(
source='qwen', embed_model_name='text-embedding-v1')
embeds = {'vec1': embed_text, 'vec2': embed_multimodal}
documents = lazyllm.Document(
dataset_path=tmp_dir.rag_dir, embed=embeds, manager=False)
documents.add_reader("*.pdf", MagicPDFReader)
documents.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
with lazyllm.pipeline() as ppl:
with lazyllm.parallel().sum as ppl.prl:
ppl.prl.retriever1 = lazyllm.Retriever(documents, group_name="block", embed_keys=['vec1'], similarity="cosine", topk=1)
ppl.prl.retriever2 = lazyllm.Retriever(documents, group_name="Image", embed_keys=['vec2'], similarity="maxsim", topk=2)
ppl.prompt = build_vlm_prompt | bind(_0, ppl.input)
ppl.vlm = lazyllm.OnlineChatModule(source="sensenova", model="SenseNova-V6-Turbo").prompt(lazyllm.ChatPrompter(gen_prompt))
lazyllm.WebModule(ppl, port=range(23468, 23470), static_paths=get_image_path()).start().wait()
效果展示
![]()
效果优化
![]()
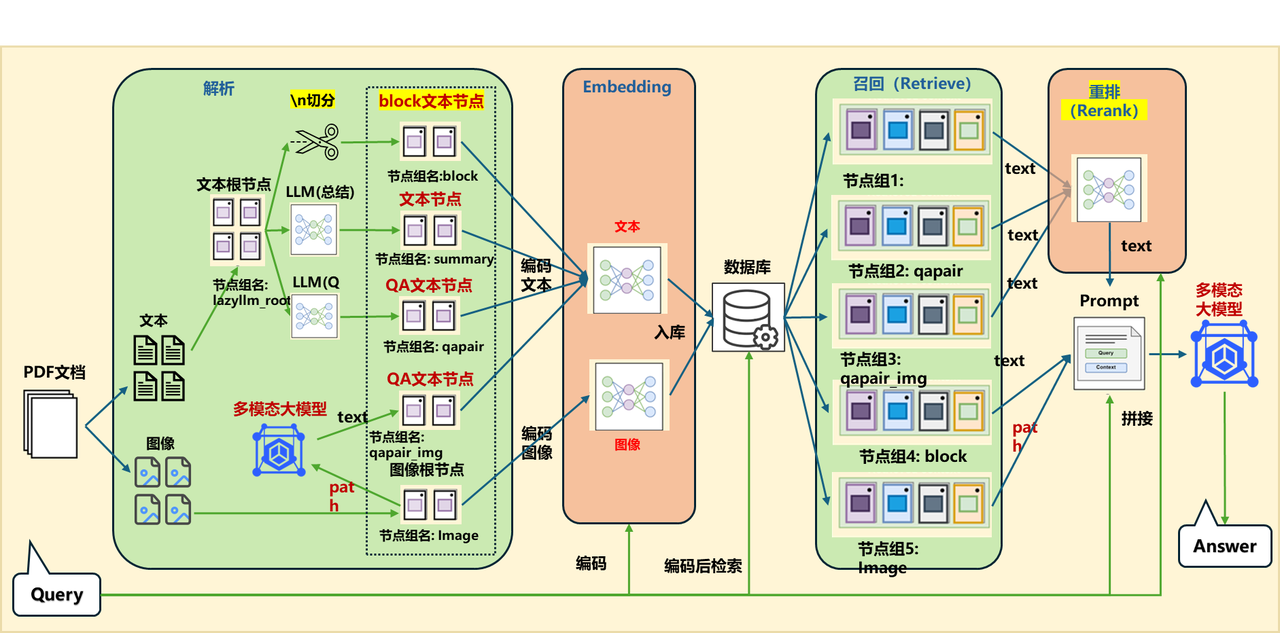
综合方案
![]()
代码实现
embed_mltimodal = lazyllm.TrainableModule("colqwen2-v0.1")
embed_text = lazyllm.TrainableModule("bge-m3")
embeds = {'vec1': embed_text, 'vec2': embed_mltimodal}
qapair_llm = lazyllm.LLMParser(lazyllm.OnlineChatModule(stream=False), language="zh", task_type="qa")
qapair_img_llm = lazyllm.LLMParser(
lazyllm.OnlineChatModule(source="sensenova", model="SenseNova-V6-Turbo"), language="zh", task_type="qa_img")
summary_llm = lazyllm.LLMParser(lazyllm.OnlineChatModule(stream=False), language="zh", task_type="summary")
documents = lazyllm.Document(dataset_path=tmp_dir.rag_dir, embed=embeds, manager=False)
documents.add_reader("*.pdf", MagicPDFReader)
documents.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
documents.create_node_group(name="summary", transform=lambda d: summary_llm(d), trans_node=True)
documents.create_node_group(name='qapair', transform=lambda d: qapair_llm(d), trans_node=True)
documents.create_node_group(name='qapair_img', transform=lambda d: qapair_img_llm(d), trans_node=True, parent='Image')
with lazyllm.pipeline() as ppl:
with lazyllm.parallel().sum as ppl.mix:
with lazyllm.pipeline() as ppl.mix.rank:
with lazyllm.parallel().sum as ppl.mix.rank.short:
ppl.mix.rank.short.retriever1 = lazyllm.Retriever(documents, group_name="summary", embed_keys=['vec1'], similarity="cosine", topk=4)
ppl.mix.rank.short.retriever2 = lazyllm.Retriever(documents, group_name="qapair", embed_keys=['vec1'], similarity="cosine", topk=4)
ppl.mix.rank.short.retriever3 = lazyllm.Retriever(documents, group_name="qapair_img", embed_keys=['vec1'], similarity="cosine", topk=4)
ppl.mix.rank.reranker = lazyllm.Reranker("ModuleReranker", model="bge-reranker-large", topk=3) | bind(query=ppl.mix.rank.input)
ppl.mix.retriever4 = lazyllm.Retriever(documents, group_name="block", embed_keys=['vec1'], similarity="cosine", topk=2)
ppl.mix.retriever5 = lazyllm.Retriever(documents, group_name="Image", embed_keys=['vec2'], similarity="maxsim", topk=2)
ppl.prompt = build_vlm_prompt | bind(_0, ppl.input)
ppl.vlm = lazyllm.OnlineChatModule(source="sensenova", model="SenseNova-V6-Turbo").prompt(lazyllm.ChatPrompter(gen_prompt))
lazyllm.WebModule(ppl, port=range(23468, 23470), static_paths=get_image_path()).start().wait()
效果展示
![]()
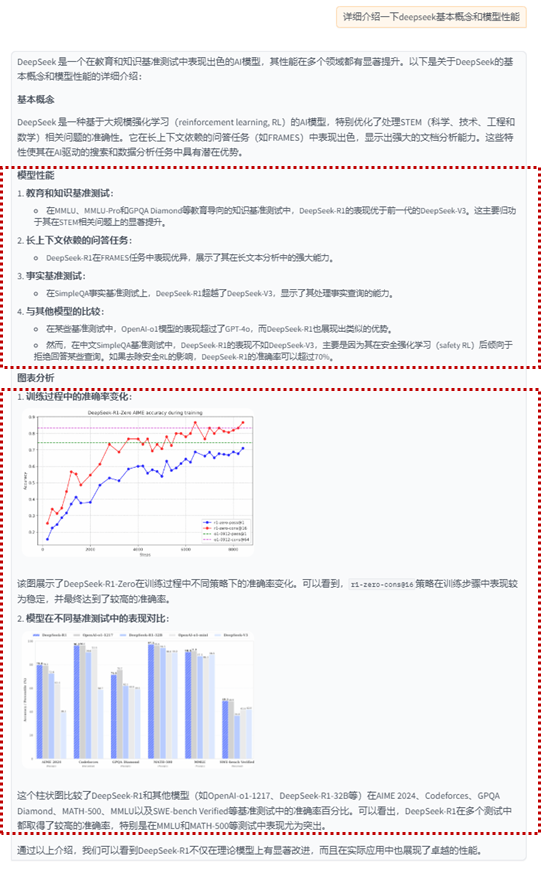
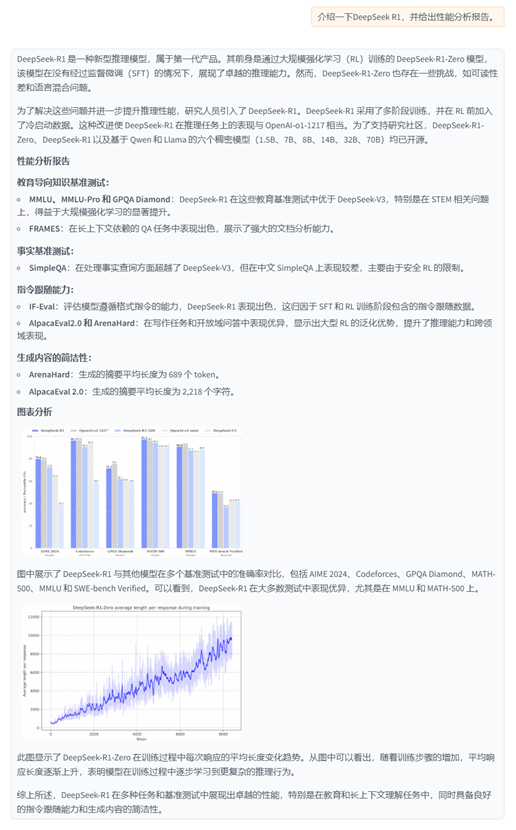
召回内容
内容1:DeepSeek-R1 outperforms DeepSeek-V3 on education benchmarks and long-context QA, excelling in STEM and factual queries via reinforcement learning. However, it underperforms on Chinese SimpleQA due to safety RL restrictions.
内容2:DeepSeek-R1在IF-Eval、AlpacaEval2.0和ArenaHard上表现出色,得益于SFT和RL训练中包含的指令跟随数据。其优于DeepSeek-V3,展示了大型RL的泛化优势,提升推理能力和跨领域表现。生成的摘要长度平均为689个token(ArenaHard)和2218个字符(AlpacaEval2.0),表明其简洁性。
内容3:各模型在多种基准测试中的性能对比,包括MMLU、Codeforces、AIME等,显示不同模型在英语、代码和数学等领域的差异化表现。
内容4: We introduce our frst-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fne-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities. Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors. However, it encounters challenges such as poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeekR1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks. To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
内容5:| | Benchmark (Metric) | Claude-3.5- Sonnet-1022 0513 | GPT-4o DeepSeek V3 | | OpenAI OpenAI 01-mini o1-1217 | DeepSeek R1 |
Image 节点组召回内容
/path/to/images/2c6271b8cecc68d5b3c22e552f407a5e97d34030f91e15452c595bc8a76e291c.jpg
/path/to/images/b671779ae926ef62c9a0136380a1116f31136c3fd1ed3fedc0e3e05b90925c20.jpg
更多技术细节,欢迎移步“LazyLLM”gzh~