原文作者:Akash Ananthanarayanan - F5 NGINX 技术营销经理
如果您正在寻找一种工具来更有效地针对 Web 应用和基础设施进行链路追踪,OpenTelemetry 便可派上用场。通过利用现有 OpenTelemetry NGINX 社区模块对 NGINX 服务器进行监测,您可以收集指标、链路追踪及日志,并更清晰地了解服务器健康状况,以便进行故障排查,并优化 Web 应用,从而提高性能。
不过,由于链路追踪需要性能开销,现有的这一社区模块也会减慢服务器的响应速度,而且还会消耗额外资源,进而增加 CPU 和内存使用率。此外,模块的设置和配置也很麻烦。
NGINX 最近开发了一个原生 OpenTelemetry 模块 ngx_otel_module ,它彻底改变了对请求处理性能的链路追踪。该模块利用遥测调用来监控应用请求和响应,可增强链路追踪能力,不仅便于在 NGINX 配置文件中进行设置和配置,易于用户使用,而且还能够满足 NGINX 开源版和 NGINX Plus 用户的需求。它支持 W3C 上下文传播和 OTLP/gRPC 导出协议,为优化性能提供了全面解决方案。
NGINX 原生 OpenTelemetry 模块是一个动态模块,无需与 NGINX Plus 一同打包。它提供了一系列可靠的功能,包括 API 和键值存储模块。这些功能协同工作,为监控和优化 NGINX Plus 实例性能提供了完整的解决方案。借助 ngx_otel_module,您可获得有关 Web 应用性能的宝贵洞察,并采取措施加以改进。我们强烈建议您试用 ngx_otel_module,了解它如何帮助您实现更出色的成效。
教程概述
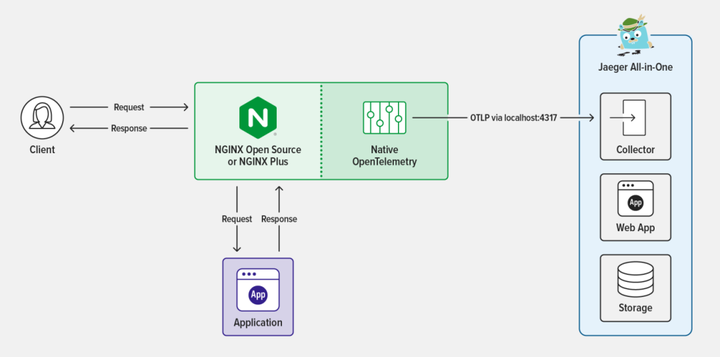
本文提供了分步指南,介绍了如何在 NGINX Plus 中配置 OpenTelemetry,以及如何使用 Jaeger 工具收集和可视化链路追踪数据。OpenTelemetry 是一套功能强大的工具,可提供有关请求路径的全面视图,包括延迟、请求详细信息及响应数据等有价值的信息。这对优化性能和发现潜在问题很有帮助。为了简单起见,我们将 OpenTelemetry 模块、应用及 Jaeger 部署在一个实例中,如下图所示。
![]()
图 1:NGINX OpenTelemetry 架构概览
准备工作
部署 NGINX Plus 并安装 OpenTelemetry 模块
选择合适的环境对于成功部署 NGINX 实例而言至关重要。本教程将带您了解如何部署 NGINX Plus 和安装 NGINX 动态模块。
1. 在支持的操作系统上安装 NGINX Plus。
2. 安装 ngx_otel_module。将动态模块添加到 NGINX 配置目录,以激活 OpenTelemetry:
load_module modules/ngx_otel_module.so;
nginx -t && nginx -s reload
部署 Jaeger 和 echo 应用
现有多种选项可用于查看链路追踪。本教程使用 Jaeger 收集和分析 OpenTelemetry 数据。Jaeger 提供了一个高效的用户友好型界面,用于收集和可视化链路追踪数据。数据收集完成后,部署一个简单的 Docker 应用 mendhak/http-https-echo。该应用以 JSON 格式返回 JavaScript 的请求属性。
1. 使用 docker-compose 部署 Jaeger 和 http-echo 应用。您可通过复制下面的配置并将其保存在所选目录中,快速创建一个 docker-compose 文件。
version: '3'
Services: jaeger: image: jaegertracing/all-in-one:1.41 container_name: jaeger ports: - "16686:16686" - "4317:4317" - "4318:4318" environment: COLLECTOR_OTLP_ENABLED: true
http-echo: image: mendhak/http-https-echo environment: - HTTP_PORT=8888 - HTTPS_PORT=9999 ports: - "4500:8888" - "8443:9999"
2. 安装 Jaeger 多合一链路追踪和 http-echo 应用。运行此命令:
3. 运行 docker ps -a 命令来验证容器是否安装成功。
$docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUSPORTS NAMES
5cb7763439f8 jaegertracing/all-in-one:1.41 "/go/bin/all-in-one-…" 30 hours ago Up 30 hours 5775/udp, 5778/tcp, 14250/tcp, 0.0.0.0:4317-4318->4317-4318/tcp, :::4317-4318->4317-4318/tcp, 0.0.0.0:16686->16686/tcp, :::16686->16686/tcp, 6831-6832/udp, 14268/tcp jaeger
e55d9c00a158 mendhak/http-https-echo "docker-entrypoint.s…" 11 days ago Up 30 hours 8080/tcp, 8443/tcp, 0.0.0.0:8080->8888/tcp, :::8080->8888/tcp, 0.0.0.0:8443->9999/tcp, :::8443->9999/tcp ubuntu-http-echo-1
现在,您只需在浏览器中输入 http://localhost:16686 这个地址,即可访问 Jaeger。请注意,您可能无法立即看到任何系统链路追踪数据,因为这些数据正在发送到控制台。不过别担心!只需将链路追踪信息以 OpenTelemetry Protocol (OTLP) 格式导出,该问题便迎刃而解。下一节在介绍如何通过配置 NGINX 将链路追踪数据发送到 Jaeger 时会描述此操作。
在 NGINX 中配置 OpenTelemetry 以进行链路追踪
本节将分步演示如何在 NGINX Plus 中使用键值存储设置 OpenTelemetry 指令。这一功能强大的配置支持精确监控和分析流量,有助于优化应用的性能。本节结束后,您将掌握如何利用 NGINX OpenTelemetry 模块对应用的性能进行链路追踪。
有了 NGINX 配置文件,设置和配置遥测数据收集变得轻而易举。借助 ngx_otel_module,用户可使用强大的协议感知型链路追踪工具,快速识别和解决应用问题。该模块是应用开发和管理工具集的重要补充,可以帮助您提高应用的性能。
NGINX 提供新的指令来帮助您根据特定需求进一步优化 OpenTelemetry 部署。这些指令旨在提高应用的性能和效率。
-
otel_exporter — 设置 OpenTelemetry 数据的参数,包括 endpoint、interval、batch size 及 batch count。这些参数对成功导出数据至关重要,必须准确定义。
-
otel_service_name — 设置 OpenTelemetry 资源的服务名称属性,以方便管理和改进链路追踪。
-
otel_trace — 现在只需通过指定一个变量即可启用或禁用 OpenTelemetry 链路追踪,从而灵活地管理链路追踪设置。
-
otel_span_name — 默认情况下,OpenTelemetry span 的名称设置为请求的位置名称。值得一提的是,该名称不仅可进行自定义,还能够按需添加变量。
配置示列
以下列举了使用 NGINX Plus 键值存储在 NGINX 中配置 OpenTelemetry 的方法示例。NGINX Plus 键值存储模块提供了一个重要用例,可对 OpenTelemetry span 及其他 OpenTelemetry 属性进行动态配置,从而简化链路追踪和调试流程。
以下是使用键值存储动态启用 OpenTelemetry 链路追踪的示例:
http { keyval "otel.trace" $trace_switch zone=name;
server { location / { otel_trace $trace_switch; otel_trace_context inject; proxy_pass http://backend; }
location /api { api write=on; } } }
接下来是使用键值存储动态禁用 OpenTelemetry 链路追踪的示例:
location /api { api write=off; }
下面是 NGINX OpenTelemetry span 属性配置示例:
user nginx;worker_processes auto;load_module modules/ngx_otel_module.so;error_log /var/log/nginx debug;pid /var/run/nginx.pid;
events { worker_connections 1024;}
http { keyval "otel.span.attr" $trace_attr zone=demo; keyval_zone zone=demo:64k state=/var/lib/nginx/state/demo.keyval;
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; include mime.types; default_type application/json; upstream echo { server localhost:4500; zone echo 64k; } otel_service_name nginx; otel_exporter { endpoint localhost:4317; }
server { listen 4000; otel_trace on; otel_span_name otel; location /city { proxy_set_header "Connection" "" ; proxy_set_header Host $host; otel_span_attr demo $trace_attr; otel_trace_context inject; proxy_pass http://echo; } location /api { api write=on; } location = /dashboard.html { root /usr/share/nginx/html; } }
}
最后,在 NGINX Plus API 中添加 span 属性,具体如下所示:
curl -X POST -d '{"otel.span.attr": "<span attribute name>"}' http://localhost:4000/api/6/http/keyvals/<zone name>
测试配置
1. 若要生成链路追踪数据,首先打开终端窗口。接下来,输入此命令来创建数据:
$ curl -i localhost:4000/city
输出结果如下:
HTTP/1.1 200 OK
Server: nginx/1.25.3
Date: Wed, 29 Nov 2023 20:25:04 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 483
Connection: keep-alive
X-Powered-By: Express
ETag: W/"1e3-2FytbGLEVpb4LkS9Xt+KkoKVW2I"
{
"path": "/city",
"headers": {
"host": "localhost",
"connection": "close",
"user-agent": "curl/7.81.0",
"accept": "*/*",
"traceparent": "00-66ddaa021b1e36b938b0a05fc31cab4a-182d5a6805fef596-00"
},
"method": "GET",
"body": "",
"fresh": false,
"hostname": "localhost",
"ip": "::ffff:172.18.0.1",
"ips": [],
"protocol": "http",
"query": {},
"subdomains": [],
"xhr": false,
"os": {
"hostname": "e55d9c00a158"
},
"connection": {}
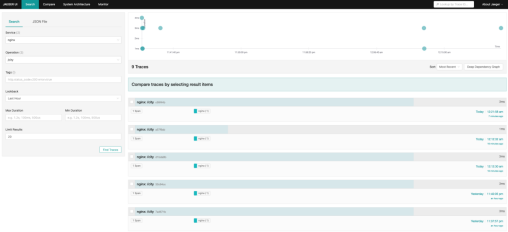
2. 现在,您需要确保 OTLP 输出器正常运行,以便访问链路追踪。首先,打开浏览器并访问 Jaeger 用户界面:http://localhost:16686。页面加载完毕后,点击标题栏中的 Search (搜索)按钮。接下来,从 Service (服务)字段的下拉菜单中选择以 NGINX 开头的服务。然后,从 Operation (操作)下拉菜单中选择名为“ Otel ”的操作。为了便于发现问题,请点击 Find Traces (查找链路追踪)按钮,以实现链路追踪可视化。
![]()
图 2:Jaeger 仪表盘
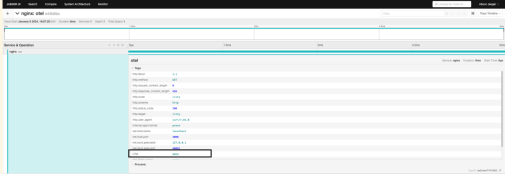
3. 若要获取对特定链路追踪的更详细、更全面的分析,请点击其中一个可用的链路追踪,从而获得有关所选链路追踪的详细信息。在下面的链路追踪中,您可以查看 OpenTelemetry 指令 span 属性和链路追踪的非指令,从而更好地了解手头数据。
![]()
图 3:OpenTelemetry 链路追踪的详细分析
-
demo – Otel — OpenTelemetry span 属性名称
-
http.status_code field – 200 — 表示创建成功
-
otel.library.name – nginx — OpenTelemetry 服务名称
结语
NGINX 现在实现了对 OpenTelemetry 的内置支持,对于在复杂的应用环境中链路追踪请求和响应而言,这是一项重大进展。该功能可简化流程并确保无缝集成,有助于开发人员更轻松地监控和优化其应用。
尽管在 NGINX Plus R18 中引入的 OpenTracing 模块现已弃用,并将从 NGINX Plus R34 及更新版本中被删除,但在此之前,该模块仍将包含在所有 NGINX Plus 版本中。不过,我们还是建议大家使用 OpenTelemetry 模块,后者将自 NGINX Plus R29 开始引入。