导读:「分布式锁」技术科普系列,由 NebulaGraph 存储负责人 @critical27 整理自己的“学习笔记”而成。在单体应用中我们通过锁实现共享资源访问,而在分布式系统中,则通过分布式锁解决。NebulaGraph 作为一款分布式图数据库,邀请大家一起学习分布式系统架构中的分布式锁~
![图片]()
本文首发于「NebulaGraph 技术社区」,更多产品资讯请访问「NebulaGraph 官网」
🔍在开始本期的学习之间,推荐阅读⬇️
技术科普|深入理解分布式锁的原理与实现 part 1
上期文末卖了个关子:当 Redlock 提出之后,DDIA 的作者 Martin Kleppman 质疑了这个算法,后来 Redis 的作者 Antirez 也下场进行了反驳。
两个人都是大牛,到底谁说的更有道理呢?本期来看看大牛们如何理解分布式锁。
一、Argues about Redlock
在 Redlock 提出之后,Designing Data-Intensive Applications 的作者 Martin Kleppmann 就在博客《How to do distributed locking》提出了质疑,Redlock 也作为一个反例被写进了这本书里(只不过没有点名是 Redlock)。
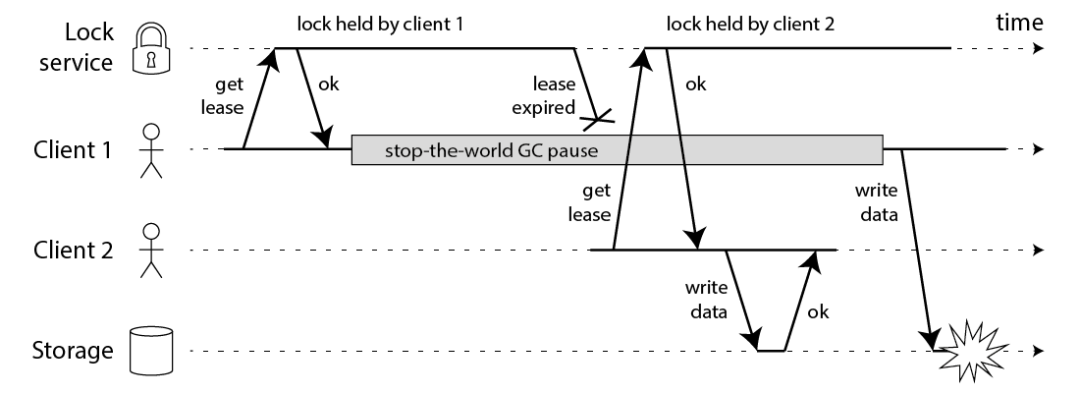
Martin Kleppmann 举了一个反例,客户端 1 在获取到分布式锁之后操作共享资源之前,发生了 GC,而 GC 期间锁又过期了。此时客户端 2 也可以获取到分布式,进而出现了两个客户端同时操作共享资源的问题。
![figure]()
这里面 stop-the-world GC 只是一种客户端被阻塞的情况,比如文章中提到好几种可能:
-
GC: 任何 Garbage Collector 实现都可能需要 stop-the-world
-
操作共享资源时,发生了 network delay
-
发生 page fault,需要将硬盘上的数据加载进内存
-
进程收到了 SIGSTOP 或者 SIGPAUSE 信号
-
时钟漂移,甚至闰秒问题
除了上面的问题,Martin Kleppmann 还指出 Redlock 有以下缺陷,其核心在于 Redlock 是依赖于本地时间的比较来保证分布式锁互斥的。
Redlock 主要有两个地方使用了本地时间,可以参照前文理解:
Redis 使用 gettimeofday 来获取本地时间,这个时钟不是原子递增的,会出现时钟回退和漂移。因此,而 Redlock 却重度依赖于本地时间,又或者对网络延迟和超时时间做了时间上的假设,因此不是一个安全的分布式锁实现。
原文如下:
"For algorithms in the asynchronous model this is not a big problem: these algorithms generally ensure that their safety properties always hold, without making any timing assumptions. Only liveness properties depend on timeouts or some other failure detector. In plain English, this means that even if the timings in the system are all over the place (processes pausing, networks delaying, clocks jumping forwards and backwards), the performance of an algorithm might go to hell, but the algorithm will never make an incorrect decision."
"However, Redlock is not like this. Its safety depends on a lot of timing assumptions: it assumes that all Redis nodes hold keys for approximately the right length of time before expiring; that the network delay is small compared to the expiry duration; and that process pauses are much shorter than the expiry duration."
博客里面举的一个反例如下,假设 ABCDE 组成一个 5 节点的 Redis 分布式锁集群:
这个例子其实和 Redis 文档里面关于持久化一部分的例子几乎如出一辙,问题都出在其中一个节点在不超过 TTL 的时间内两次上锁成功。只不过文档中是节点发生了重启,而此处则是发生了时钟跳变。
如果我们假设真的不会发生时钟跳变,那么套用前面的 GC,一样可以复现问题:
小结
Martin Kleppmann 认为 Redlock 依赖于以下的假设:
-
有上限的网络延迟
-
有上限的进程暂停时间
-
有上限的时钟漂移
只要上面的任何一个假设在真实环境中不满足,Redlock 就不能保证 safety.
二、Fencing token
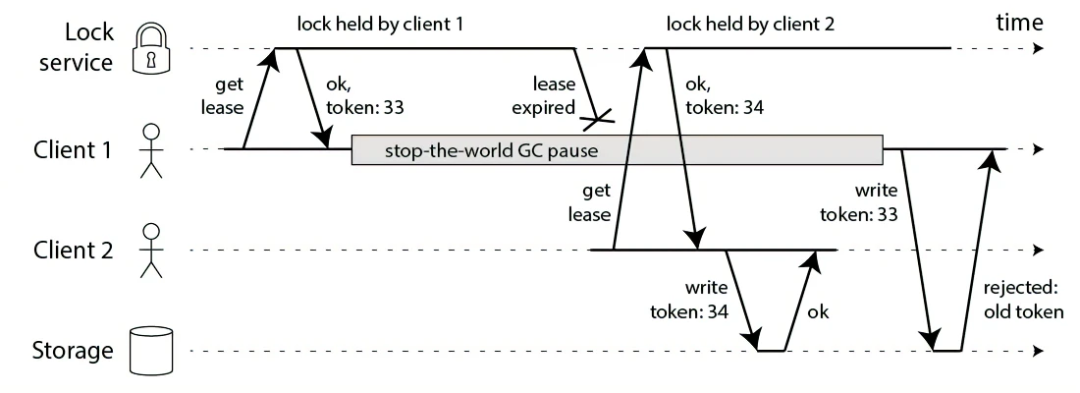
除此之外,Martin Kleppmann 提出了一个解决方案:每次分布式锁返回成功时,需要携带一个自增的 token. 客户端在操作共享资源时,需要携带这个 token. 而共享资源可以比较当前已经使用的最大 token,拒绝掉携带过期 token 的请求。通过每次生成的自增 token,去除了对本地时钟的依赖。
![figure]()
比如还是前面的例子,客户端 1 获取了分布式锁,token 为 33,然后被 GC 阻塞住。客户端在锁过期之后获取了分布式锁,token 为34,并操作了共享资源。当客户端 1 恢复时,再用 token 为 33 发送请求时,会被共享资源拒绝。
然而 Redlock 本身的限制导致不能使用 fencing token 来解决这些问题,一个核心点就在于 Redlock 的多个 Redis 节点都是主库,并且互相不通信,因此各个节点之间很难生成一个一致的自增 token 返回给客户端。
三、Is Redlock safe?
Redis 的作者 Antirez 之后也进行了反驳:
"In this analysis I’ll analyze Martin’s analysis so that other experts in the field can check the two documents (the analysis and the counter-analysis), and eventually we can understand if Redlock can be considered safe or not."
Antirez 的文章总结下来有几个论点:
论点 1 :Martin 提出的 fencing token 不是必须的
这里需要从两个方面进行解释:
- 是不是自增 id 关系不大,比如 Redlock 使用 /dev/urandom 中的 20 个字节作为 uuid,也能够通过 read-modify-write 进行比较(冲突概率认为极低)。比如往 MySQL 中更新记录可以这么做:
UPDATE table T SET val = $new_val WHERE id = $id
- 如果共享资源已经能通过某种机制拒绝掉过期请求(比如上面写入 MySQL),这种情况下就不需要使用分布式锁,直接通过 MySQL 中的记录不就好了吗?通常使用分布式锁的时候,都是因为共享资源不能提供类似分布式锁的互斥能力,比如写一个文件。
Antirez 的原话如下,这个论点我是比较 buy-in 的。
"I want to mention again that, what is strange about all this, is that it is assumed that you always must have a way to handle the fact that mutual exclusion is violated. Actually if you have such a system to avoid problems during race conditions, you probably don’t need a distributed lock at all, or at least you don’t need a lock with strong guarantees, but just a weak lock to avoid, most of the times, concurrent accesses for performances reasons."
论点 2 :其余问题不只是存在于 Redlock
针对 Martin 博文中对 Redlock 不能应对 NPC 问题(Network delay, Process pause, Clock drift),Antirez 也进行了反驳。
首先是时钟漂移,Redlock 的确假设了各个时钟之间的速度是相近的,也就是时钟偏移量是有上限的,但 Antirez 认为这个时钟模型是符合现实情况的,事实上的确也如此。至于 Martin 文章中提到的时钟跳变,主要出现在两种情形:
"The above two problems can be avoided by “1” not doing this (otherwise even corrupting a Raft log with “echo foo > /my/raft/log.bin” is a problem), and “2” using an ntpd that does not change the time by jumping directly, but by distributing the change over the course of a larger time span."
这的确也是一种解决的技术手段,不过这就对对 Redis 分布式锁进行运维的人员就有要求了,不是所有人都看到过这番争论的。
论点 3 :网络延迟和进程暂停相关问题
首先 Antirez 回顾了下 Redlock 的基本流程:
1. Get the current time.
2. All the steps needed to acquire the lock.
3. Get the current time, again.
4. Check if we are already out of time, or if we acquired the lock fast enough.
5. Do some work with your lock.
在第一步和第三步分别获取了一次本地时间,如果 Network delay 和 Process pause 发生在了第一步和第三步之间,那通过两次本地时间的比较是能够发现的。而第一步和第三步的时间间隔也很短,因此时钟漂移的影响可以忽略不计,但时钟跳变只能按前面所说的方法进行规避了。
这里举了一个例子:
当客户端发送请求尝试获取锁时,服务端已经成功授权锁,并发送了响应。然而此时发生网络丢包或者重传,导致当客户端收到响应时候,服务端已经认为过期了。所以客户端在收到响应时,网络延迟早就发生了,客户端也无能为力。客户端能做的就是必须检查我还有多少时间可以用来操作共享资源,这个检查是所有带自动过期的分布式锁算法都需要的。
那么只有 Network delay 和 Process pause 发生在第三步以后,才可能出现问题。而 Antirez 再次强调这是所有分布式锁服务都会遇到的问题,即客户端认为获取锁成功,而服务端已经认为锁过期的情况。即便使用 ZooKeeper 来作为分布式锁也一样会遇到问题。
这里简单介绍 ZooKeeper 是如何实现的分布式锁的。
1. 客户端 1 和 2 都尝试创建临时节点 ZNode,例如 /lock
2. 假设客户端 1 请求先到达,则加锁成功,客户端 2 加锁失败
3. 客户端 1 操作共享资源
4. 客户端 1 删除 /lock 节点,释放锁
ZooKeeper 不像 Redis 那样,需要考虑锁的过期时间问题,它是采用了临时节点,保证客户端 1 拿到锁后,只要连接不断,就可以一直持有锁。ZooKeeper 的客户端在创建临时节点后,会在和服务端的 Session 中不断发送心跳来续约,保证服务端。如果客户端的心跳由于 crash 或者 GC 终端,那么这个临时节点会自动删除,保证了锁一定会被释放。
我们把之前的异常套用在 ZooKeeper 上:
1. 客户端 1 创建临时节点 /lock 成功,拿到了锁
2. 客户端 1 发生 GC,并一直卡住
3. 客户端 1 无法给 Zookeeper 发送心跳,Zookeeper 认为过期把临时节点 /lock 删除
4. 客户端 2 创建临时节点 /lock 成功,拿到了锁
5. 客户端 1 进程此时 GC 结束
6. 客户端 1 和 2 都认为自己持有分布式锁
因此,即便是使用 Martin 推荐的 ZooKeeper 来做分布式锁服务,也无法完全避免 NPC 的问题。
四、结论
双方其实说的都有道理,这更从侧面验证了实现一个分布式锁服务本质上就是要实现一致性共识。而一个通常意义下的分布式锁服务,是无法在极端情况下保证 safety 和 liveness 的。
Reference
[1]万字长文说透分布式锁:https://zhuanlan.zhihu.com/p/403282013
[2]Distributed Locks with Redis:https://redis.io/docs/latest/develop/use/patterns/distributed-locks
[3]Redis 实现分布式锁:https://juejin.cn/post/6975069367574888478
[4]How to do distributed locking:https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
[5]Is Redlock safe?:https://antirez.com/news/101
[6]Redis Redlock 的争论:https://juejin.cn/post/6976538149904678925
[7]Because Coordinating Distributed Systems is a Zoo:https://zookeeper.apache.org/doc/current/zookeeperProgrammers.html
NebulaGraph 邀你参加开源之夏🌟⬇️
开源之夏|从 NebulaGraph 开启你的图数据库开源之旅!