你了解存算分离吗?
在 2025 年的今天,这已是技术圈的"常识"。存算分离,简单来说就是将计算资源与存储资源解耦,分别部署在不同的服务器或集群之上。计算层负责数据的处理与分析,存储层专注于数据的持久化和管理。每一层都可以独立扩容和收缩,实现灵活的资源调度和高可用架构。
![]()
以上是存算分离的基础版本,它让企业可以按需扩展存储容量和计算能力,打破以往"一刀切"的资源瓶颈。很多主流数据平台都开始沿用这一范式,从云数据库到分布式数据仓库,存算分离早已成为行业的标配。
但行业实践告诉我们,这只是存算分离的"初级形态"。随着数据量、业务场景的复杂化,新的挑战不断涌现。
存算分离的进阶版本 V1.0:元数据分离与云原生
在实际业务场景中,海量数据带来的不只是存储压力,更有多种工作负载(如批处理、实时分析、交互查询等)叠加。仅靠简单的存算分离,难以实现针对不同负载的资源精细调度与优化。
![]()
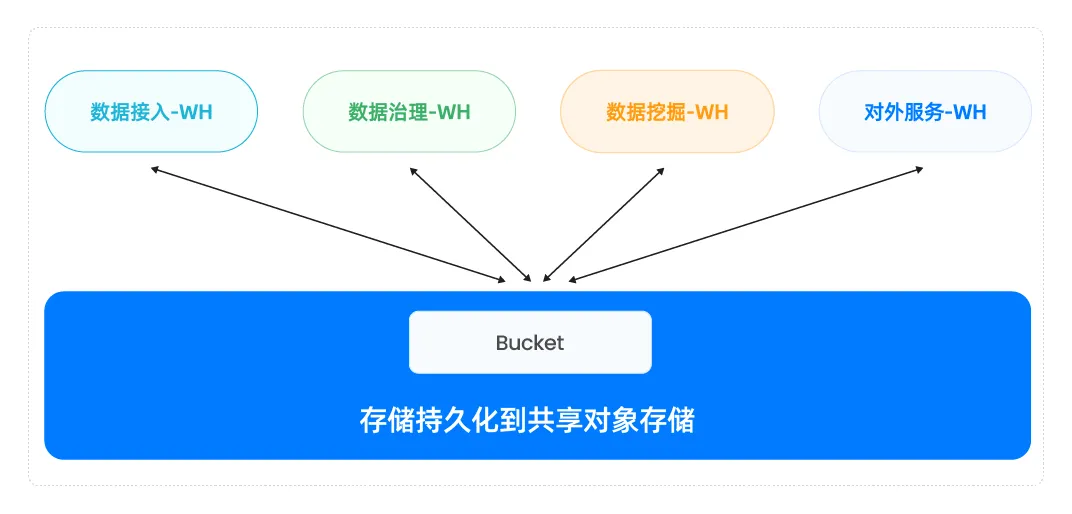
要破解这个难题,如果是针对每个负载都去优化定制分配资源,上面初级的存算分离架构无法搞定。于是,部分数据库将元数据服务(如表结构、分区、权限等)从计算层抽离出来,形成独立服务。计算节点则可以按业务需求,分拆为多个集群,实现多租户与多负载的弹性调度。
![]()
与此同时,云原生技术如 Kubernetes(K8s)赋予计算层无限弹性,底层存储则使用云对象存储,形成真正意义上的"云原生存算分离"架构。这意味着,一份数据可以被多个计算集群高效共享,每个集群可以实现独立地扩容和收缩。这样的存算分离架构才称得上是完美架构。
![]()
Databend 正是这样一套代表性架构。它采用对象存储承载全部数据,计算节点运行在 K8s 之上,实现弹性伸缩,多集群同时对外服务,支持多种工种负载,合理优化资源配置,充分释放存算分离的红利。
极致并发与双层缓存:存算分离的高阶版本 V2.0
存算分离带来的资源独立、弹性扩展确实强大,但在极端高并发或热点数据频繁请求时,也暴露出新的瓶颈------远程存储访问带来的额外延迟和带宽压力,可能导致某个业务计算集群压力陡增,影响整体性能。
![]()
为此,先进的数据平台(如 Databend)在架构中引入了"双层缓存"机制:
- 本地磁盘缓存(Local Disk Cache) :将热点数据缓存在计算节点本地磁盘,极大减少远程数据拉取的次数和延迟。
- 内存 缓存(Memory Cache) :将高频访问数据直接缓存于内存,进一步加速响应。配合磁盘缓存形成双层缓存体系,帮助应对高并发请求。
这样一来,计算节点能够更快地响应查询请求,即便面对百万级高并发访问,也能保证系统稳定与高效。
这种架构看起来已经很完美了,但感觉还不能根本上解决单集群遇到热点集群瓶颈的问题。为应对超大规模并发,Databend 提出了 Multi Cluster 架构。
![]()
即通过多个计算集群并行基于同一份数据,共同承担该业务的并发请求,实现资源横向扩展。每个集群都可独立扩容、缩容,无状态化管理,极大提升了系统吞吐和弹性。遇到高峰压力,集群"横向生长";负载减少时,自动收缩,降低资源浪费。
原生外部表:解锁数据湖仓灵活性
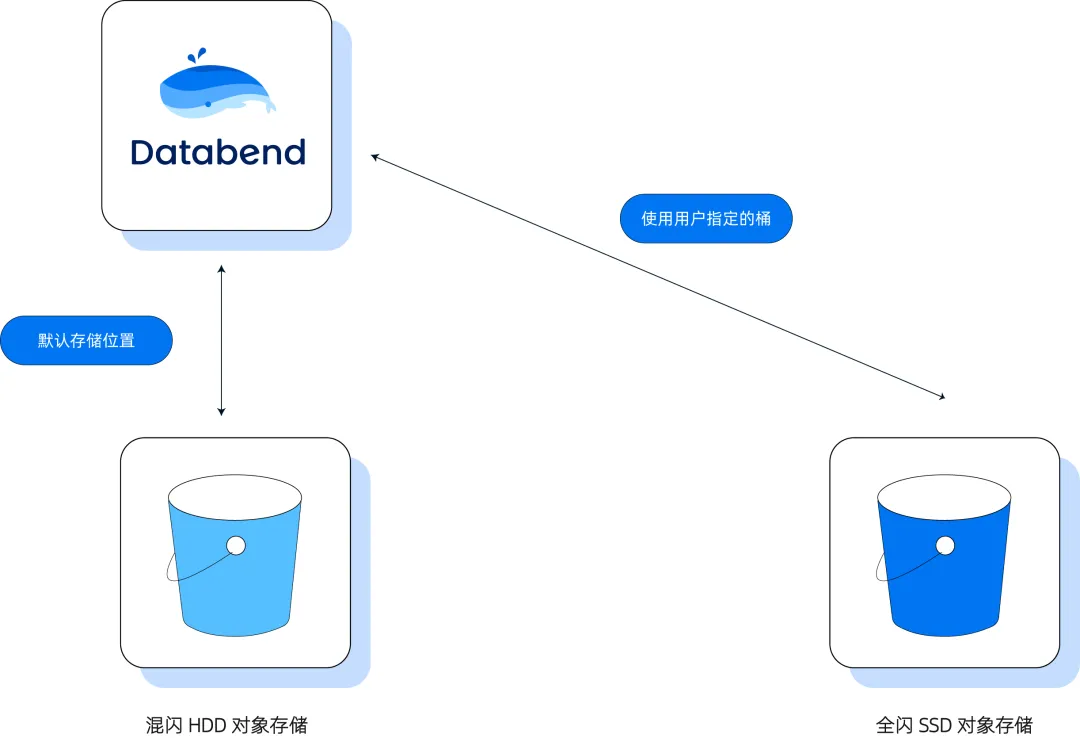
存算分离架构下,底层对象存储的选择与能力变得尤为关键。以往,很多人认为对象存储只能用于数据归档与备份,难以承担高并发 OLAP 场景。但随着技术进步,特别是国内外云服务的演化,越来越多企业采用了池化存储方案:一方面用基于 SSD 的高性能块存储,另一方面用基于 HDD 或全闪的对象存储。AI 场景的兴起,更推动了全闪对象存储对传统块存储的替代。 ![]()
Databend 在此基础上又提出了"原生外部表"方案:用户可将高频并发数据直接放置于高速对象存储,对分析型数据(ADS 层)也可直接利用全闪对象存储,加之 Multi Cluster 架构,实现真正意义上的湖仓一体、弹性资源、极速响应。
不仅如此,Databend Cloud 支持用户用外部表方案,把数据放在自己的对象存储桶(Bucket)中,再利用 Databend Cloud 弹性计算层提供托管服务,享受架构升级、服务可用性保障和扩缩容的全部红利,大幅降低技术门槛和成本------实践证明,许多用户将原有 Snowflake 成本直接降低 50%。
一份数据 全局共享:打破 数据孤岛 与同步难题
随着业务规模扩大,数据同步与一致性成为企业数据架构的一大痛点。传统方案下,每天的数据同步任务可能达到几十万乃至上百万级别,数据一致性难以保障,数据孤岛问题严重。
![]()
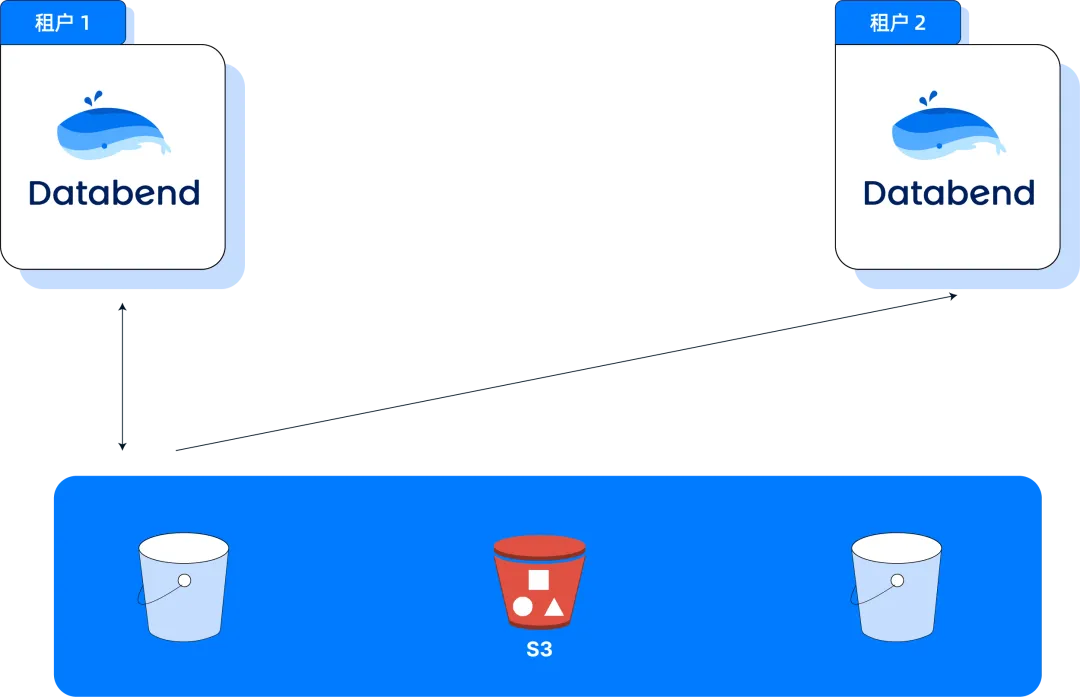
而基于存算分离和对象存储的新架构,Databend 推出了"数据共享"能力。在 External Table 基础上,通过 Attach Table 功能,可以实现一份数据对多个租户、多个集群全局只读共享。无需繁琐的数据迁移和同步,一份数据即可被多个下游业务系统同时高效访问,极大提升数据治理和协作效率。
Databend 通过这项创新,已帮助企业用户每年减少了数十万条数据同步任务,成为现代数据平台打破数据孤岛的典范实践。
展望:存算分离的未来与行业价值
存算分离架构的不断进化,犹如为企业数据基础设施注入了无限活力与弹性。从最初的计算与存储解耦,到多集群高并发支持、对象存储升级,再到支持企业内部和企业间的数据无缝共享,每一步革新都在重塑数据处理的未来。Databend紧密贴合云平台基础设施的演变,巧妙利用云端资源,致力于为用户打造简单易用且成本低廉的基础架构,成为连接用户与云厂商的坚实桥梁。每一项技术突破背后,都蕴藏着对用户核心需求的深刻洞察与创新精神。
如今,Databend作为领先的云原生存算分离平台,已经在高频交易、生物医药、数据交易、游戏及电商等多个领域成功落地,助力企业显著降低成本、提升效率,激发无限创新潜能。展望未来,随着人工智能与数据湖仓的深度融合,存算分离架构将引领更多行业级应用和数据协作新模式,开启智能数据时代的新篇章。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式湖仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn
💻 Wechat:Databend
✨ GitHub:github.com/databendlab...