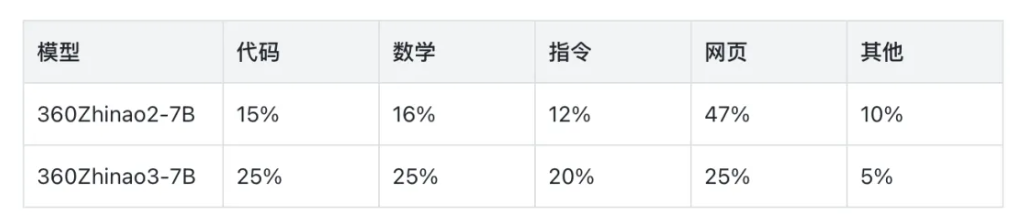
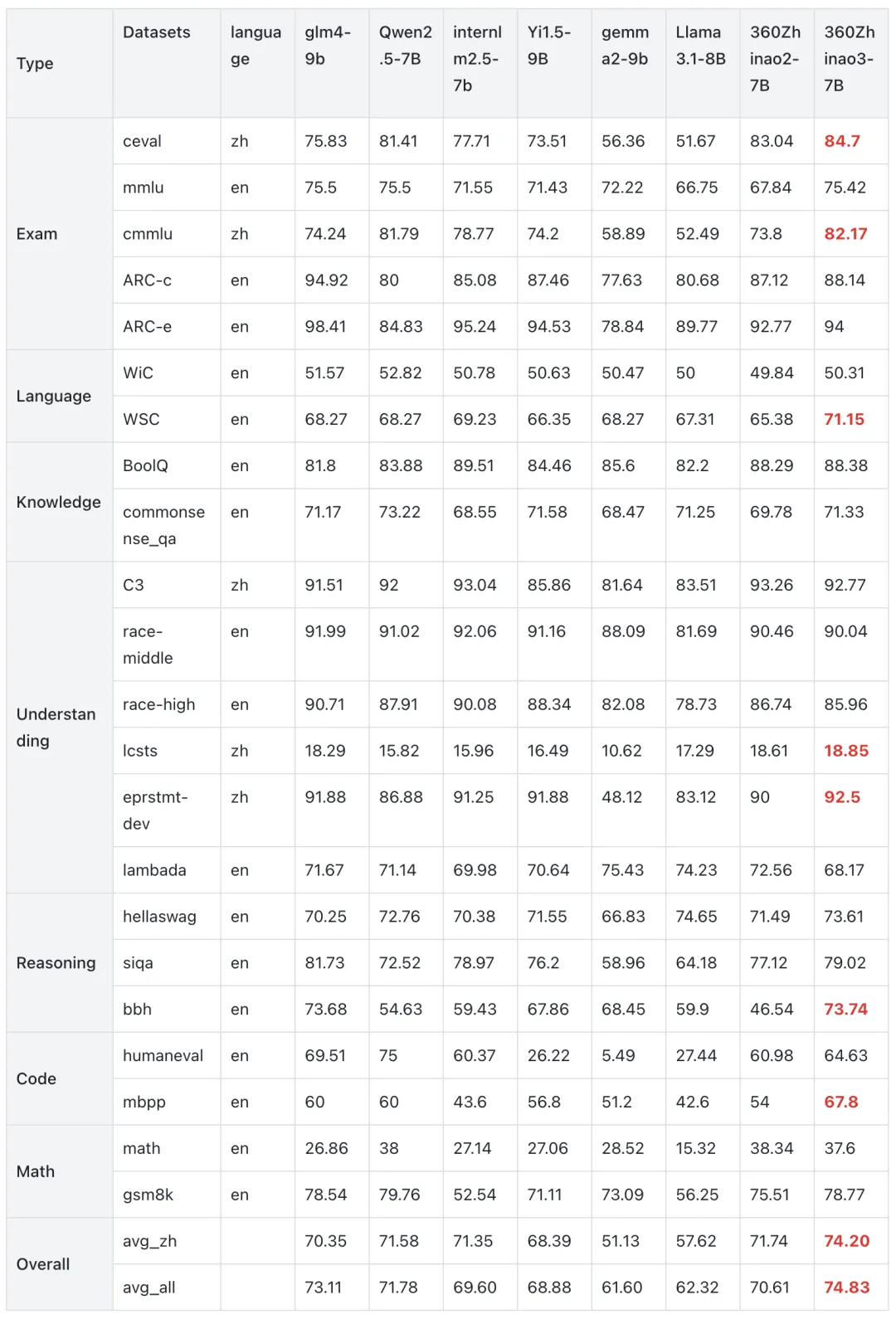
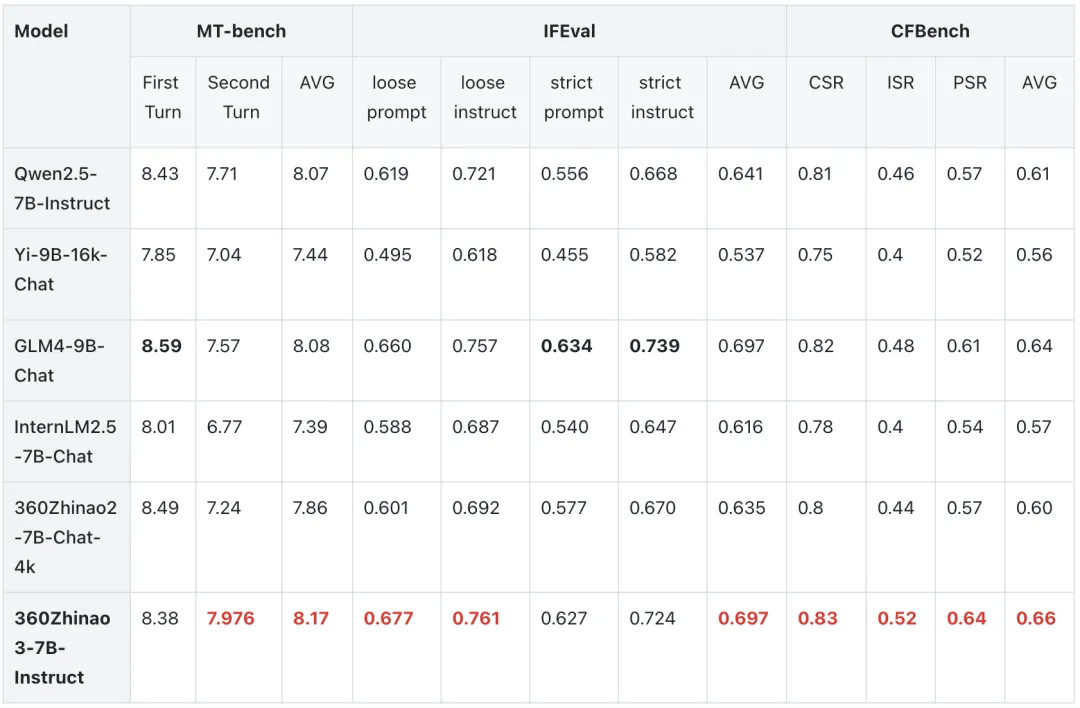
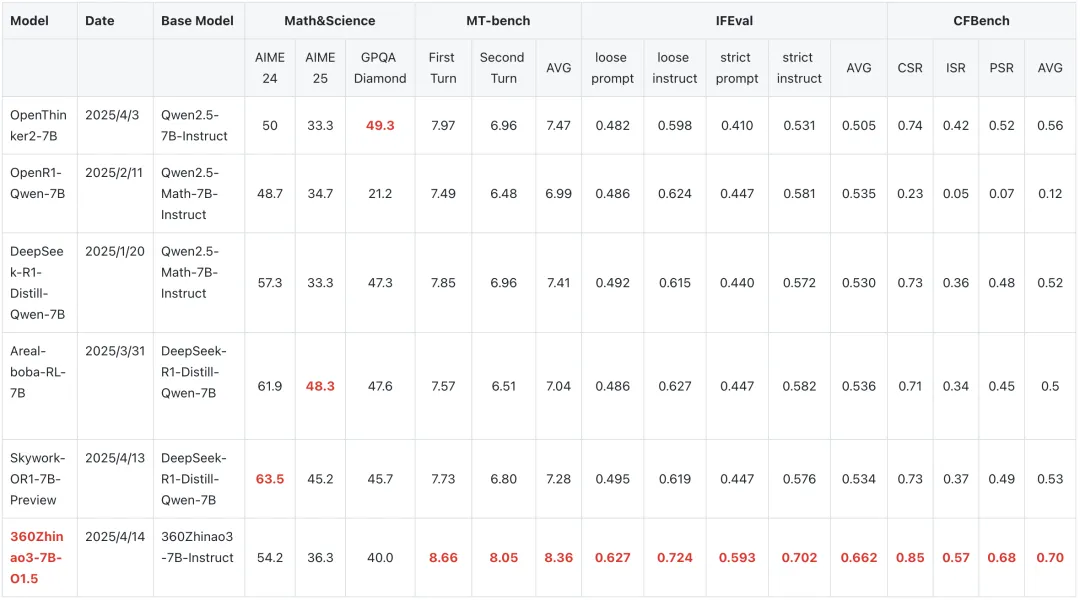

Ubuntu 25.10 计划默认使用内存安全的 sudo-rs 命令
Canonical 计划在 Ubuntu 25.10 中使用更多 Rust 编写的系统组件,目前为止,大部分讨论都集中在过渡到 Rust Coreutils“uutils” 来取代 GNU Coreutils。 现在,Canonical 宣布了新的计划——默认使用 sudo-rs 来替代 sudo。 sudo-rs 项目已经开发了好几年,是一个基于 Rust 的内存安全 sudo 实现,可以作为 sudo 的直接替代品。 sudo-rs 项目由非营利组织 Trifecta Tech Foundation 维护,他们确认了 Canonical 计划在 Ubuntu 25.10 中默认使用 sudo-rs。 他们在公告中写道: Canonical 计划将 sudo-rs 设为 Ubuntu 25.10 的默认命令。这将为最终用户提供时间进行验收测试,并确保 sudo-rs 在纳入下一个长期支持 (LTS) 版本:Ubuntu 26.04 LTS 之前经过实战检验,该版本将获得至少 12 年的支持。我们期待从社区学习如何进一步改进 sudo-rs。 反过来,sudo-rs 开发人员将致力于添...