本文由体验技术团队Kagol原创。
TinyPro 是一个基于 TinyVue 打造的前后端分离的后台管理系统,支持在线配置菜单、路由、国际化,支持页签模式、多级菜单,支持丰富的模板类型,支持多种构建工具,功能强大、开箱即用。
我们非常高兴地宣布,2025年4月10日,TinyPro 发布了 v1.2.0 🎉。
本次 1.2.0 版本主要有以下重大变更:
- 列表页面增加综合搜索,只需要一个输入框,解决所有数据筛选问题
- 增加更丰富的单元测试,目前后端服务的单测覆盖率 85% 左右
- 升级 Vite(
^6.1.0) / Vue(^3.5.10) / TinyVue(^3.21.0) 等依赖到最新版本,并优化部分样式问题
- 移除 Mock,将 Mock 数据迁移到后端(因为有后端,所以不需要 Mock 服务了)
详细的 Release Notes 请参考:https://github.com/opentiny/tiny-pro/releases/tag/v1.2.0
本次版本共有3位贡献者参与开发,其中 discreted66 是新朋友👏
- discreted66 - 新增贡献者✨
- GaoNeng-wWw
- kagol
感谢新老朋友们对 TinyPro 的辛苦付出!
你可以更新 @opentiny/tiny-toolkit-pro@1.2.0 进行体验!
tiny install @opentiny/tiny-toolkit-pro@1.2.0
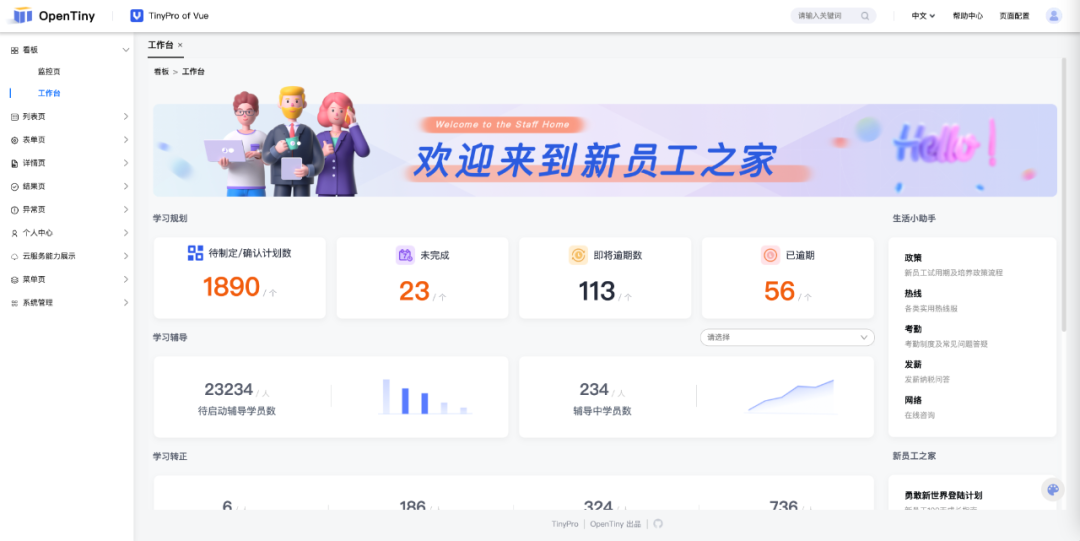
TinyPro 效果图: ![]()
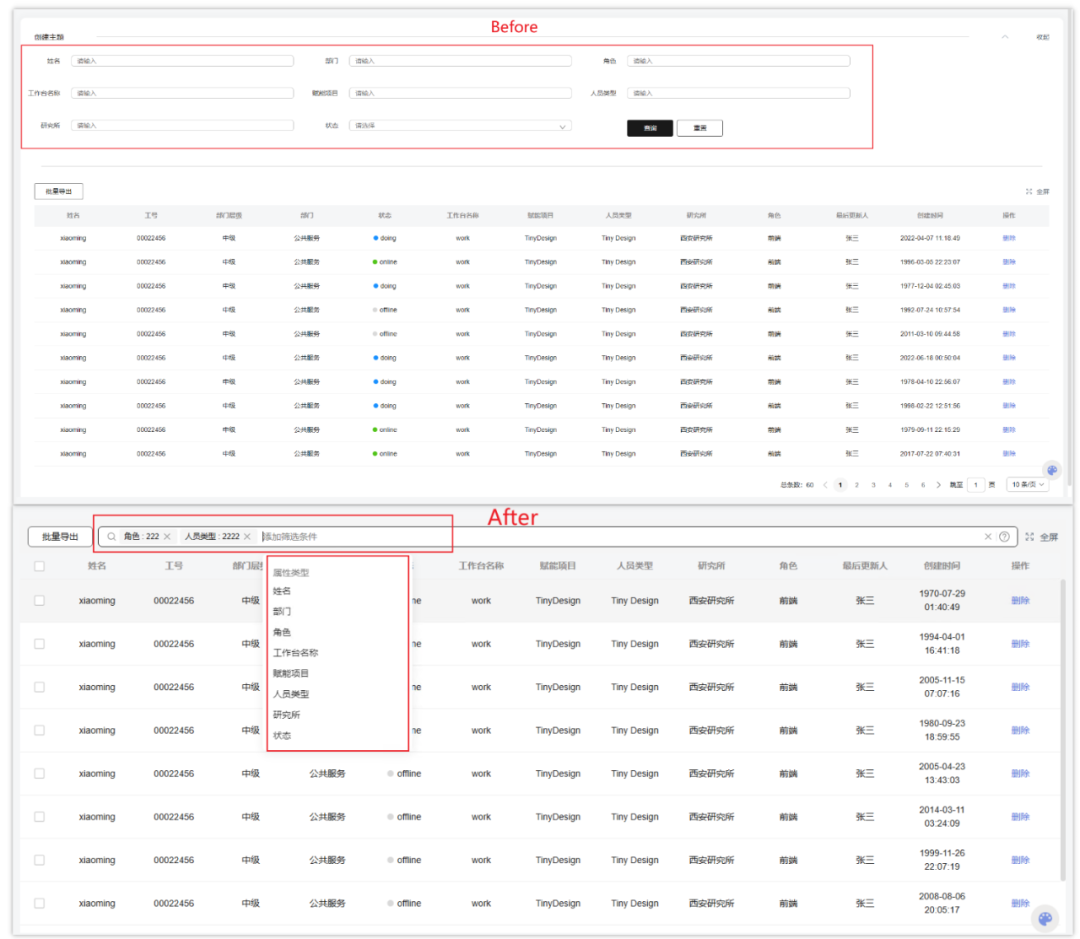
1 列表增加综合搜索
之前的列表搜索比较传统,每个筛选项是一个单独的组件,比如按姓名搜索是一个输入框,按角色搜索是一个下拉框,按日期搜索是一个日期选择框等。
这样会有一个问题:一旦过滤字段增多,会不断地占用主体内容的空间,直到屏幕显示的全是过滤条件,没有主体内容,虽然右上角增加了一个展开收起的功能,但也是治标不治本。
所以我们开发了一个 SearchBox 综合搜索组件,只需要一个输入框,就能把所有的过滤条件全部收拢在内,大大提升了用户体验!
以下是新旧过滤器的效果对比:
![]()
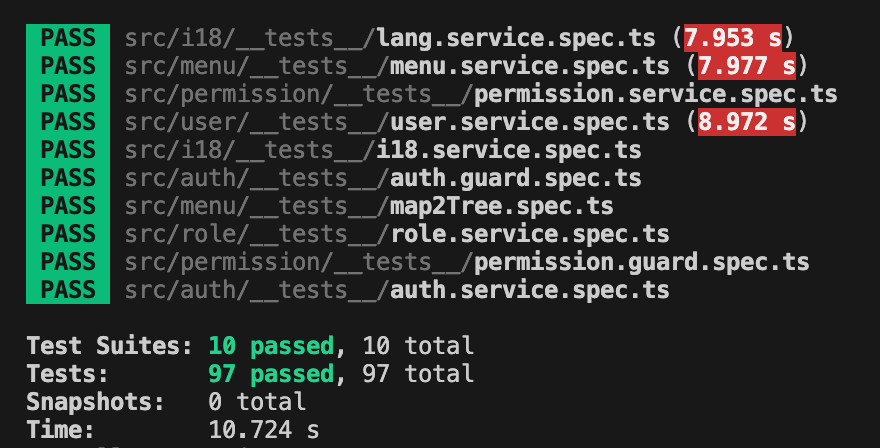
2 更丰富的单元测试
为了尽可能保障质量,给自己多一点安全感,我们给 NestJS 后端服务增加了大量单元测试,目前一共有97个单元测试(欢迎大家一起参与共建,我们的单元测试基于 Jest)。
执行以下命令即可执行单元测试:
cd template/nestJs
pnpm test
![]()
我们非常欢迎你一起参与 TinyPro 项目共建,通过参与 TinyPro 项目共建,你
- 不仅可以了解一个后台管理模板的前后端原理,学习 Vite、Vue、TypeScript、NestJS、Jest 等流行的技术
- 而且可以结识一批技术大牛,一起学习和交流前端技术
- 还有机会获得 OpenTiny 社区的定制礼品
另外由于 TinyPro 项目刚创建不久(之前是作为 TinyCLI 项目的一个目录,现在作为独立的仓库,可见官方也是非常重视这个项目的),还有很多值得完善的地方,大家也可以多多探索,欢迎提出你的优化想法,且在 TinyPro 项目中落地。
可以在 discussion 中参与讨论:
https://github.com/opentiny/tiny-pro/discussions
3 如何参与贡献
之前给大家介绍了 TinyPro 项目的初始化、本地启动和二次开发等内容。
TinyPro 后台管理系统从启动到使用,再到二次开发,看这一篇就够了!
接下来给大家介绍如何参与 TinyPro 项目的贡献。
3.1 Fork 和克隆代码
- 打开 TinyPro 项目,点击右上角的"Fork"按钮,将仓库复制到你的 GitHub 账户下
- 使用以下命令将 Fork 后的仓库克隆到本地:
git clone https://github.com/yourname/tiny-pro.git
3.2 安装依赖和本地启动
本地 TinyPro 目录如下:
- template
- nestJs # 后端服务
- tinyvue # 前端服务
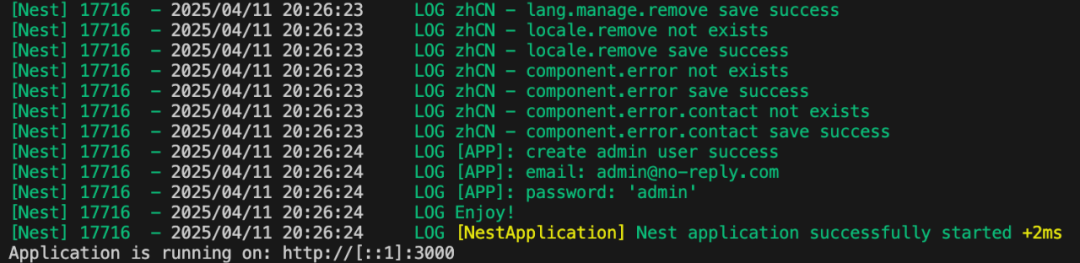
启动后端
cd template/nestJs
pnpm i
将 .env.example 改成 .env,然后执行以下命令即可:
pnpm start
出现以下界面,说明后端启动成功:
![]()
启动前端
启动前端和启动后端差不多。
cd template/tinyvue
pnpm i
pnpm start
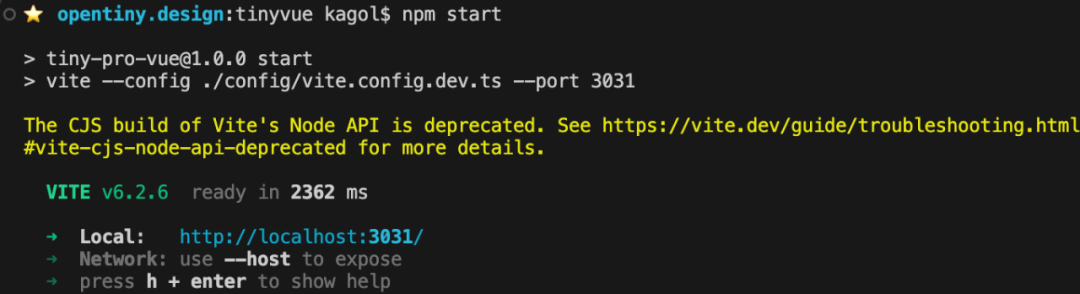
出现以下界面,说明前端启动成功:
![]()
访问链接:http://localhost:3031/ , 即可查看效果。
详细的前后端启动步骤可以参考之前的文章:TinyPro 后台管理系统从启动到使用,再到二次开发,看这一篇就够了!
或者看之前的演示视频(从 08:00 开始):TinyPro使用指南:手把手带你本地启动 TinyPro 前后端
3.3 创建分支和提交代码
- 为你的修改创建一个新分支,避免直接在主分支上操作:
git checkout -b 你的分支名称
- 在本地仓库中进行代码修改,确保遵循项目的代码风格和规范,避免格式化问题。
- 添加修改的文件到暂存区:
git add .
- 提交修改,编写清晰的提交信息:
git commit -m "你的提交信息"
- 将本地分支推送到你的 Fork 仓库:
git push origin 你的分支名称
3.4 创建 Pull Request(PR)
- 在 GitHub 上,进入你的 Fork 仓库页面,点击"Compare & pull request"按钮,选择目标仓库的主分支 dev。
- 填写 PR 的标题和描述,说明你的修改内容和目的。
- 提交 PR,等待维护者审核。
- 如果维护者提了检视意见,需要及时修复和回复,并重新 commit && push
3.5 提交 Issue 和讨论
- 如果你发现项目中的问题,可以在 GitHub 上创建 Issue,描述问题并提供复现步骤
- 如果你有解决方案,可以在 Issue 中提出建议,或直接通过 PR 修复问题
- 如果你有好的想法和点子,欢迎在 Discussion 中创建讨论
4 领取任务
你可以在 Issue 列表中找到自己感兴趣的任务,回复"领取任务":
https://github.com/opentiny/tiny-cli/issues
或者你在使用过程中,发现了问题,有了好点子,都可以参与贡献。
如果你对以下任务感兴趣,也欢迎进行认领:
- 建议默认支持原子化 CSS:UnoCSS
- 使用 umzug 管理数据库的 migration 和 seeds
- 增加参数化初始化
- 页面配置可是本地生效
- 从 TinyPro 优化建议 中选择部分任务
- 给前端和后端补充单元测试用例
欢迎添加小助手微信:opentiny-official(回复:TinyPro),一起交流!
关于OpenTiny
欢迎加入 OpenTiny 开源社区。添加微信小助手:opentiny-official 一起参与交流前端技术~
OpenTiny 官网:https://opentiny.design
OpenTiny 代码仓库:https://github.com/opentiny
TinyVue 源码:https://github.com/opentiny/tiny-vue
TinyEngine 源码: https://github.com/opentiny/tiny-engine
欢迎进入代码仓库 Star🌟TinyEngine、TinyVue、TinyNG、TinyCLI、TinyEditor~
如果你也想要共建,可以进入代码仓库,找到 good first issue标签,一起参与开源贡献~