前言
随着大模型的飞速发展,越来越多的 AI 创新颠覆了过往很多产品的使用体验。但你是否曾想过,在向大型语言模型提问时,它能否根据你的需求精准返回系统中的对应数据?例如,当用户查询 Grafana 服务时,模型是否可以返回系统的 Dashboard 列表以及大盘实时图片。又或者,当用户询问某天的天气时,模型能否直接提供一张清晰的天气卡片。
今天,我们将以 AI 世界的"USB-C"标准接口------MCP(Model Context Protocol)为例,演示如何通过 MCP Server 实现大模型与阿里云 Grafana 服务的无缝对接,让智能交互更加高效、直观。
什么是 MCP?
咨询通义千问,你会了解到 MCP(Model Context Protocol)是一种开放标准的协议,旨在解决大型语言模型(LLM)数据源接入混乱的问题。它允许开发者构建服务器,以安全、标准化的方式向 LLM 应用程序公开数据和功能。以下是 MCP 的主要特点:
- 标准化 MCP 通过定义统一的通信协议,简化了不同 AI 和服务之间的集成过程。开发者无需为每个特定服务编写定制代码,只需遵循MCP标准,即可快速接入多种AI模型和服务。
- 安全性 安全性是 MCP 设计的核心考量之一。MCP 确保数据传输的安全性,保护用户隐私和数据安全,提供多层次的安全机制,包括数据加密、身份验证和权限控制等。
- 灵活性 MCP 具有高度的灵活性,能够适应各种应用场景和需求。无论是数据库、文件还是 API,MCP 都能提供支持,使得开发者可以根据具体需求选择最适合的技术栈。
- 跨平台 MCP 具备卓越的跨平台能力,适用于任何系统和编程语言(如Python、TypeScript、Go)。这使得 MCP 不局限于特定环境,而是能够在广泛的平台上实现一致的服务体验。
通过这些特性,MCP 成为了连接不同服务与应用的强大桥梁,极大地提升了开发效率和用户体验。
MCP 怎么工作?
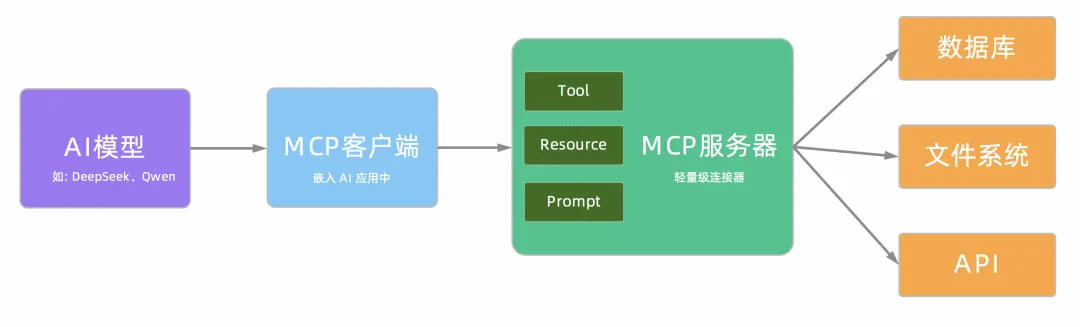
MCP 采用客户端-服务器模式,其核心组件如下:
- MCP 客户端:嵌入在 AI 应用中(如Claude Desktop、Cherry Studio、Cursor),负责与服务器通信,向服务器发送请求并告知需要执行的操作。
- MCP 服务器:一个轻量级服务,负责连接具体的数据源或工具(如数据库、文件系统、API、Git 仓库等),完成实际的任务处理。
![]()
如上图所示,当你在 AI 应用(如 Cherry Studio)的聊天窗口中询问"今天天气怎么样?"时,应用会首先将你的问题传递给选定的 AI 模型(如 DeepSeek 或 Qwen)。如果该大模型支持 MCP 协议,则会基于配置文件信息自动建立 MCP Client 连接,并调用 MCP Server 执行相应的天气查询操作(包括 Tool、Resource、Prompt)。随后,大模型根据返回的查询结果生成回答,并将其展示在聊天窗口中,完成整个交互过程。
如何开发 MCP Server?
MCP(Model Context Protocol)提供了三种主要能力:Tool、Resource 和 Prompt,每种能力都针对不同的应用场景和需求。
Tool(工具)
Tool 允许服务器公开可执行的函数,这些函数可由客户端调用,并供大型语言模型(LLM)使用以完成特定操作。通过 Tool,LLM 可以直接调用暴露的函数,从而实现对功能的主动控制。例如,查询数据库、发送消息、调用 API 或执行特定逻辑的任务。
Resource(资源)
Resource 表示服务器向客户端提供的各类只读数据,如文件、数据库记录、图片或日志等。这些资源由客户端或应用管理,用于为 LLM 提供上下文信息,帮助其更好地理解和响应用户需求。
Prompt(提示词)
Prompt 是由服务器定义的可重用指令或者模板,用户可以通过选择提示词来引导或标准化与 LLM 的交互过程,使其更精确和标准化输出。Prompt 的选择权通常掌握在用户手中,使其能够灵活定制对话体验。
除了上面 3 种能力,还有更高级的采样(Sampling),不过大部分客户端都没有支持。接下来,我们将以大部分客户端支持的 Tool 为例,正式开始开发一个可以连接 Grafana 的 MCP Server,展示如何利用 MCP 协议实现功能扩展与服务集成。
一、初始化项目
安装 UV 命令
curl -LsSf https://astral.sh/uv/install.sh | sh
初始化 MCP 项目
# 给项目创建一个文件夹
uv init grafana-mcp-example
cd grafana-mcp-example
# 安装依赖
uv add "mcp[cli]" requests
# 创建 server 文件
touch server.py
二、初始化 FastMCP Server
MCP Python SDK 现已推出全新的 FastMCP 类,该类充分利用 Python 的类型注解(如 @mcp.tool())和文档字符串特性,能够自动生成工具定义。这一功能显著简化了 MCP 中 Tool、Resource 和 Prompt 等功能组件的创建与管理流程,使开发者可以更加高效地构建和维护相关服务。
定义 MCP Server
创建一个名为 mcp 的 FastMCP 对象 ,并以 stdio 模式运行。
from mcp.server.fastmcp import FastMCP
MCP_SERVER_NAME = "grafana-mcp-server"
mcp = FastMCP(MCP_SERVER_NAME)
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')
添加 Tool
使用 @mcp.tool() 注解将这两个函数标记为 MCP 的 Tool。并通过注释说明函数的用途。
@mcp.tool()
def listFolder() -> list[any] | str:
"""列出所有 Grafana 文件夹名称"""
return grafana.GrafanaClient().listFolder()
@mcp.tool()
def listDashboard(folderName: str) -> list[any] | str:
"""列出文件夹下所有 Grafana 大盘名称"""
return grafana.GrafanaClient().listDashboard(folderName)
实现 Grafana Client
这里我们简单的实现查询 Grafana 的文件夹列表和文件夹下 Dashboard 列表的 Client,更多丰富功能可以自己进行实现。
import os
import requests
class GrafanaClient:
'Grafana URL地址'
grafanaURL="localhost:3000"
'Grafana API Key'
grafanaApiKey=""
def __init__(self):
self.grafanaURL = os.getenv("GRAFANA_URL")
self.grafanaApiKey = os.getenv("GRAFANA_API_KEY")
def grafanaHeader(self):
#Grafana 请求Header
headers = {
"Authorization": "Bearer "+self.grafanaApiKey,
"Content-Type": "application/json"
}
return headers
def listFolder(self) -> list[any]:
#列出所有 Grafana 文件夹名称
response = requests.get(self.grafanaURL+"/api/search?type=dash-folder", headers=self.grafanaHeader())
resContent=[]
if response.status_code == 200:
for item in response.json():
resContent.append({"uid":item["uid"],"name":item["title"]})
return resContent
def listDashboard(self,folderName: str) -> list[any]:
#列出文件夹下所有 Grafana 大盘名称
resContent=[]
#查询文件夹UID
response = requests.get(self.grafanaURL+"/api/search?type=dash-folder&query="+folderName, headers=self.grafanaHeader())
folderUid=""
if response.status_code == 200:
for item in response.json():
folderUid=item["uid"]
else:
return resContent
#查询文件夹下大盘列表
response = requests.get(self.grafanaURL+"/api/search?type=dash-db&folderUIDs="+folderUid, headers=self.grafanaHeader())
if response.status_code == 200:
for item in response.json():
resContent.append({"uid":item["uid"],"name":item["title"]})
return resContent
如何集成 MCP Server?
在完成上述 MCP Server 的编码工作后,我们即可开始将其集成到 AI 应用中。
环境准备
接下来,我们将演示如何在 Cherry Studio 中配置 MCP 服务器,让百炼大模型对接自建的 Grafana 应用。演示环境如下:
- 系统: Apple M1 macOS 15.1 (24B83)
- 工具: Cherry Studio 1.1.2【1】、 VS Code 1.98.2
- 大模型: 阿里云百炼 qwen-plus 2.5(需要支持 MCP 协议模型)
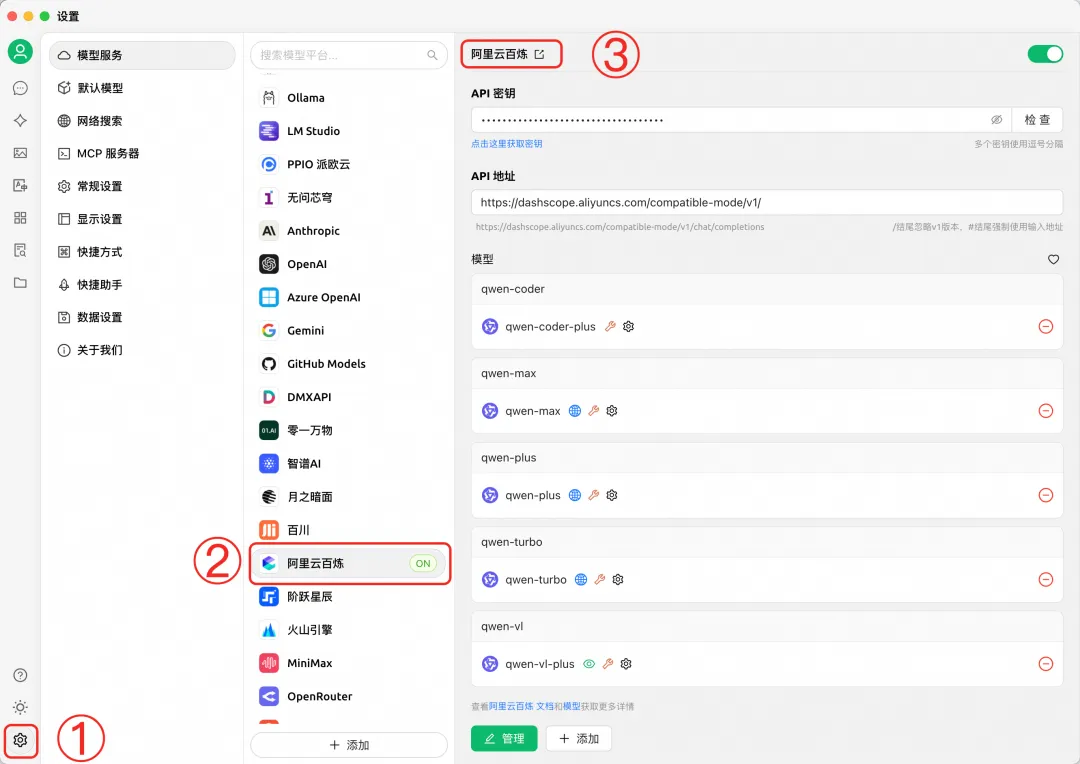
在 Cherry Studio 中添加阿里云百炼大模型 qwen-plus
![]()
Grafana API Key 准备
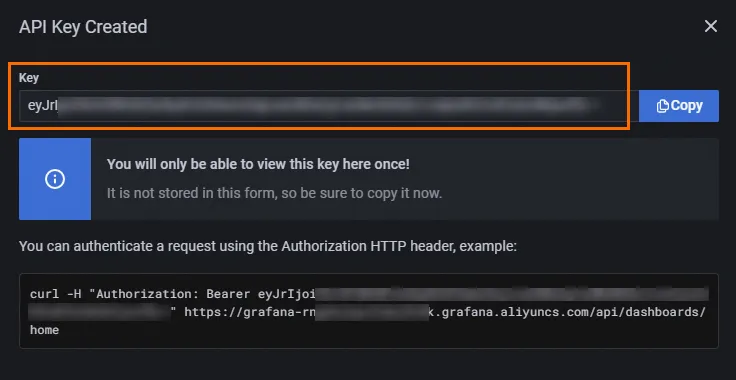
接下来,您需要准备 Grafana 的 API Key 或 Service Account Token。如果您还没有 Grafana 服务,可以免费试用阿里云 Grafana 服务【1】。具体创建步骤请参考文档【2】的第二部分。在此过程中,请注意区分 Grafana 的版本:
Grafana 9.0.x 及以前版本:创建 API Key。
![]()
![]()
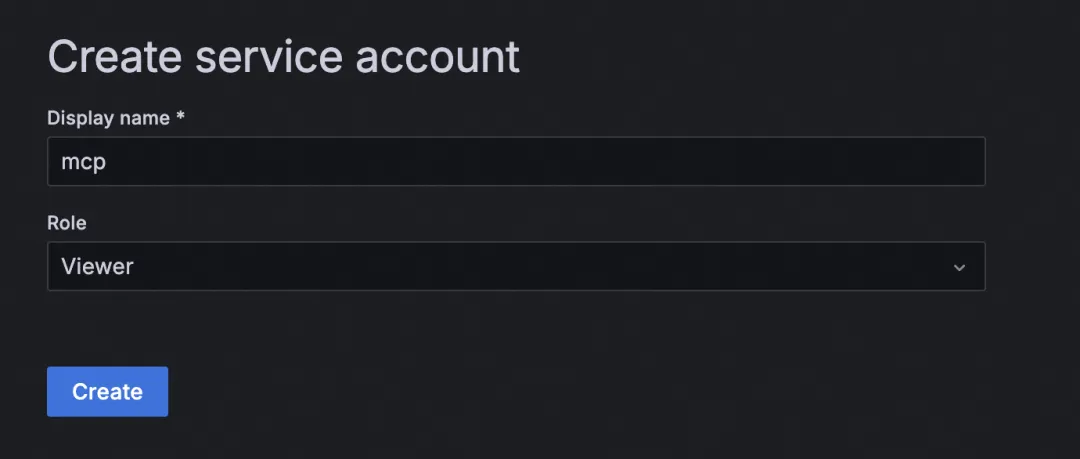
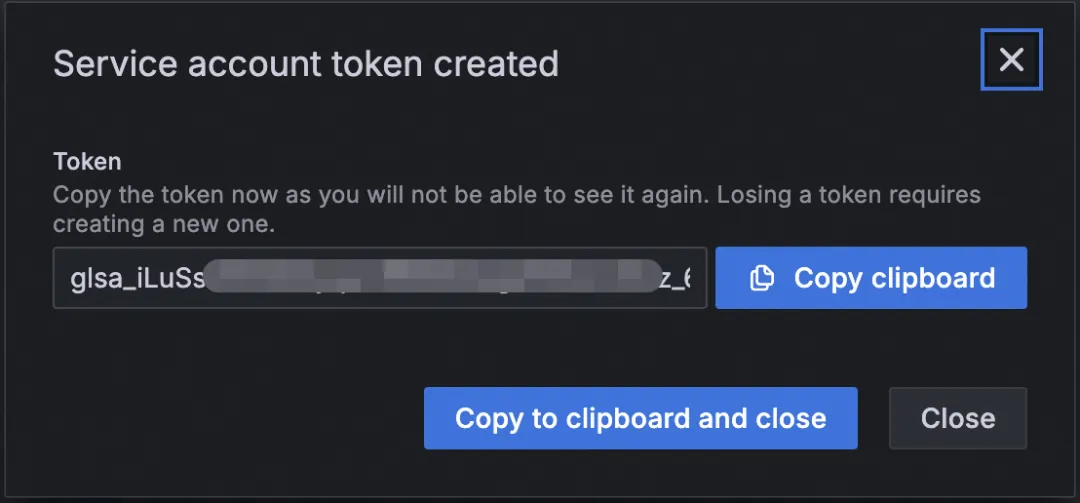
- Grafana 10.0.x 及以后版本:创建 Service Account Token。
![]()
![]()
确保根据您的 Grafana 版本选择正确的创建方法。
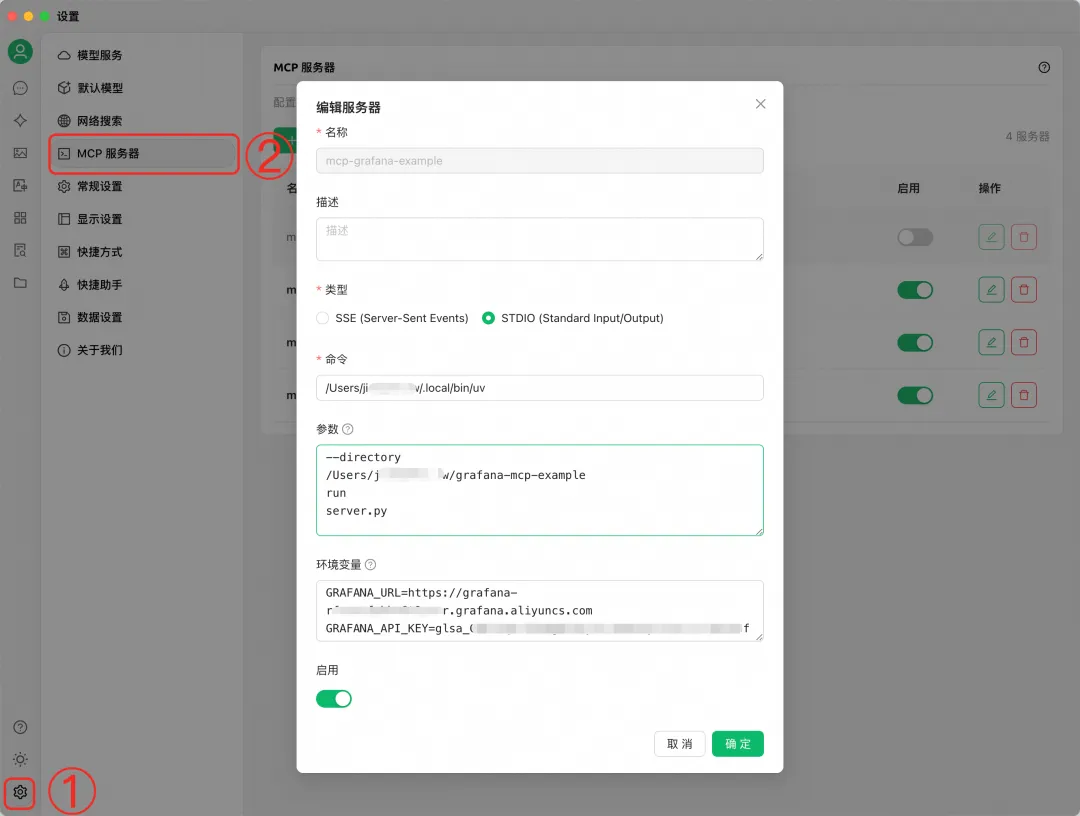
配置MCP服务
在 Cherry Studio 中添加 MCP 服务器,配置上面步骤中开发的 MCP Server。
![]()
MCP 服务器参数说明:
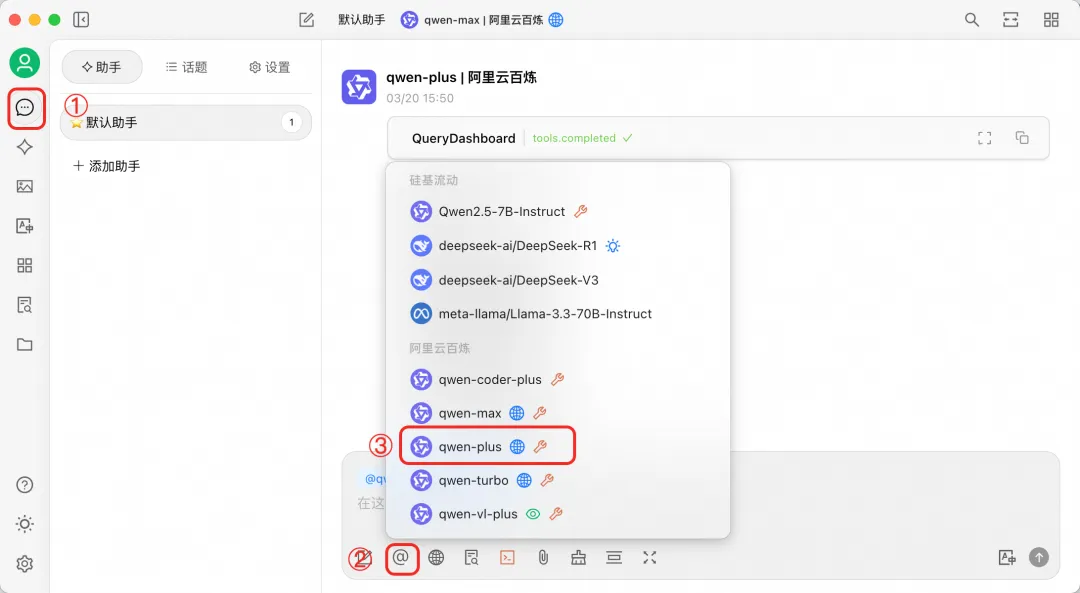
大模型验证
首先,在助手菜单中依次选择大模型为"qwen-plus",并将 MCP 服务器设置为刚刚创建的"mcp-grafana"。
![]()
![]()
至此,MCP 服务的搭建与配置已全部完成,接下来即可通过大模型查询您的应用数据。
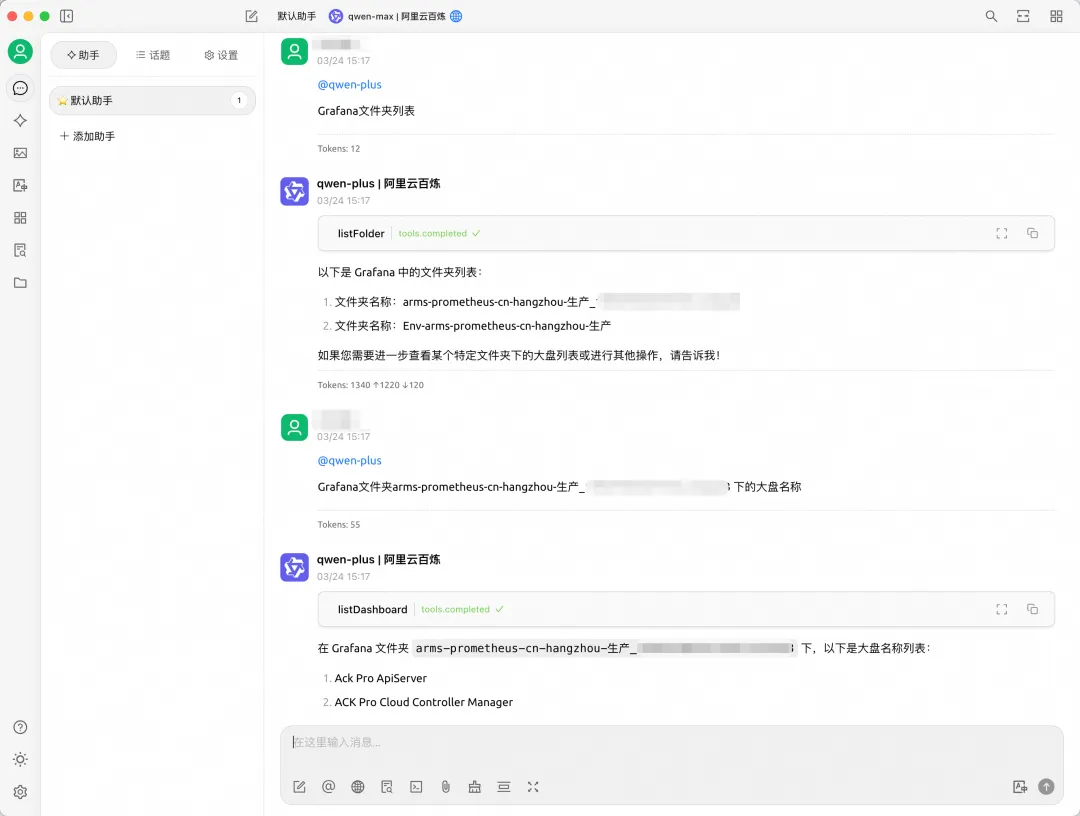
当您提问"Grafana 文件夹列表"或"某个文件夹下的大盘列表"时,系统将返回 Grafana 中对应的文件夹与大盘信息。经过对比可以确认,返回的结果与 Grafana 中的实际数据完全一致。
![]()
![]()
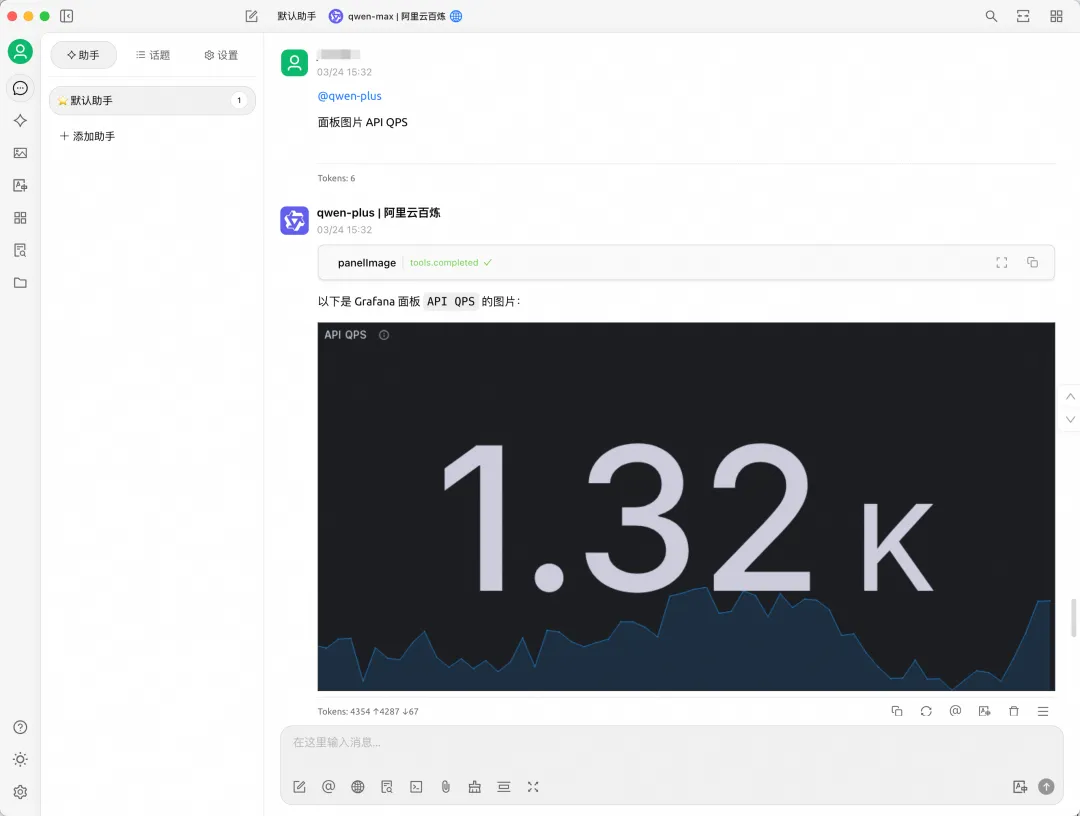
至此,我们已完成了一个简单的 MCP Server 开发体验。您可以基于开源社区提供的 mcp-grafana 进行扩展,也可以根据需求自定义更多功能,例如返回某个大盘面板的曲线图等,进一步丰富应用场景。
![]()
结语
本开发实战通过构建一个 Grafana MCP Server 实例,展示了如何利用 MCP 协议增强大型语言模型(LLM)的能力,充分体现了 MCP 在提升 LLM 应用开发效率方面的显著优势。MCP 不仅适用于对接 Grafana,其应用场景广泛,涵盖各行各业。例如,用户可以像点外卖一样简单地使用 AI 完成购物、应用管理、旅行规划等任务。服务商仅需开放标准 MCP 接口,即可实现服务与 AI 的无缝集成,极大简化了用户的操作流程。作为"AI 界的超级连接器",MCP 降低了技术门槛,使得每个人都能轻松享受智能生活带来的便利,使 AI 真正成为"生活管家"。无论是准备会议 PPT 还是解决学习中的难题,AI 都能提供个性化的帮助,实现了科技为人服务的理想。MCP 让复杂的任务变得简单高效,推动了智能化生活的普及与应用,真正做到了让科技服务于每一个人。
【1】Cherry Studio 1.1.2
https://cherry-ai.com/download
【2】阿里云Grafana服务
https://www.aliyun.com/product/aliware/grafana
【3】Grafana基于API Key分享大盘
https://help.aliyun.com/zh/grafana/use-cases/use-api-key-to-share-grafana-dashboards