![图片]()
本文首发于 NebulaGraph 技术社区:https://mp.weixin.qq.com/s/m4oJgHtrlNDXeQBDk8Y_Zw
▌一、背景
故事发生在去年一次和业务部门的沟通中。业务部门同事希望我给出一个直观的解决办法,把客户经理、客户、客户经理助理、团队长的关系,用更加直观的方式展示,最好还能带一些基本信息进去,方便他们在日常工作中去追溯一些事情,也能直观体现每个岗位的实际工作成果。
于是我写了一个视图,把团队长、客户经理、客户经理助理、客户的关联关系扔到一个大视图里。结果毫不意外地被业务部门否决了。他们反馈的是,一行行表格根本没法直观体现,最后还是要落到 excel 然后合并单元格挨个对,并没有改变工作模式。
临了,还被一个同事说,你这不是关系型数据库吗,怎么没法显示“关系”?
▌二、背景关系数据库和“关系”
我们平时所说的关系型数据库,实际上是基于关系模型和关系代数等理论的基础上,将现实中的各种实体以表、属性、行等诸多方式关联到一起。这和我们日常口头上的“关系”却又有着不同的指向。
而这个场景下,业务部门需要的是直观看到多个个体之间在现实中是如何关联起来的,他们为什么会被关联,以及每个个体背后有着什么样的相关信息。这个事情关系型数据库可以解决,但是却面对一个事情,这和我们日常生活的直觉是很不一样的,甚至有时候是反直觉的,例如:
张三是个客户经理,那么在关系型数据库中,他和客户经理的关联是
| 客户经理ID |
客户经理姓名 |
客户ID |
客户姓名 |
| 101 |
张三 |
1001 |
哪吒 |
| 101 |
张三 |
1002 |
敖丙 |
而客户经理想要看的是
———> 哪吒
张三—|
———> 敖丙
然后点到张三的时候,才显示他的 ID 是101,同时这个箭头的指向,能够看出服务的源头和目标
这时候,关系型数据库想要表达同样也能,但是就没有办法肉眼直接看,就需要另一个工具来实现——图数据库。
图数据库是基于图论的数据模型。它使用节点(vertex 或 node)、边(edge 或 arc)和属性(property)来表示和存储数据。节点代表实体,如人、组织、地点等。边用于表示节点之间的关系,例如 “朋友关系”“雇佣关系”“位于关系” 等。属性则可以为节点和边添加更多的细节信息,比如节点 “人” 可以有姓名、年龄等属性,边 “朋友关系” 可以有相识日期等属性。
有关图数据库的定义,也是基于图论而进一步产生。
而常见的图数据库,就是国外的开源产品 Neo4j。如果找一个国内类似产品,那我来推荐 NebulaGraph,接下来我们来用它去实现业务部门这个需求。
▌三、让业务部门自己搭建“关系”
有关Nebulagraph的安装部署,大家可以去看官网文档:
https://docs.nebula-graph.com.cn/3.8.0/
如果让技术部门来完成从部署到建立起整个关系图,其实并不难,但是我们今天要做的事情是,让业务部门自己来动手,作为IT部门,只需要提供数据即可。
我们需要用到的软件或者工具有:
第一步,创建 schema
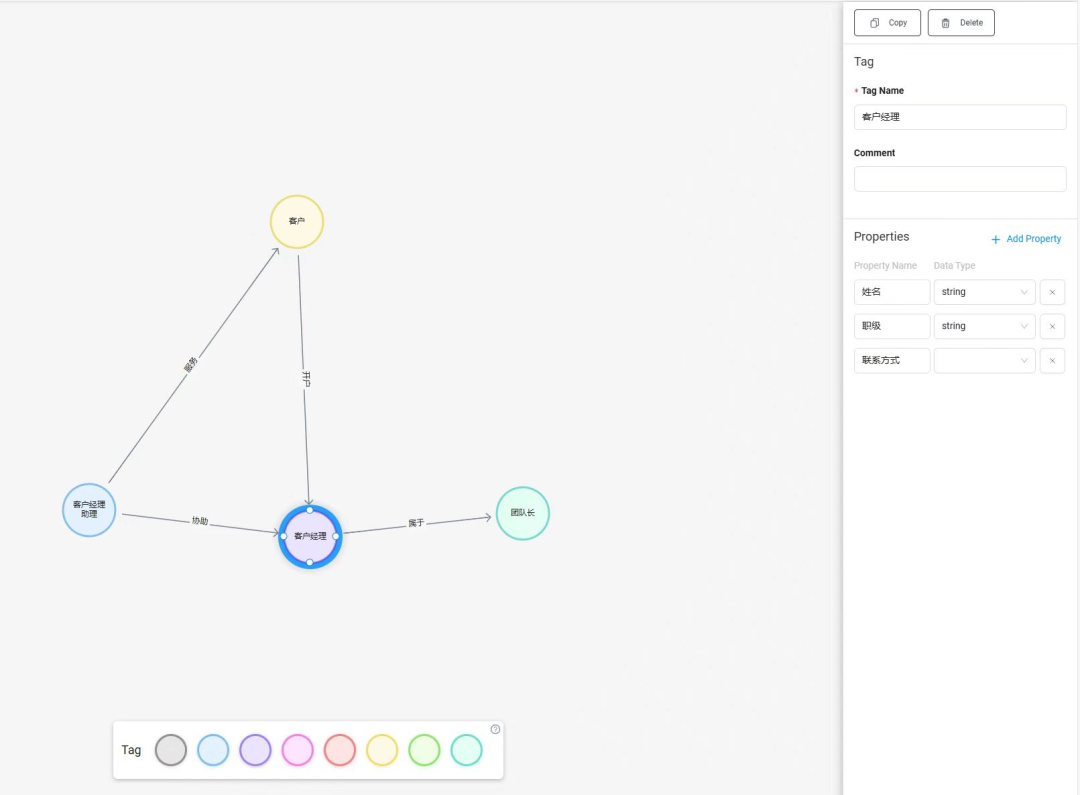
进入 NebulaGraph Studio 的 Schema Drafting 功能,创建 space。这是我认为 Studio 做的最好的一个功能。让用户通过手动拖拉拽就可以建立起基本的节点和边。而且每个节点和边的属性都可以定义。
我们创建四个角色客户、客户经理、客户经理助理、团队长。每个节点可以自己定义属性和类型。创建完之后保存,并用它来生成一个 space,命名为客户服务。(这里客户经理助理和客户的边我在后面删掉了,忘记截图)创建 space 的时候,需要输入 VID 的类型,可以从 int64 或者 string 二选一,我选择了 string,因为业务部门要求的是每个节点能够直接看到姓名,那么就需要以姓名作为 VID,当然,有可能出现重名引发新的问题。
![图片]()
第二步,数据准备
使用 DBeaver,导出团队长、客户经理、客户经理助理、客户端基本信息,生成 CSV 文件。我的样例数据如下,关羽张飞属于刘备团队,孙乾协助他们两个,董卓是关羽开的户,曹操是张飞开的户。
前三张表是从员工信息里按照角色导出,分别代表三个不同的岗位。后两张表是客户经理关联关系和客户信息两张表导出的数据。
5050009.csv
| 姓名 |
职级 |
联系方式 |
| 关羽 |
ED |
12345678 |
| 张飞 |
ED |
23456789 |
5050010.csv
| 姓名 |
职级 |
联系方式 |
| 孙乾 |
VP |
34567890 |
5050001.csv
| 姓名 |
职级 |
联系方式 |
| 刘备 |
MD |
01234567 |
team.csv
| 客户经理姓名 |
团队长姓名 |
客户经理助理姓名 |
联系方式 |
| 关羽 |
刘备 |
孙乾 |
12345678 |
| 张飞 |
刘备 |
孙乾 |
23456789 |
customer.csv
| 客户姓名 |
证件到期时间 |
联系方式 |
客户经理 |
| 曹操 |
2025-01-01 |
00000000 |
张飞 |
| 董卓 |
2025-01-01 |
11111111 |
关羽 |
第三步,导入数据
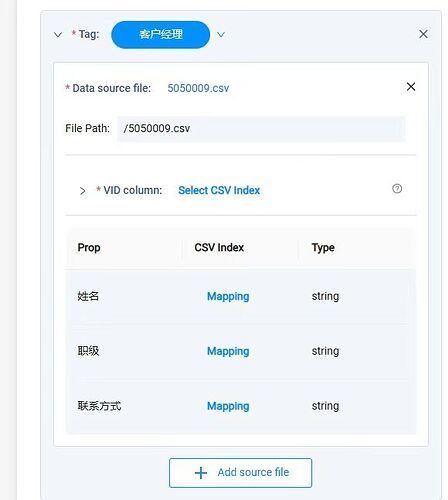
Stutio 的 import 功能里,首先把这些 csv 都上传,上传方式本地上传。
然后再导入,导入时,员工的三个文件和客户信息表,都要作为节点(tag)来导入,tag 要手动选择类型。这里导入时需要手动选择两个东西,一个是 ID 对应的列,我们选择姓名,一个是列的 mapping 关系。
![图片]()
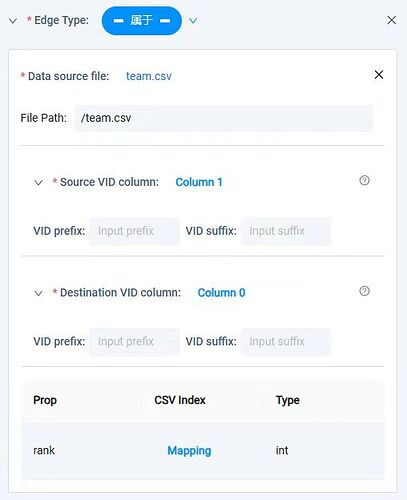
而边的导入,要依赖后两个 csv 文件,例如选择团队长的属于,上传 team.csv,source 选择客户经理姓名列,destination 团队长姓名列,rank 可不选,其他几个关系也就是 Edge type 都按照类似的方式,
![图片]()
第四步,验证数据
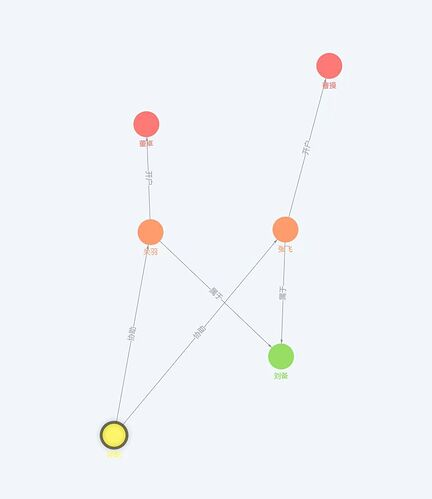
进入 console,在命令栏输入命令,显示我们刚刚导入的数据。
MATCH (n)-[r]-(m) RETURN n, m, r LIMIT 100;
可以看到的是,整个团队关系就可以在结果中的 graph 页看到了。而且支持拖拉拽调整布局。
![图片]()
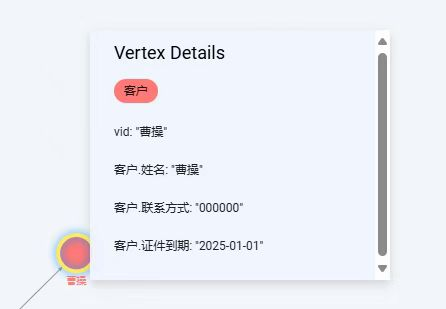
单击某个节点,还可以看到具体的信息,例如:
![图片]()
最后我来做个小结:
-
Nebulagraph 实际上在语法上和 Neo4j 有着相当不错的兼容性,再导入数据之前,我把之前在 neo4j 的 ddl 语句都跑了一遍,效果不错。
-
作为图数据库,有一个功能丰富且易用性好的工具十分重要,Nebulagraph Studio 从设计到导入数据到查询展示都能胜任,超过我预期。
-
如果将业务部门作为预期用户,是可行的,在我写的文字指导下,业务部门同事在自己电脑上就能实现从 csv 到图形展示的过程。关系型数据库各类使用确实是存在较高门槛,我们不能要求每个业务部门同事都了解 SQL 和表结构,但是从 csv 或者 excel 到图数据库,这个使用门槛是可以大大降低的。