![]()
「沉浸式翻译」是一个非常流行的双语对照网页翻译扩展工具,用户可以用它来即时翻译外文网页、PDF 文档、ePub 电子书、字幕等。它不仅可以实现原文加译文实时双语对照显示,还支持 Google、OpenAI、DeepL、微软、Gemini、Claude 等数十家翻译平台服务的自定义设置,在网络上好评如潮。
随着用户量持续增长,其运营和产品团队希望在尊重用户隐私的前提下,通过业务数据为业务增长研究提供决策依据。
业务挑战
业务数据埋点指标是数据仓库中不可或缺的重要数据源之一,同时也是企业最宝贵的资产之一。通常情况下,业务数据分析包含两大数据源:业务数据分析日志和上游关系型数据库(如 MySQL)。基于这些数据,企业可以进行用户增长分析、业务数据研究,甚至通过业务数据分析精准排查用户问题。
业务数据分析的特点决定了要构建一套可扩展、灵活且低成本的分析架构并非易事,具体表现在以下几个方面:
-
高流量和大容量:业务数据的产生量非常大,对存储和分析能力要求高;
-
兼顾多种分析需求:既需支持 BI 报表的静态展示,也需满足灵活的 Adhoc 查询;
-
多样化****数据格式:业务数据通常包含结构化数据与半结构化数据(如 JSON);
-
实时性要求:需要对业务数据快速响应,实现及时反馈。
由于这些复杂性,「沉浸式翻译」背后的团队早期选择了通用埋点系统(Google Analytics)作为业务数据分析工具。这种系统只需在网站中插入 JSON 代码,或在 APP 中嵌入 SDK,即可自动采集并上传埋点数据,生成访问量、停留时间、转化漏斗等指标。
![]()
然而,通用埋点系统虽然简单易用,但在实际使用中也存在着一些不足:
-
**数据明细的缺失。**通用埋点系统往往不会提供用户具体的访问明细日志,只能在 UI 中查询预设的报表;
-
**自定义查询能力不足。**通用埋点系统的查询模式并非标准 SQL 查询接口,当数据科学家希望构建复杂的 adhoc 查询时,由于缺少 SQL 能力,难以支持复杂的自定义查询;
-
**成本快速上升。**通用埋点系统一般采用阶梯计费模式,往往到了一个阶梯时,费用会翻倍。随着企业流量的持续增长,如果要查询更大范围的业务数据时,成本会迅速增加。
此外,沉浸式翻译团队遵循最小采集原则,不采集可能存在唯一识别能力的数据,不采集具体的用户行为细节,只采集必要的统计意义上的数据而非个性化数据,如翻译耗时,翻译次数和错误异常等。在这个限制下,大部分第三方的数据采集服务被放弃。考虑到沉浸式翻译有大量的海外用户,我们也需尊重海外用户的数据使用和数据存储权, 避免数据跨境传输。基于以上考虑,团队必须细粒度的控制采集行为和存储方式,自建业务数据体系成为唯一选项。
自建业务数据分析体系的复杂性
![]()
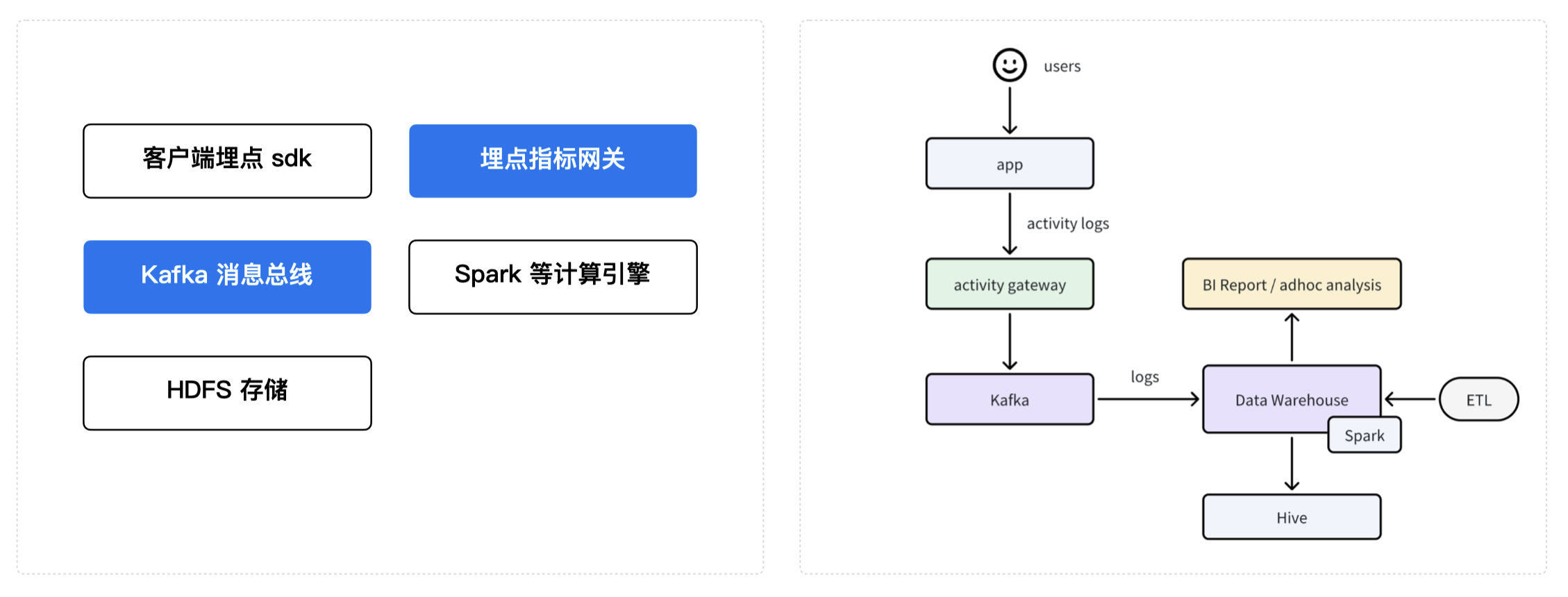
为了应对通用埋点系统的局限性,「沉浸式翻译」在业务增长到一定阶段后,决定自建一套业务数据分析体系。在进行调研后,技术人员发现传统自建架构多基于 Hadoop 大数据生态,典型实现流程如下:
-
在客户端(APP、网站)中埋入 SDK,采集业务数据日志 activity logs;
-
使用 Activity gateway 埋点指标网关,收集客户端发来的日志,并将日志转到 Kafka 消息总线;
-
利用 Kafka 将日志 logs 落到 Hive 或 Spark 等计算引擎;
-
通过 ETL 工具将数据导入数据仓库,生成业务数据分析报表。
![]()
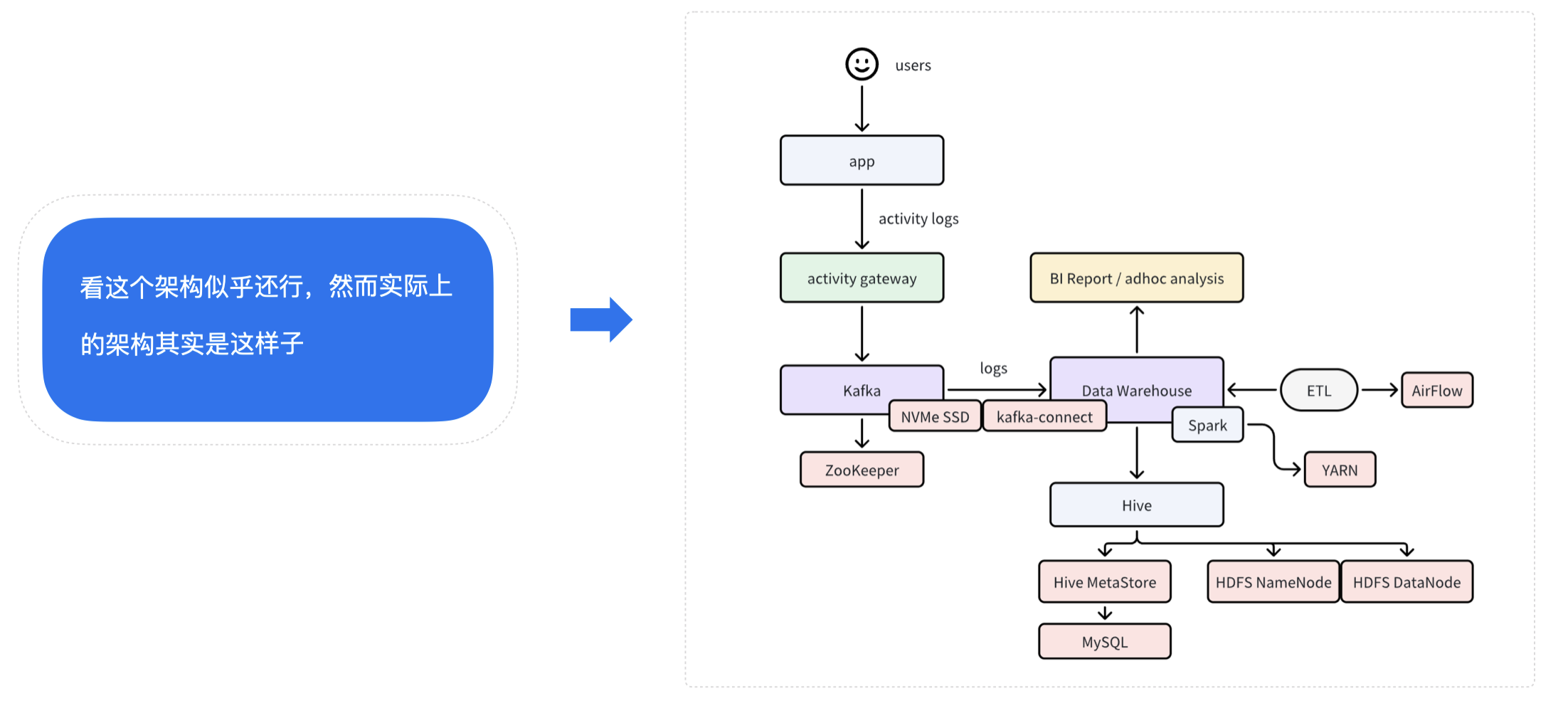
虽然这一架构在功能上能够满足需求,但其复杂性和维护成本极高:
-
Kafka 需要依赖 Zookeeper ,还需要配备 SSD 硬盘保障性能。
-
从 Kafka 到 Data Warehouse 需要 kafka-connect ;
-
Spark 要运行在 YARN 上,ETL 需要 Airflow 管理;
-
当 Hive 存储达到上限,可能还需要将 MySQL 换成 TiDB 等分布式数据库。
这种架构不仅需要大量的技术团队投入,还极大增加了运维负担。在如今企业都在不断追求降本增效的背景下,这种架构已不再适合需要简单、高效的业务场景。
为什么选择 Databend Cloud?
「沉浸式翻译」技术团队在做架构选型时选择了 Databend Cloud 进行业务数据分析体系的搭建。Databend Cloud 凭借简洁的架构和灵活性,提供了一种高效且低成本的业务数据分析解决方案:
-
100% 面向对象存储,完全存储计算分离,显著降低存储成本;
-
Rust 编写的 Query 引擎性能高,价格低廉。在计算资源闲置时自动休眠,不产生额外费用;
-
支持 100% ANSI SQL ,支持半结构化数据分析(JSON 和自定义 UDF)。当用户有一些比较复杂的 JSON,可以用内置的 JSON 分析能力或自定义的 UDF,分析半结构化数据;
-
内置 Task 调度驱动 ETL,完全无状态,自动弹性伸缩。
![]()
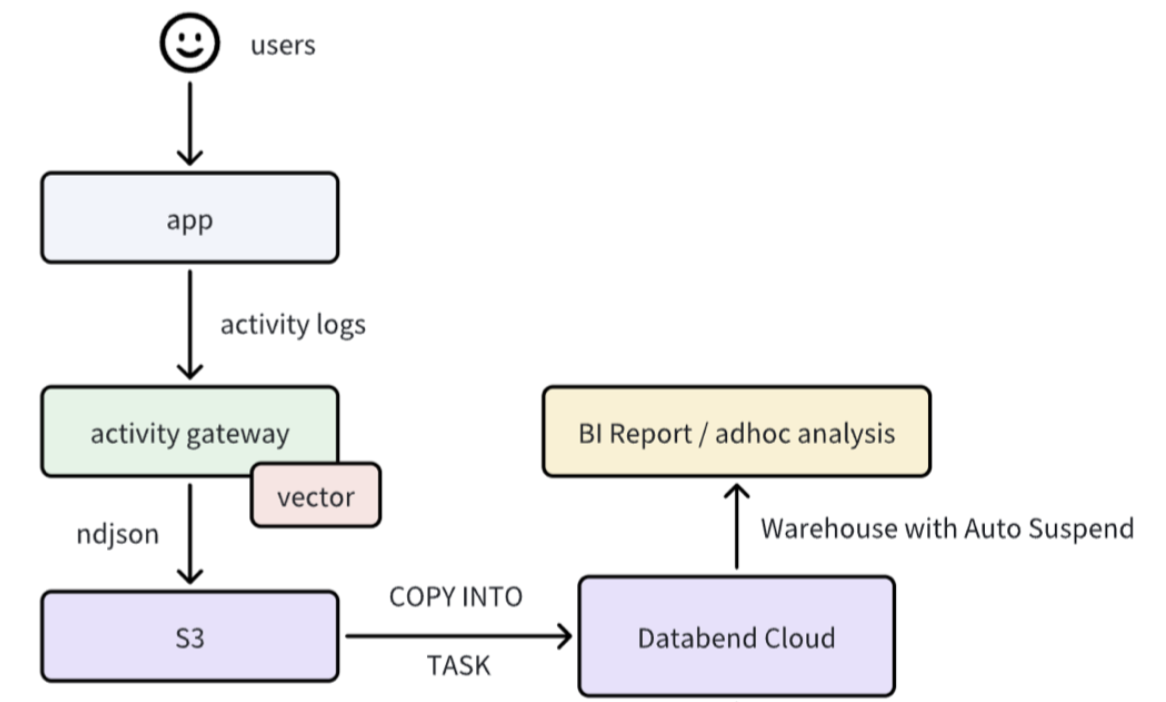
在使用 Databend Cloud 后,「沉浸式翻译」放弃了 Kafka,通过使用 Databend Cloud 建 stage ,将业务日志导入到 S3 中,再用 task 导进 Databend Cloud 中进行数据处理。
-
日志采集与存储:不再需要 Kafka,直接将埋点日志通过 vector 以 ndjson 格式落到 S3。
-
数据摄入与处理:在 Databend Cloud 中创建一个 copy task 任务,自动把日志拉出来,落到 S3。很多时候,S3 在 Databend Cloud 中可以当做一个 stage,落到 stage 里面的数据可以被 Databend Cloud 自动摄取,然后在 Databend Cloud 中进行处理,再从 S3 转出去。
-
查询与报表分析:通过自动休眠的 Warehouse 运行 BI 报表/即席查询,休眠时不产生任何费用。
Databend 作为一家工程师文化的国际公司,其在开源社区的贡献和口碑让沉浸式翻译的技术团队相信Databend对客户数据的尊重和保护。Databend 在海外和境内的服务是相对独立的。虽然沉浸式翻译目前没有对海外用户进行统计和分析,但未来如果有对海外数据分析的需求,架构也方便迁移和继承。
通过上述方式,Databend Cloud 能够以最简化的方式实现企业对高效业务数据分析的需求。
解决方案
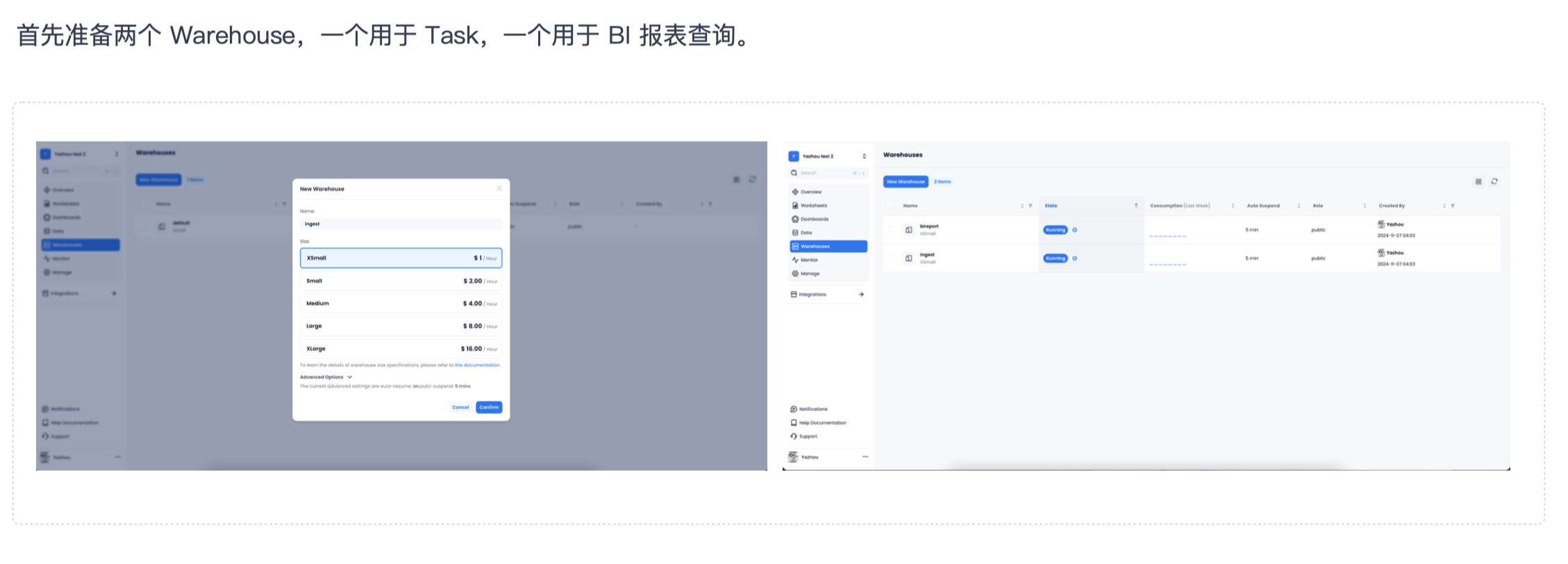
对于「沉浸式翻译」来说,构建这样一套业务数据分析架构所需要做的准备工作非常简单。首先,准备两个 Warehouse,一个用于 Task 摄入数据,一个用于 BI 报表查询。摄入数据的时候可以用一个规格小点的 Warehouse,查询的 Warehouse 规格高一点,因为查询通常不会一直查,这样可以节省更多成本。
![]()
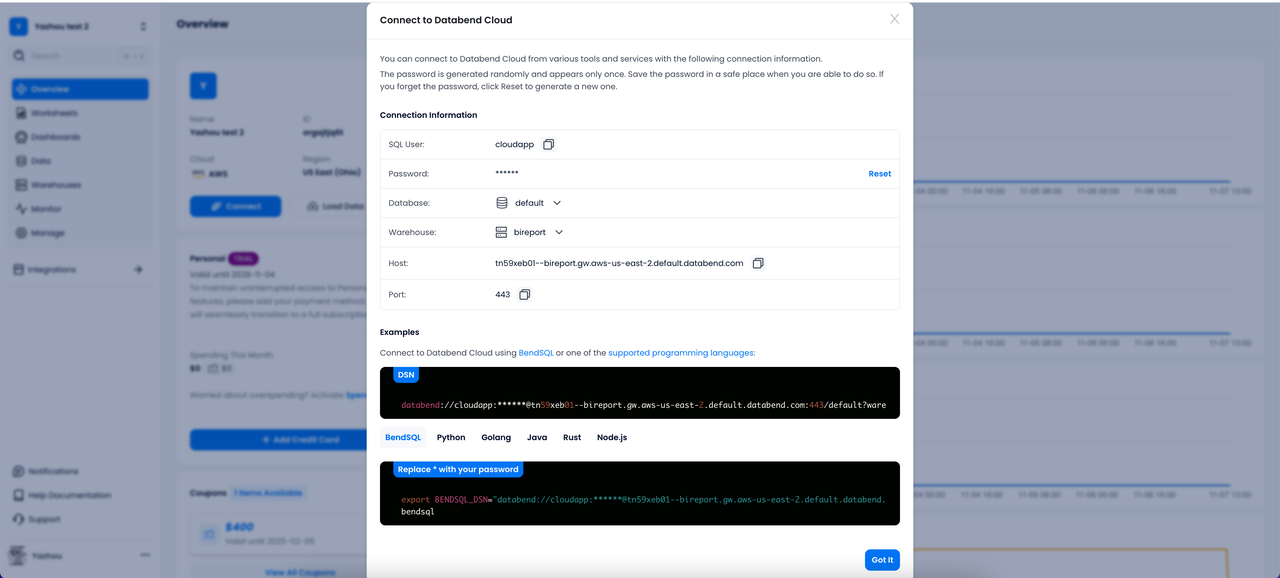
然后点击 connect 获得一个连接串,这个连接串可以放在 BI 报表用于查询。Databend 提供了各种语言的 Driver。
![]()
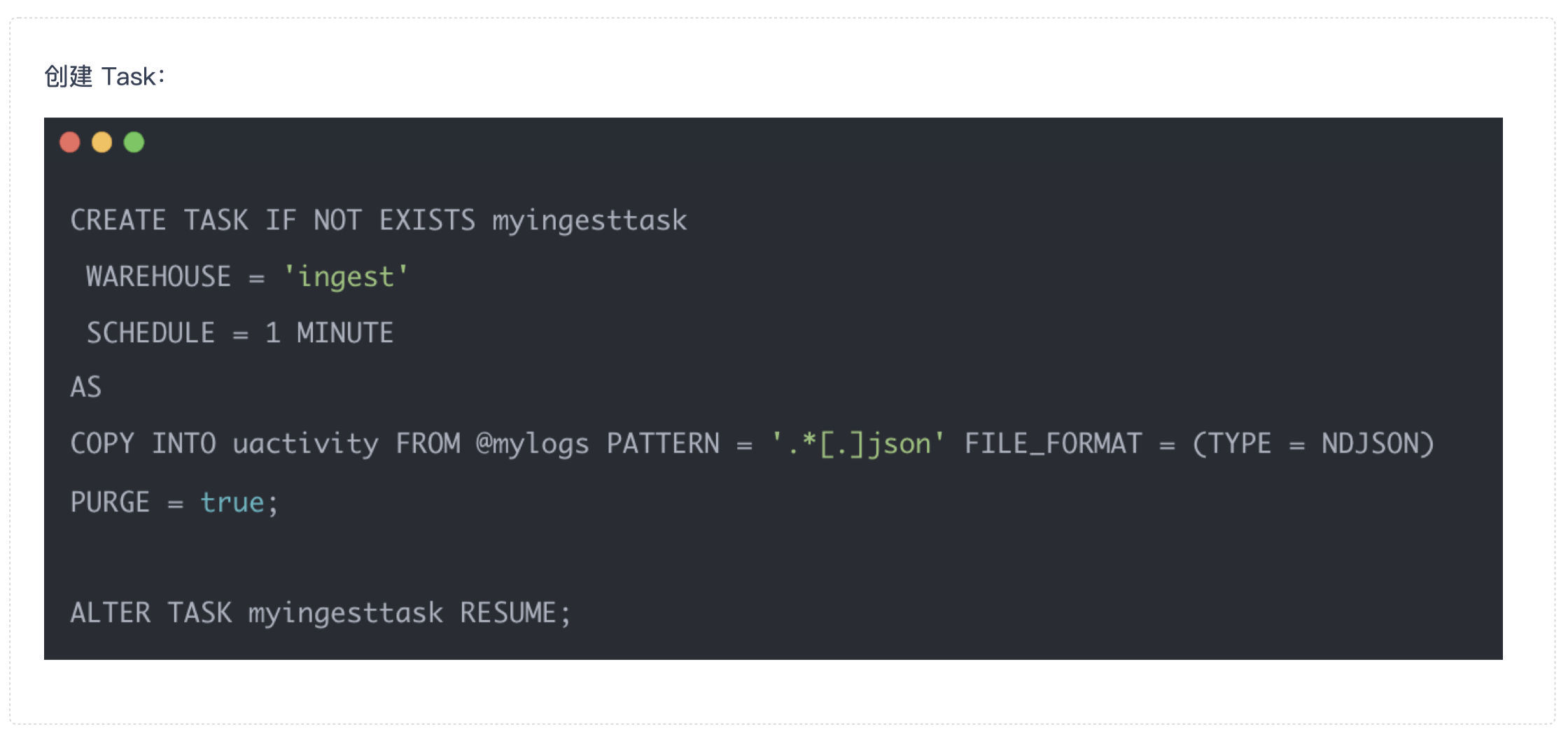
接下来的准备工作只需三步:
-
建表,其中的字段与 NDJSON 格式的日志一致;
-
创建一个 stage,将存放业务数据日志的 S3 目录录进来;
-
创建一个 task ,每一分钟或者十秒钟执行一次。它会自动把 stage 里的文件导进来,然后自动清理掉。
Vector 配置如下:
[sources.input_logs]type = "file"include = ["/path/to/your/logs/*.log"]read_from = "beginning"[transforms.parse_ndjson]type = "remap"inputs = ["input_logs"]source = '''. = parse_json!(string!(.message))'''[sinks.s3_output]type = "aws_s3"inputs = ["parse_ndjson"]bucket = "${YOUR_BUCKET_NAME}"region = "%{YOUR_BUCKET_REGION}"encoding.codec = "json"key_prefix = "logs/%Y/%m/%d"compression = "none"batch.max_bytes = 10485760 # 10MBbatch.timeout_secs = 300 # 5 minutesaws_access_key_id = "${AWS_ACCESS_KEY_ID}"aws_secret_access_key = "${AWS_SECRET_ACCESS_KEY}"
准备工作完成后,就可以源源不断地把业务数据日志录进 Databend Cloud 中进行分析。
![]()
![]()
架构对比与收益
![]()
通过对比通用埋点系统、传统 Hadoop 架构和 Databend Cloud,Databend Cloud 具有显著优势:
-
架构简洁性:摆脱了复杂的大数据生态,无需 Kafka、Airflow 等组件。
-
成本优化:利用对象存储和弹性计算实现低成本的存储与分析。
-
灵活性与性能:支持高性能 SQL 查询,满足多样化的业务场景。
此外,Databend Cloud 提供了快照机制,支持数据的时点回溯(Timetravel),可以帮助「沉浸式翻译」确保数据安全性和可恢复性。
最终,「沉浸式翻译」技术团队仅用一个下午便完成了全部 POC 测试,从复杂的 Hadoop 架构切换到 Databend Cloud,极大简化了运维和操作成本。
在构建业务数据埋点系统时,除了存储、计算方面的成本,维护成本也是架构选型的重要因子。Databend 通过对象存储与计算分离的架构革新,彻底改变了传统业务数据分析体系的复杂性。企业可以轻松搭建一套高性能、低成本的业务数据分析架构,实现从数据采集到分析的全流程优化。该方案为「沉浸式翻译」在降本增效的同时释放了数据的最大价值。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:https://databend.cn
📖 Databend 文档:https://docs.databend.com
💻 Wechat:Databend
✨ GitHub:https://github.com/databendlabs/databend