摘要:TaurusDB的字段压缩功能,不仅支持用户根据需求进行自选压缩算法等操作,实现细粒度的压缩策略调整,还能够自动识别并压缩符合条件的字段。
1. 技术背景
数据库压缩是一种数据管理技术,通过特定的压缩算法将数据库中的数据进行压缩,以减少存储空间占用,从而达到显著降低成本的效果。
社区MySQL InnoDB的压缩功能主要针对长期存储的冷数据,对于频繁访问的热数据,由于可能带来高达50%的性能影响,因此在生产环境中应用较少。现有的压缩机制,如表压缩和页面压缩,难以在不影响业务正常运行的情况下,提供针对特定字段的自定义压缩方式的灵活性。
自社区MySQL InnoDB 5.1版本起,开始支持表压缩功能,使用方式为CREATE TABLE ... ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8,这种方式要求数据必须压缩到固定大小,比如1K、2K、4K或8K,且一旦指定,不可修改。
到了社区MySQL InnoDB 5.7版本,进一步支持页面压缩,使用方式为CREATE TABLE ... COMPRESSION="zlib"。在Checkpoint刷页面时,对页面数据进行压缩,而读取到Buffer Pool时,则进行解压缩。压缩页会在Buffer Pool中,同时保留压缩和非压缩两个版本,占用Buffer Pool空间,这种压缩方式与块大小相关。例如,当文件系统块大小为4KB时,16KB页面中数据被压缩到9KB,它仍然会占用3个4KB文件系统块。
为满足客户追求更佳成本效益的需求,TaurusDB研发并推出了字段级压缩特性,旨在提供更为精细的压缩控制,以实现更高效的存储优化。
2.特性价值
TaurusDB推出细粒度的字段压缩功能,针对VARCHAR和LOB字段,提供了ZLIB和ZSTD两种压缩算法。在字段数据存储到Page时进行压缩,读取字段时进行解压缩,确保Page大小不变,REDO数据中保存压缩后的数据。用户可以根据实际需求,综合考虑压缩比和压缩/解压操作的性能影响,选择合适的压缩算法和等级,对不频繁访问的大字段进行压缩。
同时,TaurusDB字段压缩特性还提供了自动压缩的能力,对用户表中满足类型及长度阈值的列自动添加压缩属性,帮助用户更方便地使用此特性。
通过相关基准模型测试,开启字段压缩特性后,若业务不涉及压缩字段,则对性能无影响;若涉及压缩字段,则通常系统性能损失在10%以内。而进行压缩前后的数据大小比值可达1.8及以上,这意味着以较小的性能损耗为代价,显著降低了存储成本,实现了经济效益与系统效率的平衡。
3.实现原理
TaurusDB字段压缩特性,在存储层面上根据不同情况采用压缩或非压缩格式,实现了高效的数据压缩与解压缩。
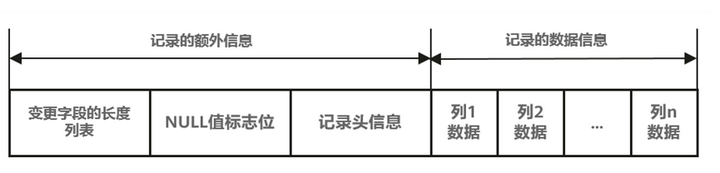
在存储引擎层Compact行格式数据,如图1所示,对于VARCHAR等这种变长的数据类型,系统不仅需要存储该字段的实际数据,还需要额外存储该数据的长度信息(即占用的字节数)。
图1 Compact行格式数据
TaurusDB实现的字段压缩特性,在各列数据中增添了代表压缩属性的内容。对于未使用字段压缩特性的列,其值保持原有格式;而对于已使用字段压缩特性的列,将上述所示的列数据值,改为如下所示两种格式。
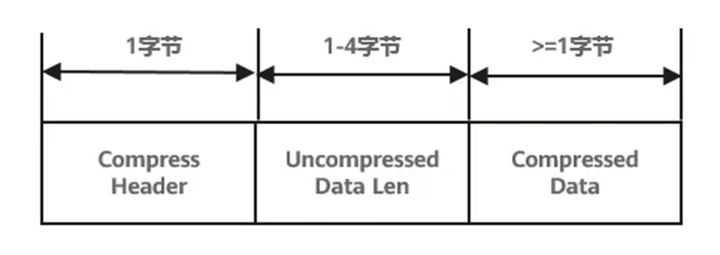
图2 字段压缩中的压缩格式
它包含Compress Header(压缩头)、Uncompressed Data Len(未压缩前的字段长度)和Compressed Data(压缩数据),作用如下:
Compress Header:保存是否已进行压缩、采用的压缩算法等元数据。
Uncompressed Data Len:保存数据在压缩前的原始长度,即占用的字节数。
Compressed Data:保存经过压缩处理后的实际数据内容。
图3 字段压缩中的非压缩格式
它包含Compress Header(压缩头)和Original Uncompressed Data(未压缩数据),其作用如下:
Compress Header:保存是否已进行压缩、采用的压缩算法等元数据。
Original Uncompressed Data:直接存储未压缩的数据,避免不必要的压缩处理。
在处理数据时,如果数据过短,即小于字段压缩阈值参数rds_column_compression_threshold,或调用压缩接口后发现并未明显带来存储空间的节省时,系统将采用该格式。
对于包含压缩字段的写入流程:在调用row_mysql_store_col_in_innobase_format函数,将SQL引擎层数据转为存储引擎层数据时,若通过元信息判断字段存在压缩属性,则调用压缩接口,将压缩后的数据写入Page中,以不改变页面大小而减少页面数量的方式,减少占用的存储空间。
对于包含压缩字段的读取流程:在调用row_sel_field_store_in_mysql_format_func函数,将存储引擎层数据转为SQL引擎层数据时,若通过元信息判断字段存在压缩属性,则调用解压缩接口。
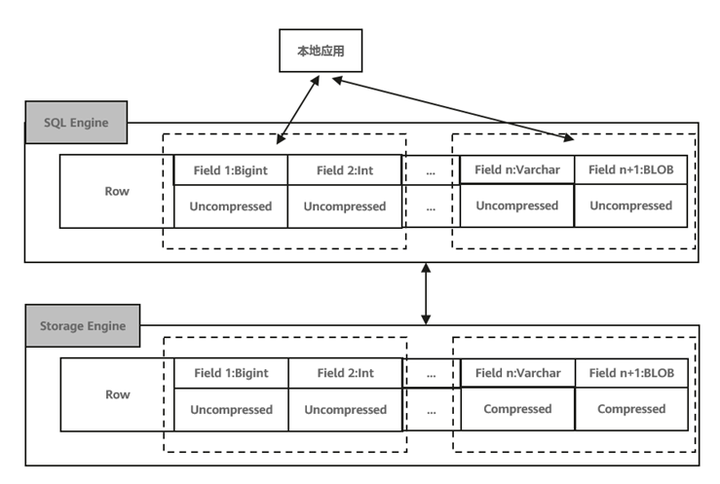
TaurusDB压缩/解压缩实现的效果如图4所示,对于SQL Engine层而言,看到的内容均为未压缩的数据,而压缩/解压缩的动作实际发生在Storage Engine层,且只针对具有压缩属性的列单独进行压缩。
图4 TaurusDB压缩/解压缩示意
4 业务场景/流程
4.1 特性参数
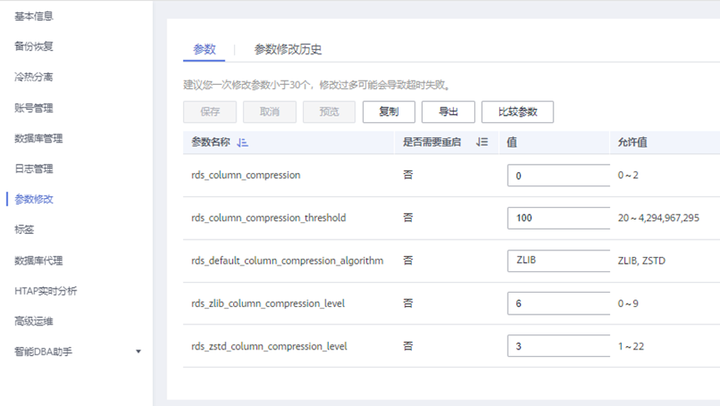
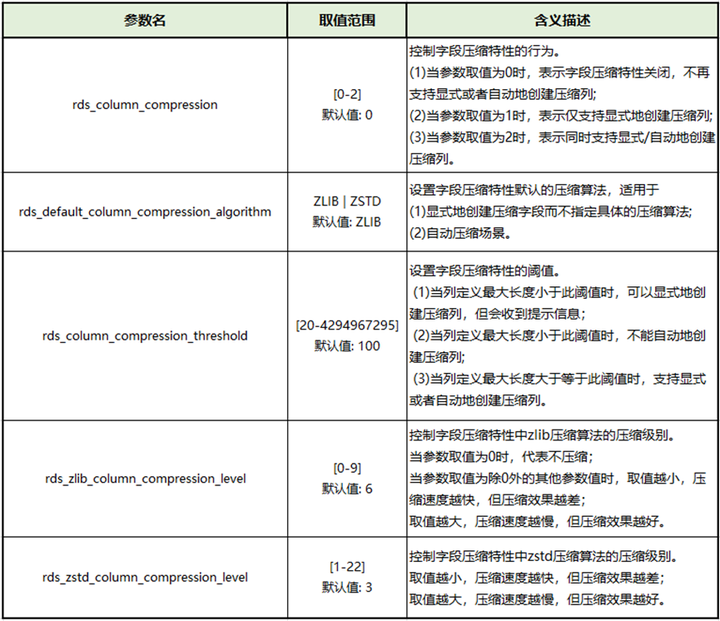
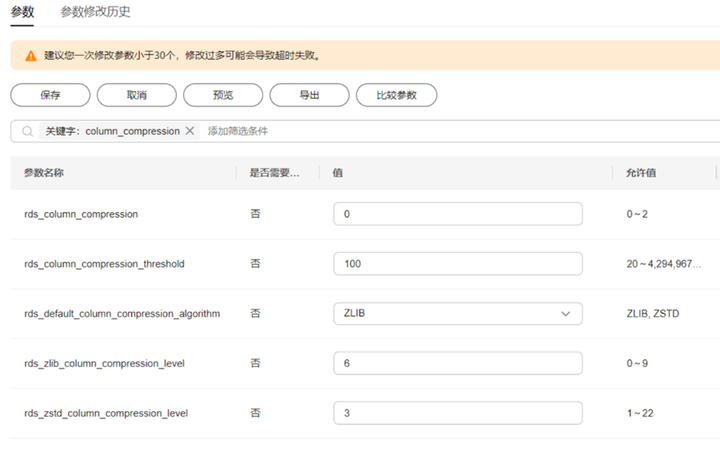
为了使得TaurusDB字段压缩特性更方便地被用户所使用,已开放5个相关参数,在“实例管理”处点击“参数修改-参数”页面即可调整字段压缩参数,如图5所示。
图5 调整字段压缩参数
表1 字段压缩参数说明
4.2 使用
例如,显式地创建压缩字段(如图5,设置默认压缩算法参数rds_default_column_compression_algorithm=ZLIB),在SQL语句中对需要进行压缩的字段显式地标记出压缩属性compressed,若不单独指定压缩算法,则按照rds_default_column_compression_algorithm参数指定的算法使用。
图6 显式压缩参数设置
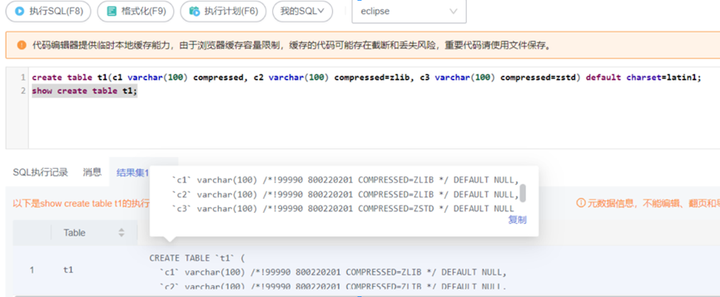
create table t1(c1 varchar(100) compressed, c2 varchar(100) compressed=zlib, c3 varchar(100) compressed=zstd) default charset=latin1;
对t1表中的三列显式添加压缩属性,并对c3列单独指定压缩算法为ZSTD,查看显式压缩添加的压缩属性,如图7所示。
图7 查看压缩属性
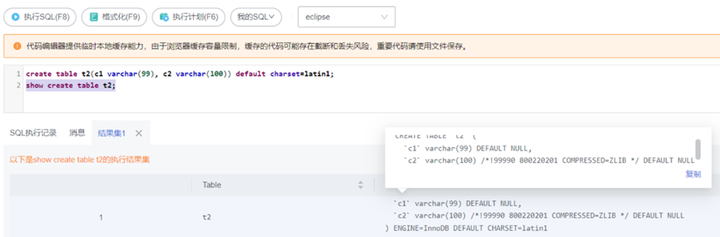
例如,自动地创建压缩字段(如图8,设置字段压缩阈值参数rds_column_compression_threshold=100,设置默认压缩算法参数rds_default_column_compression_algorithm=ZLIB),SQL语句不需要改造,自动对符合条件的列添加压缩属性。
图8 自动压缩参数设置
create table t2(c1 varchar(99), c2 varchar(100)) default charset=latin1;
系统将自动为t2表的c2列添加压缩属性,使用rds_default_column_compression_algorithm参数值作为默认压缩算法,查看自动压缩添加的压缩属性,如图9所示。
图9 查看压缩属性
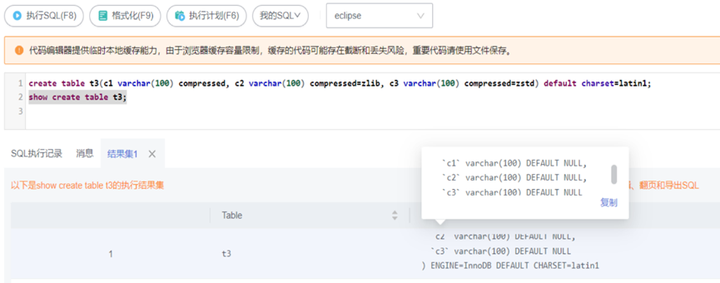
关闭特性后,无法再继续对列添加压缩属性,设置参数如图10所示。
图10 关闭压缩参数设置
create table t3(c1 varchar(100) compressed, c2 varchar(100) compressed=zlib, c3 varchar(100) compressed=zstd) default charset=latin1;
即便已对列添加压缩属性,但实际不生效,关闭效果如图11所示。
图11 查看关闭效果
通过展示表结构信息,如果发现其中包含/*!99990 800220201 COMPRESSED=xxxx */的注释内容,可认为该表中的某些字段已使用字段压缩特性,例如:
mysql> show create table t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`c1` varchar(100) /*!99990 800220201 COMPRESSED=ZLIB */ DEFAULT NULL,
`c2` varchar(100) /*!99990 800220201 COMPRESSED=ZLIB */ DEFAULT NULL,
`c3` varchar(100) /*!99990 800220201 COMPRESSED=ZSTD */ DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
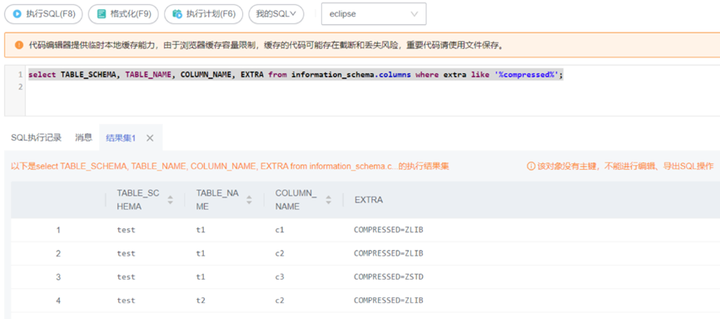
利用系统视图information_schema.columns查询压缩字段,执行如下SQL语句,
select TABLE_SCHEMA, TABLE_NAME, COLUMN_NAME, EXTRA from information_schema.columns where extra like '%compressed%';
图12 通过系统视图查询压缩字段
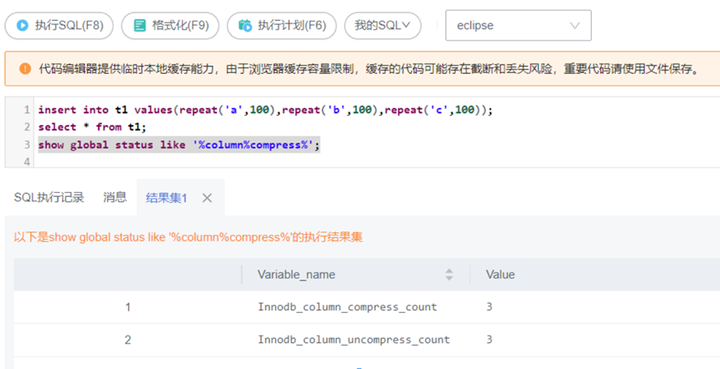
通过查询status信息,来确认字段压缩/解压缩接口的实际调用次数。例如,在将参数设置为rds_column_compression_threshold=20之后,对上述t1表进行插入数据以及查询数据操作,执行如下SQL语句,
show global status like '%column%compress%';
图13 查看压缩/解压缩接口调用情况
在表数据占用的存储空间较大时,可以通过查看监控界面信息来对比压缩前后存储占用大小,用于确认压缩效果。
5.总结
为了验证字段压缩的应用效果,通过构造两种场景来进行对比实验。
场景一如下所示。表中有1万行数据,每行数据是由400个MD5函数返回的32位字符串构成。
CREATE TABLE `random_data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`data` longtext,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
DELIMITER $$
CREATE PROCEDURE `generate_random_data`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT DEFAULT 1;
DECLARE str longtext;
WHILE i <= 10000 DO
SET j = 1;
SET str = '';
WHILE j <= 400 DO
SET str = CONCAT(str, MD5(RAND()));
SET j = j + 1;
END WHILE;
INSERT INTO `random_data` (`data`) VALUES (str);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
场景二如下所示,通过sysbench导入64张表,每张表包含1000万行数据,其中c和pad字段的数据类型被更改为varchar。
CREATE TABLE `sbtest1` (
`id` int NOT NULL AUTO_INCREMENT,
`k` int NOT NULL DEFAULT '0',
`c` varchar(120) COLLATE utf8mb4_0900_bin NOT NULL DEFAULT '',
`pad` varchar(60) COLLATE utf8mb4_0900_bin NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=10000001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin
通过将`rds_column_compression`参数分别设置为0(表示不压缩)和2(表示启用压缩),并在保持其他参数为默认值的情况下,我们在两种不同的场景进行了对比测试。结果显示,对于场景一,表压缩前后的存储大小比约为1.8,而场景二的这一比值则约为1.2,且压缩后的性能损耗最高在10%左右。
这表明,TaurusDB的字段压缩功能,不仅支持用户根据需求进行自选压缩算法等操作,实现细粒度的压缩策略调整,还能够自动识别并压缩符合条件的字段,从而在减少存储成本的同时,避免了对业务语句的大量修改,极大地方便了用户对特定字段进行高效压缩存储,具有较好的实际应用价值。