2025年伊始,Django的作者之一Simon Willison,带我们回顾了2024年AI的重磅进展,堪称大模型的“里程碑”盘点。快来看看有哪些突破,刷新了我们对AI的认知!
原文很长,下面给大家列几个关键点:
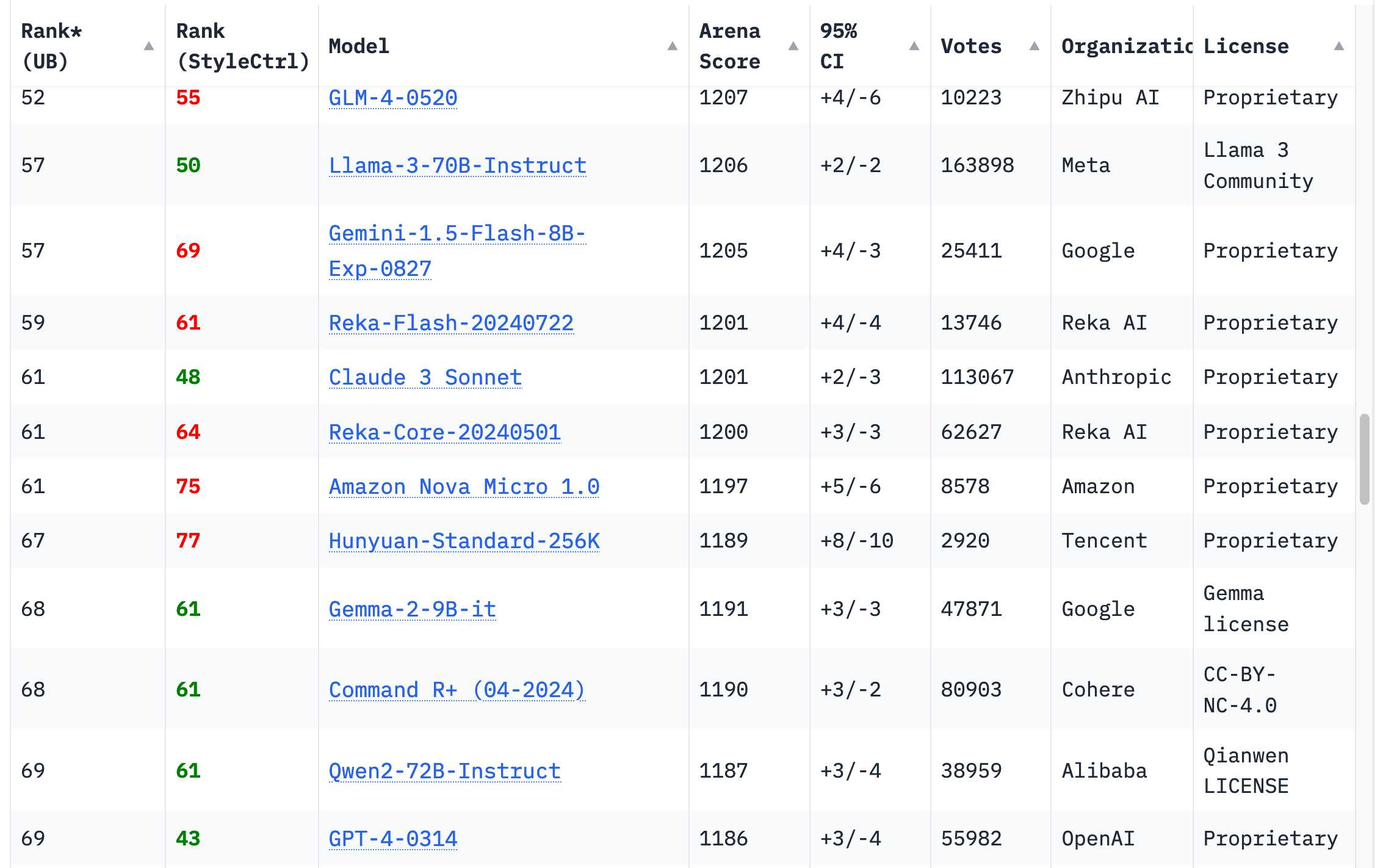
- GPT-4壁垒被突破:从前,GPT-4 被视为无人能及的高度智能“天花板”,现在,Chatbot Area排行榜上已经有近 70 个模型,超过了2023年3月版本的 GPT-4。谷歌的 Gemini 1.5 Pro 不仅在输出质量上与GPT-4持平,还引入了1百万到2百万的上下文长度,以及视频输入能力。这些新功能彻底颠覆了我们对LLM应用的想象。
![]()
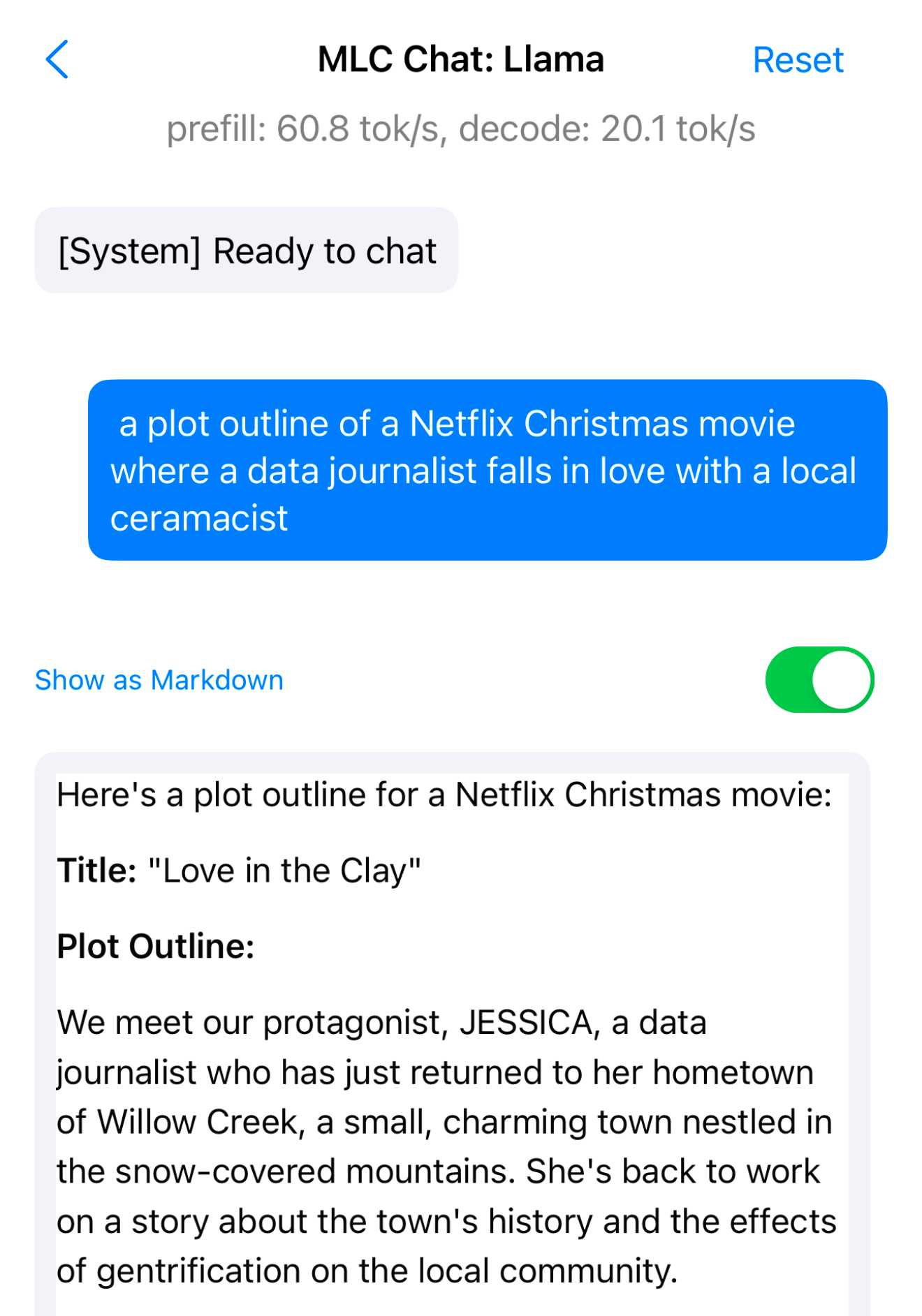
- 本地运行大模型:令人震撼的是,一些 GPT-4 同级模型已经可以在配置较高的笔记本上运行,如Meta的Llama 3.2 3B模型不仅可以在 MacBook Pro 上运行,还能通过免费的 MLC Chat iOS 应用在 iPhone 上运行。这意味着即便是移动设备,用户也能体验到强大的AI能力。
![]()
- LLM价格全面下跌:大量参与者带来的内卷,以及模型推理效率的提升,使得 LLM 的成本断崖式下降。以前昂贵的 API 费用,如今已经便宜到小团队也能轻松负担。谷歌的 Gemini 1.5 Flash 8B,为68000张图像生成一句话描述,总成本仅为1.68 美元,这比去年 GPT-3.5 Turbo 的费用下降了近27倍,极大地推动了LLM的普及。
- 多模态能力爆发:2024 年,多模态模型进入主流视野。除了文字,还能对图片、音频甚至视频进行处理。有些模型还能实时接收语音和视频输入,让人与 AI 的交互科幻味十足。如 OpenAI 的 GPT-4o 模型新增了语音和实时摄像头模式,用户可以通过语音与AI互动,甚至实时分享摄像头画面进行分析。谷歌的 NotebookLM 则能生成逼真的播客对话,展现了多模态 AI 的无限可能。
- 应用开发门槛降低:越来越多的 LLM 支持“一键式”生成代码、网页,甚至是交互式应用,整个开发流程在聊天界面就能完成, Claude Artifacts的出现,更是将低代码应用开发推向了高潮。此外,GitHub Spark 和 Mistral Chat 的 Canvas 功能也让开发者轻松构建应用。
- 智能Agent尚未到来:虽然 LLM 被寄予厚望,但让模型完全自主决策、执行任务的“智能Agent”仍面临可靠性难题,谷歌Search曾错误描述不存在的电影“Encanto 2”,说明 LLM 在信息准确性上还存在局限性。
- 数据中心与环保:谷歌、Meta、微软和亚马逊等公司都花费数十亿美元建设新的数据中心,甚至有人提议建造新的核电站为其供能。这无疑会对环境造成进一步影响,如何在效率与可持续发展之间取得平衡仍是焦点。
- AI垃圾充斥网络:2024 年,人们用“AI垃圾”来形容那些没有审核、胡乱生成的 AI 生成文字。由于AI生成的文章数量激增,国外某些杂志居然暂停接受投稿。此外,“AI洗稿”操作也让短视频内容同质化严重,甚至出现许多不符合事实的内容。随着AI生成内容的爆炸式涌现,如何避免低质量文字泛滥,成了一个新课题。
- 合成数据训练模型:随着数据越来越稀缺,新模型训练时,开始采用更大模型生成的“合成数据”。如 DeepSeek v3 使用了 DeepSeek-R1 的推理数据,训练成本仅为557.6万美元,相比 Meta 的 Llama 3.1 405B 模型的3084万美元,成本低了近11倍。OpenAI创始成员 Karpathy 称赞 DeepSeek V3,在有限预算上训练模型预更容易了,Meta科学家田渊栋也称其训练过程为“黑科技”。
- 专业门槛依旧存在:即便模型越来越强大,实际应用中依旧需要熟练掌握提示词、API 调用、工具接入等“高级技巧”,才能让AI发挥最大价值。例如,用户需要理解CSP和CORS HTTP头信息才能构建与外部API交互的Claude Artifact,否则容易遇到安全问题,这对普通用户来说仍是不小的挑战。
感兴趣的小伙伴可以阅读原文:https://simonwillison.net/2024/Dec/31/llms-in-2024/