Rodimus,在《变形金刚》里是擎天柱的继任者,新一代汽车人领导人。
在大模型的世界里,它有了新的身份。
“希望这个模型成为低推理复杂度下的下一代 LLM 架构。”现在,Rodimus 正作为蚂蚁自研的大型代码语言模型 CodeFuse 中的一个重要组成部分,支撑 CodeFuse 的飞速发展。
12月28日,在「AI 为伍 开源同行」2024 OSC 源创会年终盛典上,蚂蚁集团高级算法专家余航发表了《CodeFuse 基座模型系列介绍》主题演讲,余航介绍,CodeFuse 的使命是开发专门设计用于支持整个软件开发生命周期的大型代码语言模型(Code LLMs),涵盖设计、需求、编码、测试、部署、运维等关键阶段。
![]()
随着垂域大模型的普及,以及AI辅助编程能力的提升,代码大模型应运而生,从早期的代码补全工具到具备高度智能的编程助手,再到如今的代码大模型。一方面,模型能力不断提升,能够处理更复杂的推理需求,具备逻辑推理和问题解决能力。另一方面,业务侧也在要求大模型写出的代码能够适应复杂业务的需求,同时具备安全性,真正可被用到工程中。
基于业务的需求,以及自身技术的积淀。2023年年初,CodeFuse 在蚂蚁内部立项,定位是代码大模型。历经将近两年的发展,CodeFuse已经形成了一个较为完整的生态。余航在本次大会上,着重介绍了Rodimus、代码向量搜索模型 CGE、仓库理解模型 CGM 三大部分。
下一代LLM: Rodimus
余航指出,现有的 Transfomer 架构的大模型虽然具备建模能力强和并行化训练的优点,但也存在许多缺点,如推理一个 token 的复杂度为O(T),T 为生成这个 token 之前的上下文长度;整体的推理复杂度为序列长度的平方级,用1张A10推理卡,Llama-7B 在没有任何推理优化的情况下,生成一个2K长度序列,需要1分钟以上。
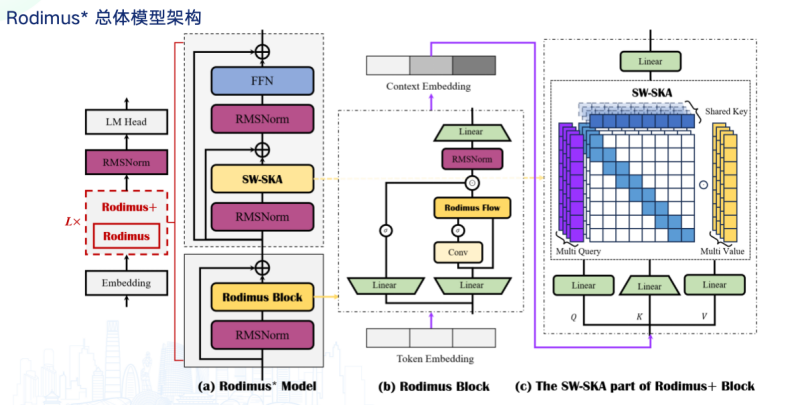
因此,Rodimus 希望在保持Transfomer 优点的前提下,解决推理复杂度的问题,把平方级的推理难度降低到限行次方,实现推理优化加速。此外,Rodimus 还希望缩小模型体积,实现端侧部署可用。
具体实现路径上,Rodimus 的计算公司从 Softmax Attention 变更为 Linear Attention。训练可并行,但复杂度为sub-quadratic。推理可串行,复杂度为 linear。其自回归的架构,相比传统的Transformer 和 Llama 架构,推理复杂度更低,但也可以适配并行训练。
同时,在推理每个token的过程中,Rodimus 架构能够保持较低的常量内存占用,这意味着在处理代码生成等任务时,它可以更高效地利用硬件资源,从而在资源有限的设备上更流畅地运行。
![]()
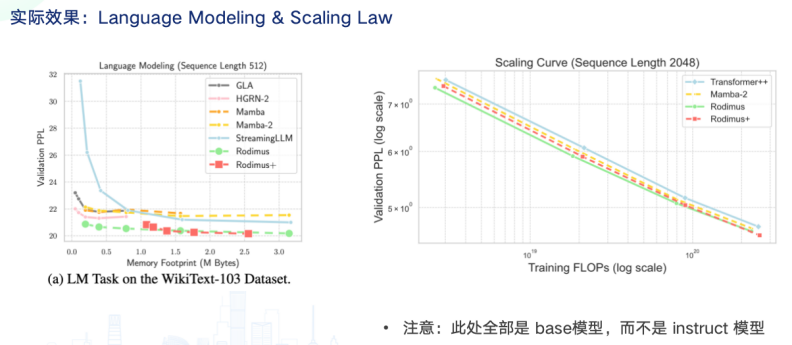
目前,1B 尺寸的 Rodimus 架构模型在性能上已超越同等大小的 Mamba2 和 LLaMA2 等模型。
![]()
代码搜索模型 CGE
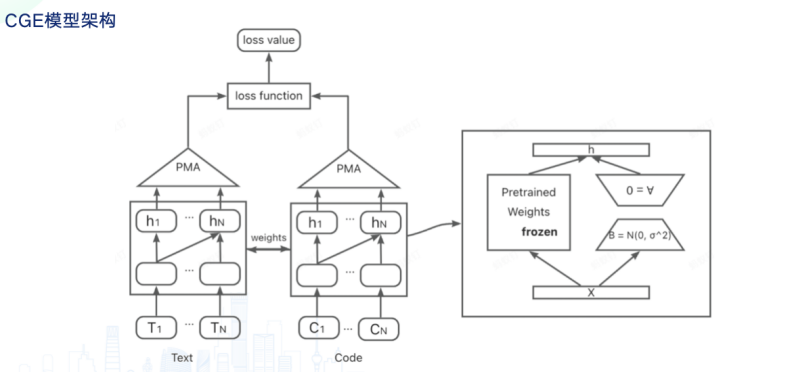
CodeFuse 也自研了代码向量搜索模型——CGE (Code General Embedding),把 Code LLM 改造成 Code Embedding 模型。
余航指出,Code Embedding 是仓库级别的代码任务中很重要的一个步骤,而现在的所有的 Code Embedding 模型都是从零开始训的 Encoder 架构 (BERT) 的 Embedding 模型。Decoder 架构的 LLM 一般训练的语料更多,存储的知识也更多,在各项任务上已经超过 Encoder 架构的模型,包括分类任务。
此外,Decoder 架构的 LLM 每个月都有更强大的模型开源,然而 Encoder 架构的模型更新速度明显不如 Decoder 架构。
因此,CodeFuse 提出了一个新的方式。余航介绍,CodeFuse 将 Decoder only 的架构改成 Embedding 模型,“我们希望将 Code LLM 改成一个 Code Embedding 模型,充分利用起 LLM 中的知识,在 Code Embedding 任务中表现得更好。”
![]()
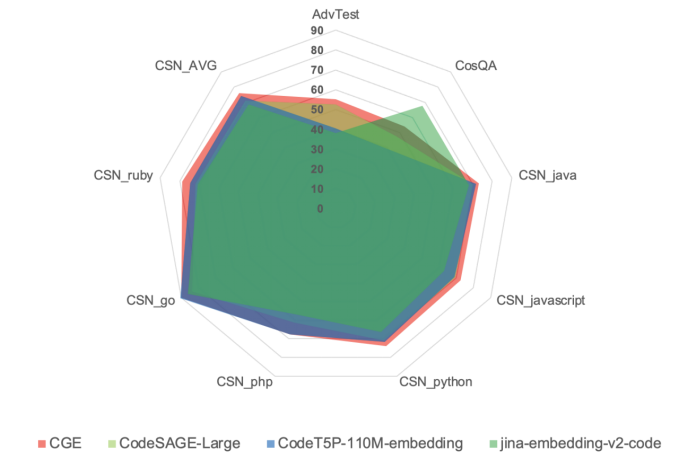
这样便有两个优势,一是只需要少量的微调数据就能产出一个SOTA级别的Code Embedding模型,实际中CGE在多项评测上都超过了现在其他的Code Embedding模型,比如CodeSage,Jina等;二是每个月 Decoder 模型案例都有更新,基于这些更好的模型,也能逐步提升 Embedding 模型的表现。
![]()
仓库理解模型CGM
最后压轴介绍的模型是 CGM (Code Graph Model)——理解仓库级别代码图的大模型,用于完成仓库级别代码任务。
“仓库级别的任务才是代码模型面对的常态,比如 issue fix,CR等,”余航介绍,业界现行方法通常是基于LLM agent去完成仓库级别的任务,因为任务的复杂性,agent一般比较复杂,里面的节点一般比较多。而节点越多,越不可控,越可能出现 error accumulation,同时耗时也会越长。并且现有的可以收集到的数据(比如 issue fix)是端到端的数据,没法很好的用于增强 agent 中的所有节点。
因此,CodeFuse 希望采用“Agentless”的方法,甚至是端到端的框架,让收集到的数据可以被使用,同时耗时缩短,可控性增强。
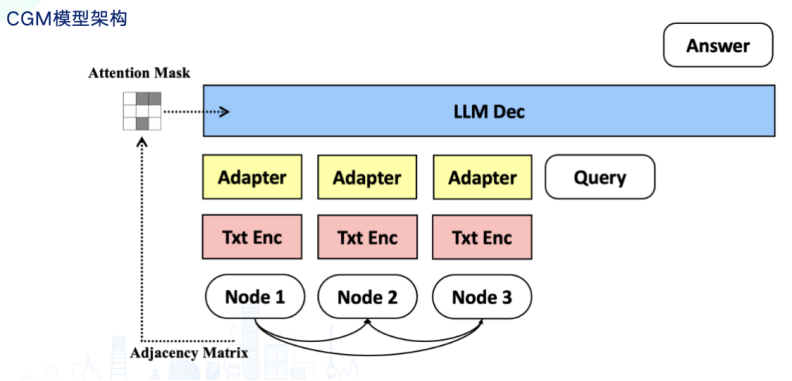
此外,仓库级别的代码任务通常面临长文本问题。因此模型也需要具备理解长文本的能力。具体而言,仓库里的方法与方法之间,文件与文件之间,有显式的依赖关系,如何充分的利用这些依赖关系来更好的完成仓库级别的代码任务?可行的实现路径便是让 LLM 理解 graph。首先,我们可以基于方法的调用关系,以及方法从属的类、文件、模块等关系,构建一张Code Graph。在Code Graph中,每个节点有对应的代码和文本,每条边表达了节点的关系。我们将每个节点做好text embedding,并通过adapter对齐到LLM的输入空间中。同时,图结构对应的邻接矩阵通过attention mask的方式输入LLM。
![]()
目前,CGM 在 SWE-Bench Lite 评测中表现卓越,两次位列开源榜单第一。SWE-Bench 是由普林斯顿大学提出的一个极具挑战性的、针对大模型解决真实 GitHub Issue 的评测集,是目前该领域最受关注和认可的评测。
在2024年 10 月底的首次评测中,CGM 以 35.67% 的解决问题率位居开源榜单第一。随后,在 12 月底的第二次评测中,CGM 进一步提升了表现,解决问题率达到 41.67%,再次跃居开源榜单首位。后续代码和CGM模型都会开源。
自2023 Q1 蚂蚁发布1.3B-2K模型,实现多语言代码补全,上线编程开发助手以来,CodeFuse 目前已进入 VAT(Virtual Agent Team)内测版本内测阶段,实现了仓库级别代码补全,IDE 插件对外开放,可支持数十种研发下游任务等能力。并且,CodeFuse 也已经在 2023 年 9 月开源,接下来,CodeFuse 也将继续探索更多新的能力。
“在小模型或是多模态模型的融合方面,社区还可以共同做许多事情。”未来,余航也希望CodeFuse 能与开源社区、更多技术社区联合,一起共建 CodeFuse 生态。
获取CodeFuse最新信息
CodeFuse 开源官网:https://codefuse.ai
你还可以扫描下方二维码直接加入群聊
![]()