作者:来自 Elastic Peter Titov
Elastic ECS 有助于改善日志字段的语义转换。了解如何量化规范化数据的好处,不仅是为了提高基础设施效率,也是为了提高数据保真度。
Elastic Common Schema 是一种简化和统一搜索体验的绝佳方式。通过将不同的数据源整合到通用语言中,用户在解释感兴趣的事件、解决事故或寻找未知威胁时可以降低难度。但是,有底层基础设施原因可以证明采用 Elastic Common Schema 是合理的。
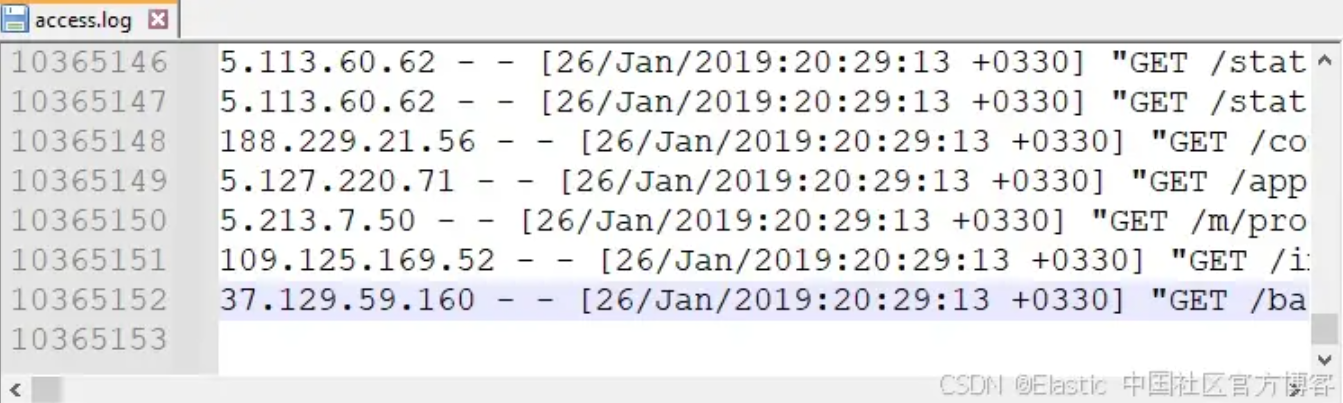
在本博客中,你将了解 ECS 的可量化运营优势、如何将 ECS 与任何数据采集工具结合使用以及应避免的陷阱。本博客中利用的数据源是从 Kaggle 获得的 3.3GB Nginx 日志文件。此数据集的表示分为三类:raw、self 和 ECS;其中 raw 数据集没有标准化,self 数据集是我与各种用户合作 5 年以上经验中观察到的常见错误的示例,最后是 ECS,它具有最佳的数据清理方法。
这种清理是通过解析、丰富和映射采集的数据来实现的;类似于 DNA 测序以表达遗传特征。通过了解数据的结构并分配正确的映射,可以表示、存储和搜索更全面的表达。
如果你想了解有关 ECS、本博客中使用的数据集或可用的 Elastic 集成的更多信息,请务必查看以下相关链接:
数据集验证
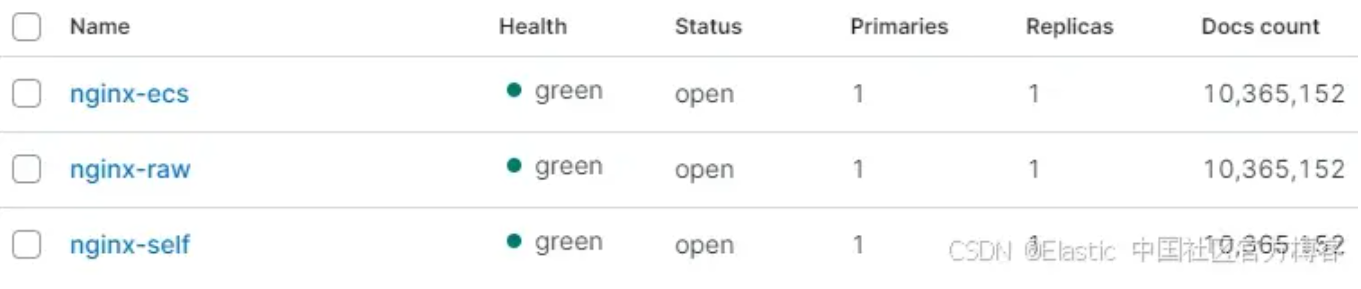
在开始之前,让我们先回顾一下有多少文档以及我们需要提取哪些内容。我们的 Nginx 日志文件中有 10,365,152 个文档/事件:
![]()
我们的目标最终状态中有 10,365,152 份文档:
![]()
数据集提取:raw 和 self 提取
为了实现 raw 和 self 提取技术,此示例利用 Logstash 以简化操作。对于原始数据提取,只需输入简单的文件,无需额外修改或索引模板。
input {
file {
id => "NGINX_FILE_INPUT"
path => "/etc/logstash/raw/access.log"
ecs_compatibility => disabled
start_position => "beginning"
mode => read
}
}
filter {
}
output {
elasticsearch {
hosts => ["https://mycluster.es.us-east4.gcp.elastic-cloud.com:9243"]
index => "nginx-raw"
ilm_enabled => true
manage_template => false
user => "username"
password => "password"
ssl_verification_mode => none
ecs_compatibility => disabled
id => "NGINX-FILE_ES_Output"
}
}
对于 self 摄取,创建了一个带有简单 Grok 过滤器的自定义 Logstash 管道,没有应用任何索引模板:
input {
file {
id => "NGINX_FILE_INPUT"
path => "/etc/logstash/self/access.log"
ecs_compatibility => disabled
start_position => "beginning"
mode => read
}
}
filter {
grok {
match => { "message" => "%{IP:clientip} - (?:%{NOTSPACE:requestClient}|-) \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:requestMethod} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" (?:-|%{NUMBER:response}) (?:-|%{NUMBER:bytes_in}) (-|%{QS:bytes_out}) %{QS:user_agent}" }
}
}
output {
elasticsearch {
hosts => ["https://myscluster.es.us-east4.gcp.elastic-cloud.com:9243"]
index => "nginx-self"
ilm_enabled => true
manage_template => false
user => "username"
password => "password"
ssl_verification_mode => none
ecs_compatibility => disabled
id => "NGINX-FILE_ES_Output"
}
}
数据集提取:ECS
Elastic 附带许多可用的集成,其中包含你需要实现的一切,以确保尽可能高效地提取数据。
![]()
对于我们的 Nginx 用例,我们将仅使用相关集成的资产。
![]()
安装的资产不仅仅是仪表板,还有摄取管道,它们不仅可以规范化数据,还可以丰富数据,同时通过组件模板将字段映射到正确的类型。我们要做的就是确保在数据进入时,它将遍历摄取管道并使用这些提供的映射。
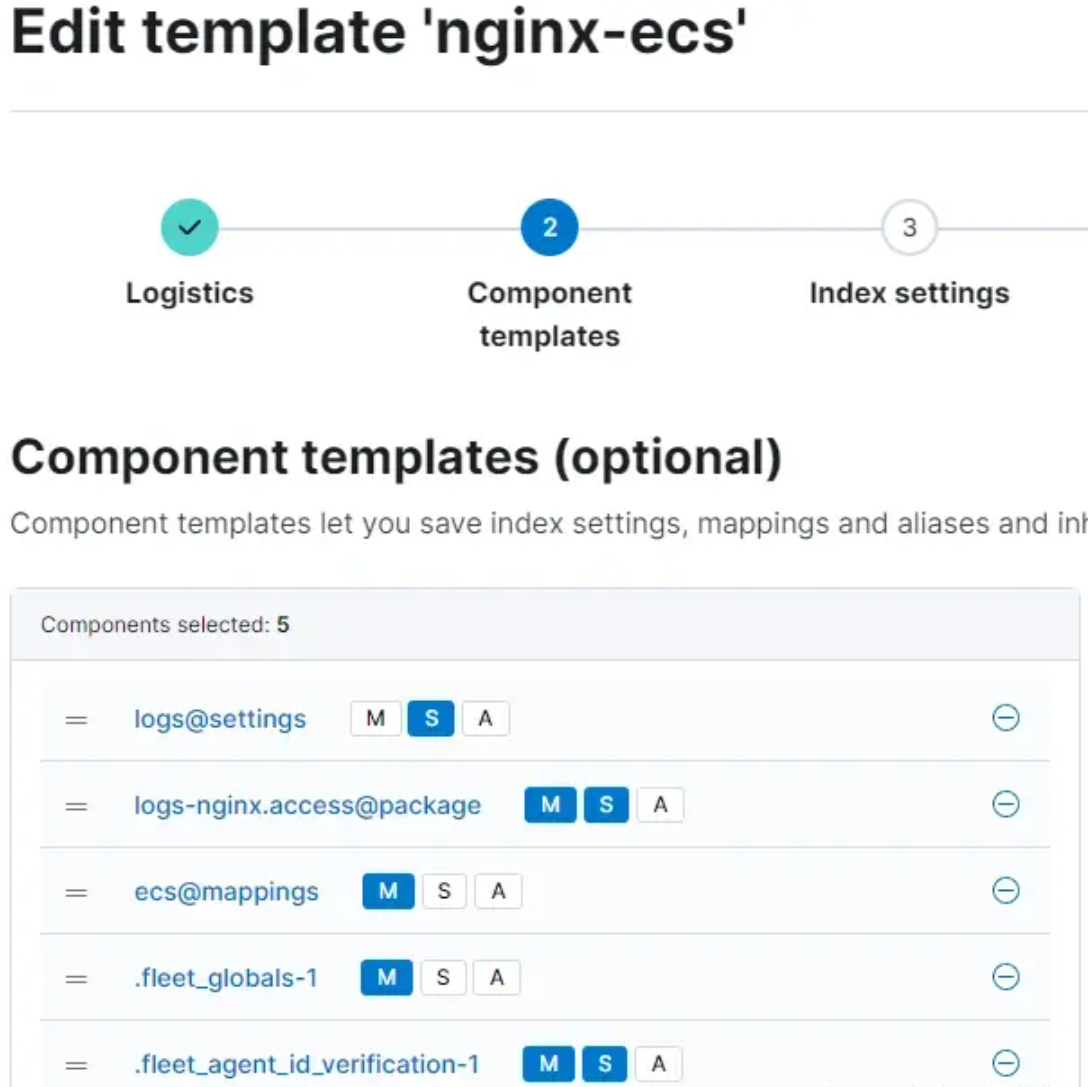
创建索引模板,然后选择集成提供的组件模板。
![]()
将组件模板视为索引模板的构建块。这些模板允许重复使用核心设置,从而确保在整个数据中采用标准化。
![]()
对于我们的提取方法,我们仅指向在索引模板创建期间指定的索引名称,在这种情况下,nginx-ecs 和 Elastic 将处理所有其余部分!
input {
file {
id => "NGINX_FILE_INPUT"
path => "/etc/logstash/ecs/access.log"
#ecs_compatibility => disabled
start_position => "beginning"
mode => read
}
}
filter {
}
output {
elasticsearch {
hosts => ["https://mycluster.es.us-east4.gcp.elastic-cloud.com:9243"]
index => "nginx-ecs"
ilm_enabled => true
manage_template => false
user => "username"
password => "password"
ssl_verification_mode => none
ecs_compatibility => disabled
id => "NGINX-FILE_ES_Output"
}
}
数据保真度比较
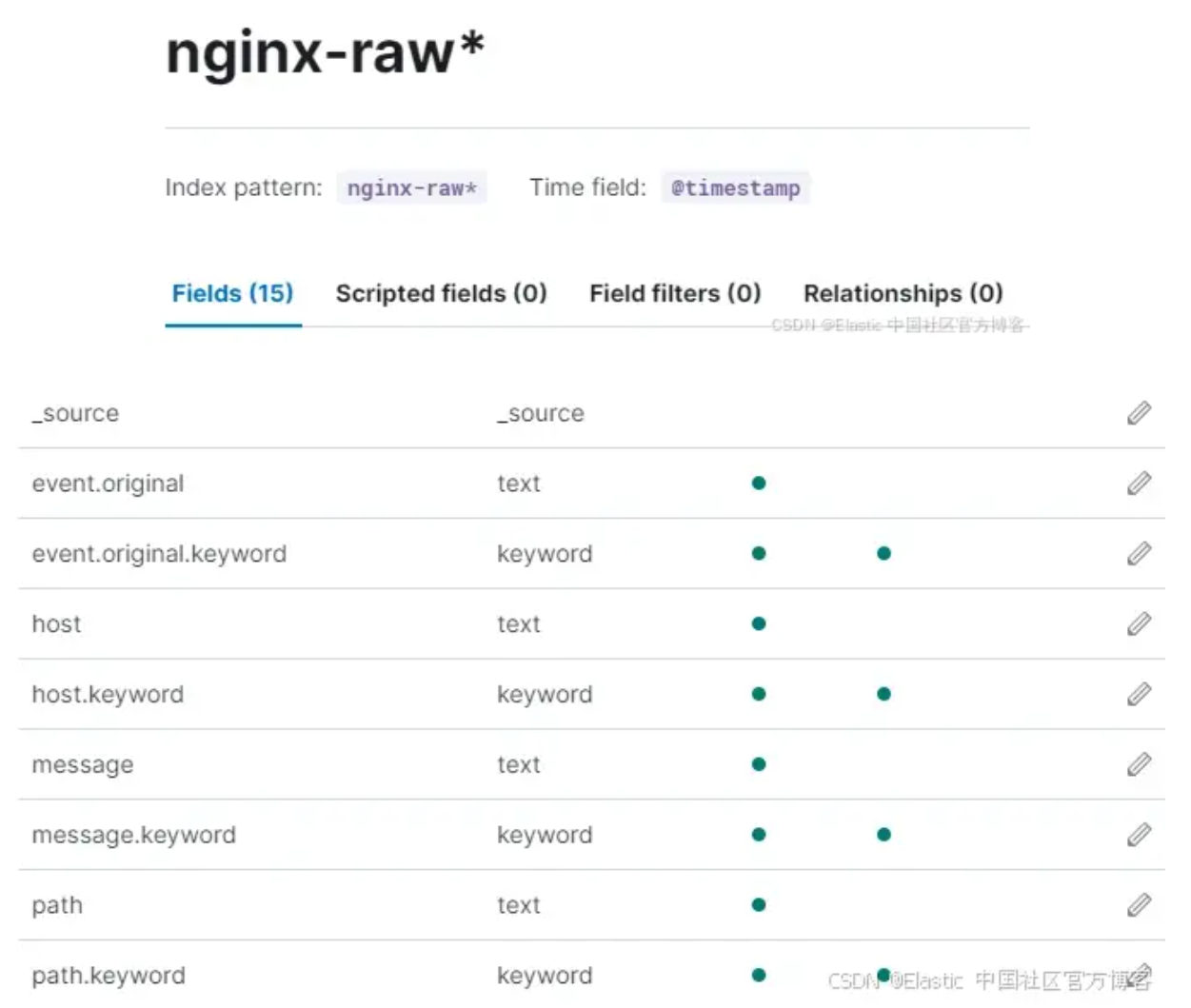
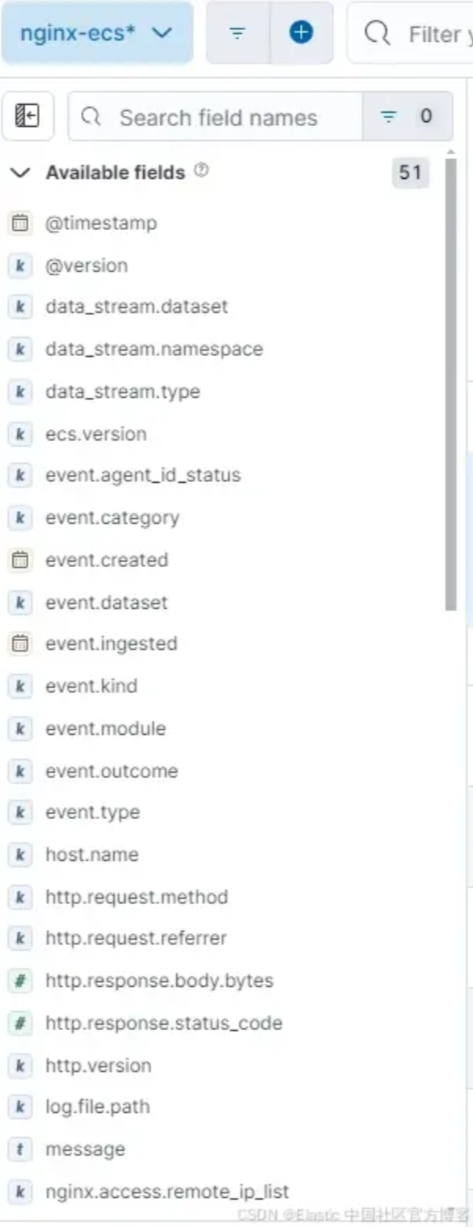
让我们比较一下这三个索引中有多少字段可供搜索以及数据的质量。我们的原始索引只有 15 个字段可供搜索,其中大多数都是出于聚合目的的重复项。
![]()
然而从发现的角度来看,我们仅限于 6 个字段!
![]()
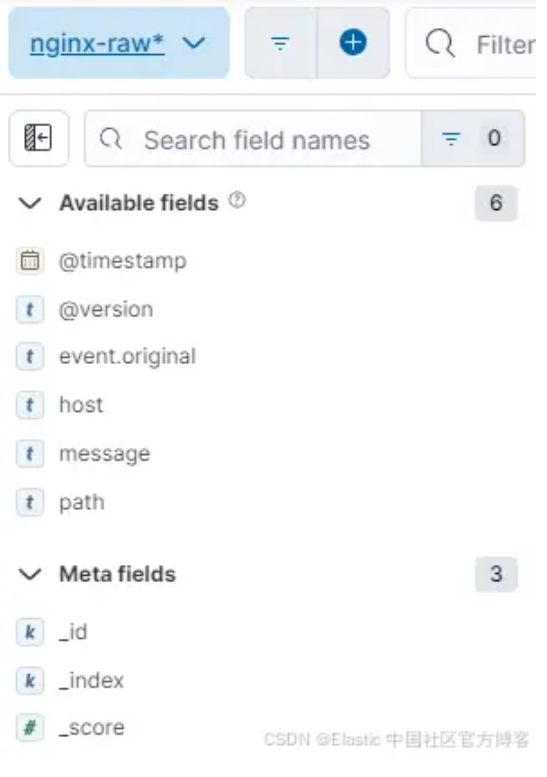
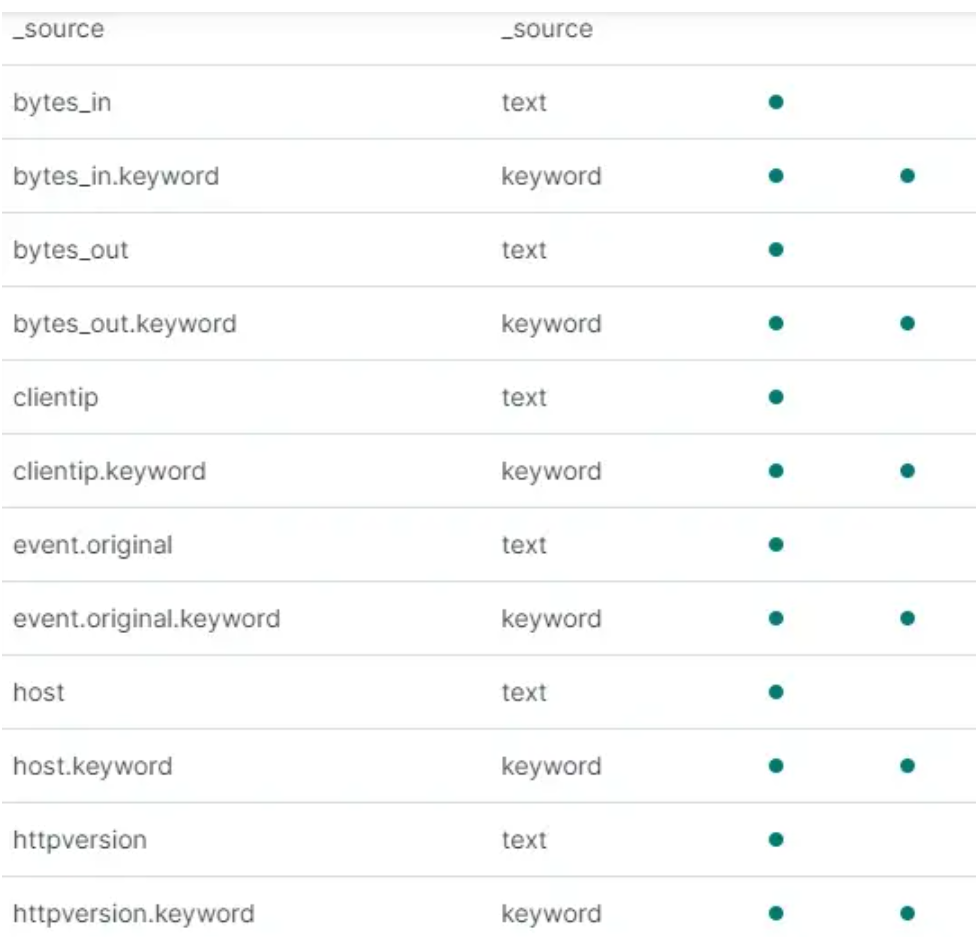
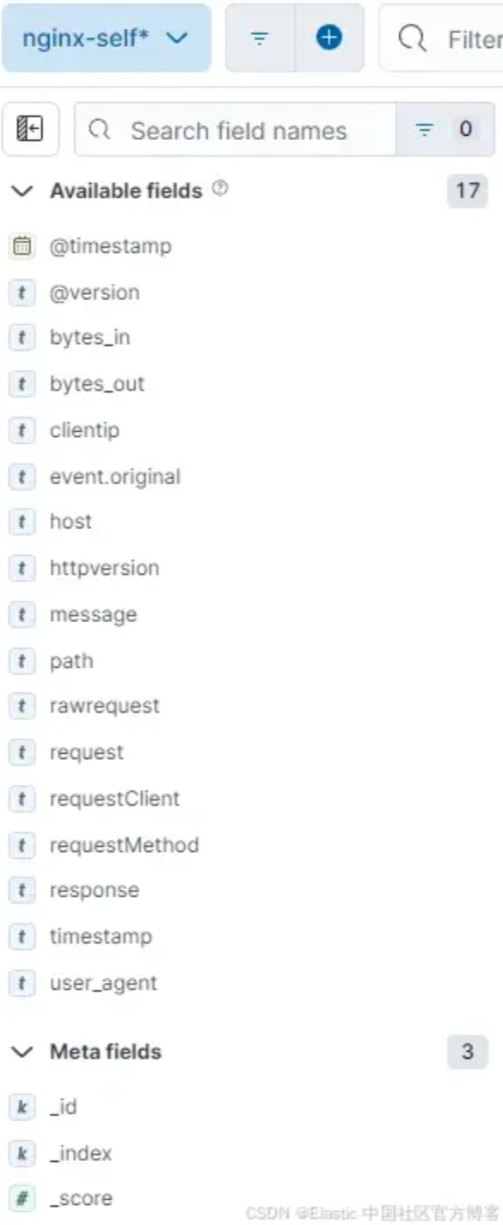
我们的 self 解析索引有 37 个可用字段,但这些字段也是重复的,对于高效搜索来说并不理想。
![]()
![]()
从 Discover 的角度来看,我们几乎有 3 倍的字段可供选择,但如果没有正确的映射,搜索这些数据的难易程度就不理想。一个很好的例子是尝试计算文本(text)字段的平均 bytes_in。
![]()
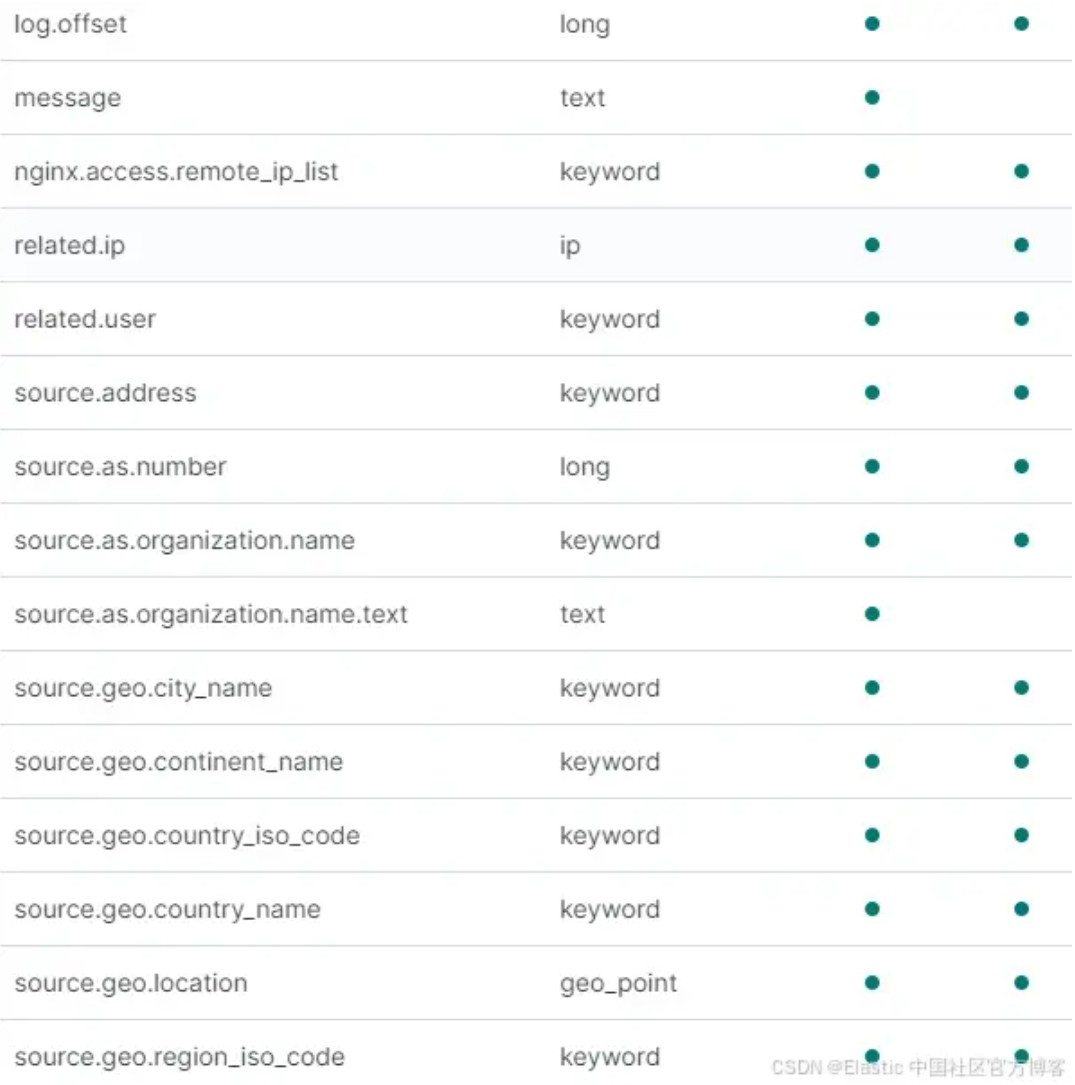
最后,通过我们的 ECS 索引,我们有 71 个字段可供使用!请注意,得益于摄取管道,我们丰富了地理信息字段以及事件分类字段。
![]()
![]()
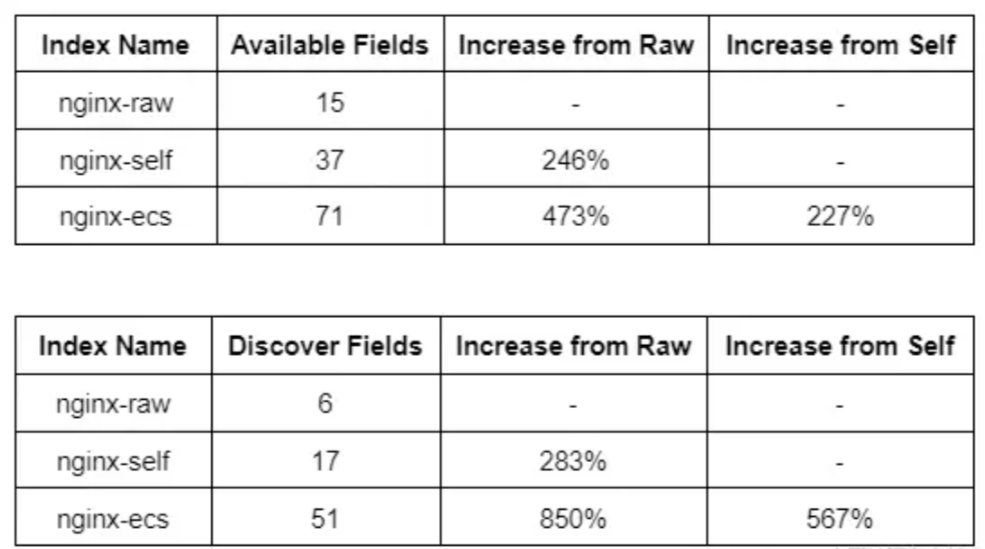
那么 Discover 怎么样?有 51 个字段可供我们直接搜索:
![]()
以 Discover 为基础,我们的 self 解析索引可搜索的字段增加了 283%,而我们的 ECS 索引则增加了 850%!
![]()
存储利用率比较
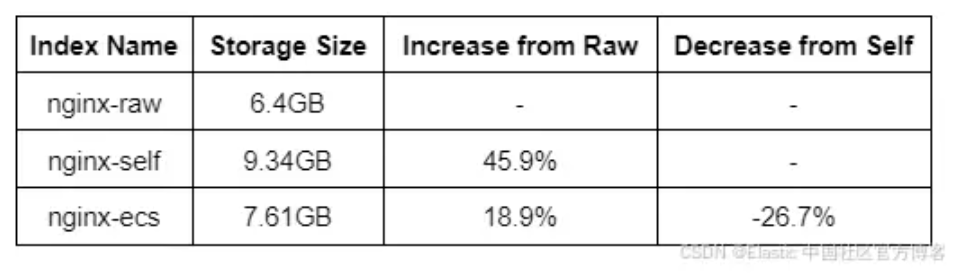
我们的 ECS 索引中包含所有这些字段,其大小肯定比 self 规范化索引大得多,更不用说 raw 索引了?结果可能会让你大吃一惊。
![]()
考虑到我们 3.3GB 大小数据集的数据副本,我们可以看到规范化和映射数据的影响对所需的存储量有显著的影响。
![]()
结论
虽然任何丰富的数据集所需的存储量都会增加,但 Elastic 提供了简单的解决方案,可以最大限度地提高要搜索的数据的保真度,同时确保操作存储效率;这就是 Elastic Common Schema 的强大之处。
让我们回顾一下我们如何能够最大限度地提高搜索能力,同时最大限度地减少存储
- 为我们将要提取的数据集安装集成(integration)资产。
- 自定义索引模板以利用所包含的组件来确保映射和解析与 Elastic Common Schema 保持一致。
准备好开始了吗?注册 Elastic Cloud 并试用我上面概述的功能和能力,以从你的数据中获得最大的价值和可见性。
原文:The DNA of DATA Increasing Efficiency with the Elastic Common Schema — Elastic Observability Labs