【摘要】MySQL 8.0.12版本引入了INSTANT(即时)算法,对部分ADD COLUMN操作,不再修改用户原有数据,只需对表元信息进行修改。
![]()
1. 背景介绍
数据库中每一行数据都被持久化存储在磁盘中。当我们对表进行ADD/DROP COLUMN操作时,磁盘中的数据也会相应地被修改,所需时间与对应表的大小成正比。因此,对大表进行ADD/DROP COLUMN操作时,花费的时间可能长达数小时或数天,这给用户的业务带来了诸多不便。
MySQL 5.5版本之前,只支持DDL的COPY算法。MySQL 5.6版本后,新增了支持INPLACE算法。两者区别在于是否能进行ONLINE DDL操作。对于ADD/DROP COLUMN操作,无论是COPY算法还是INPLACE算法,都需要修改用户原有数据,且没有解决耗时问题。
MySQL 8.0.12版本引入了INSTANT(即时)算法,对部分ADD COLUMN操作,不再修改用户原有数据,只需对表元信息进行修改。因此,操作时间与表大小脱钩,并且操作时间可以到秒级,但这个版本的 INSTANT 算法有以下几点问题:
MySQL 8.0.29版本中推出了INSTANT算法新的实现方式,解决了上述的2个问题。本文将分析最新INSTANT算法的实现方式。
2. INSTANT语法
ALTER TABLE tbl\_name ADD \[COLUMN\] col\_name column\_definition \[FIRST | AFTER col\_name\] , ALGORITHM=INSTANT;
ALTER TABLE tbl\_name DROP \[COLUMN\] col\_name , ALGORITHM=INSTANT;
注意 :
3. 原理分析
对于ADD/DROP COLUMN操作,之前提到的COPY/INPLACE算法都需要重建表,将磁盘中原有record进行修改。而INSTANT算法只需要修改表元信息,就可以快速完成ADD/DROP COLUMN操作。
INSTANT算法技术上需要解决什么问题?
我们通过一个例子来分析:
CREATE TABLE t1 (C1 char(10), C2 char(10), C3 char(10), C4 char(10));
INSERT INTO t1 values ("r1c1", "r1c2", "r1c3", "r1c4"); -- 数据一
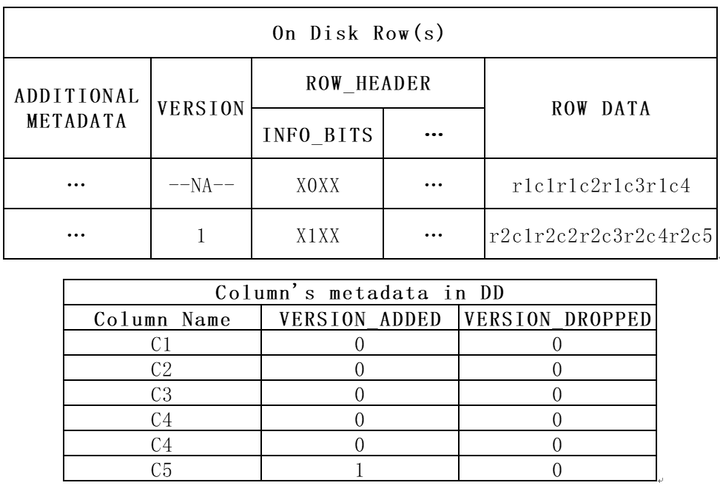
ALTER TABLE t1 ADD COLUMN C5 CHAR(10) DEFAULT "c5_def", ALGORITHM=INSTANT;
INSERT INTO t1 values ("r2c1", "r2c2", "r2c3", "r2c4", "r2c5"); -- 数据二
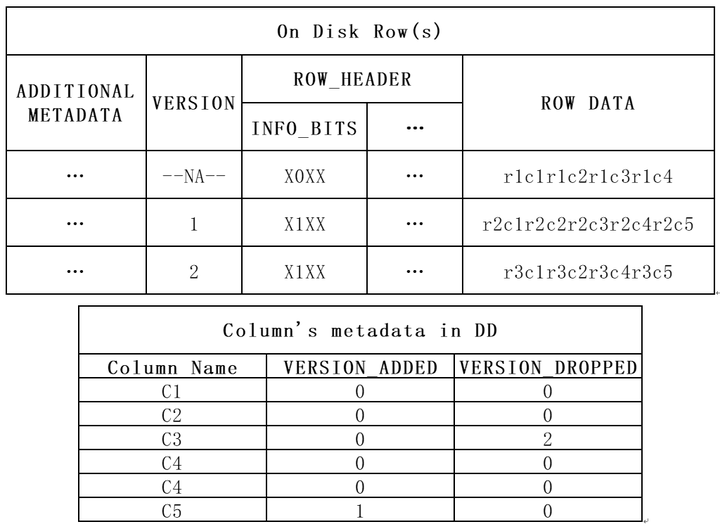
ALTER TABLE t1 DROP COLUMN C3, ALGORITHM=INSTANT;
INSERT INTO t1 values ("r3c1", "r3c2", "r3c4", "r3c5"); -- 数据三
SELECT * FROM t1;
+------+------+------+--------+
| C1 | C2 | C4 | C5 |
+------+------+------+--------+
| r1c1 | r1c2 | r1c4 | c5_def|
| r2c1 | r2c2 | r2c4 | r2c5 |
| r3c1 | r3c2 | r3c4 | r3c5 |
+------+------+------+--------+
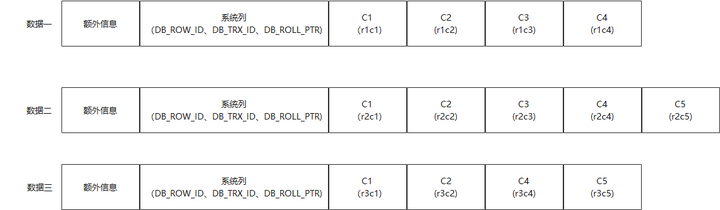
因为INSTANT ADD/DROP操作不会修改原有数据,所以可以推出数据在磁盘中分布如下:
![]()
图1 数据磁盘分布
可以看到,只有数据三的存储内容和当前表的元信息(表的列)匹配,数据三能正常解析读取。数据一多了C3列的值,但缺少了C5列的值,数据二则多了C3列的值。
于是问题出现了:如何正确解析返回老数据。若将解析和返回分开,则可以分为以下两个问题:
第一,解析。如何正确解析老数据?
第二,返回。老数据中缺少列如何填充?
注:这里老数据指的是存储内容和当前列不匹配的数据,上述例子中就是数据一、二。
INSTANT如何解决上述问题
如何解析
以COMPACT行格式为例,我们知道在record中存储数据是需要结合表的元数据(列类型、是否为空、是否变长等信息)进行解析的。
上述用例进行了多次DDL,每次都会修改表的元信息。所以在解析数据一、二、三时,所需的元数据版本肯定是不同的。
我们很自然会想到对元数据信息的历史版本进行维护。在解析数据一的时候,找到与数据一对应的元数据版本;在解析数据二时,找到与数据二对应的元数据版本,以此类推。
MySQL 8.0.29中INSTANT DDL功能的实现,在于引入了元数据version的概念。
如何返回
可以在INSTANT ADD COLUMN操作时,将新列的默认值存储在元数据中。对于缺少该新列的老数据,在返回客户端时,可直接使用默认值进行填充。
此方式在MySQL 8.0.12版本的INSTANT DDL就已经实现,并在MySQL 8.0.29版本中进行了沿用。
本次INSTANT算法的实现重难点在于元数据version实现,下文也将着重解释。
4、元数据version
元数据version实现涉及表元数据、列元数据、行格式三部分的修改。
表元数据
在INFORMATION_SCHEMA.INNODB_TABLES中新增了TOTAL_ROW_VERSIONS字段:记录当前表VERSION值,新建的表初始值为0,每次INSTANT ADD/DROP后值递增1,重建表后清零。
-- 新建表,TOTAL\_ROW\_VERSIONS为0
CREATE TABLE t1 (C1 char(10), C2 char(10), C3 char(10), C4 char(10));
INSERT INTO t1 values ("r1c1", "r1c2", "r1c3", "r1c4"); -- 数据一
SELECT NAME, TOTAL\_ROW\_VERSIONS FROM INFORMATION\_SCHEMA.INNODB\_TABLES WHERE NAME LIKE '%t1%';
+---------+--------------------+
| NAME | TOTAL\_ROW\_VERSIONS |
+---------+--------------------+
| test/t1 | 0 |
+---------+--------------------+
-- INSTANT ADD COLUMN,TOTAL\_ROW\_VERSIONS递增1
ALTER TABLE t1 ADD COLUMN C5 CHAR(10) DEFAULT "c5_def", ALGORITHM=INSTANT;
INSERT INTO t1 values ("r2c1", "r2c2", "r2c3", "r2c4", "r2c5"); -- 数据二
SELECT NAME, TOTAL\_ROW\_VERSIONS FROM INFORMATION\_SCHEMA.INNODB\_TABLES WHERE NAME LIKE '%t1%';
+---------+--------------------+
| NAME | TOTAL\_ROW\_VERSIONS |
+---------+--------------------+
| test/t1 | 1 |
+---------+--------------------+
-- INSTANT DROP COLUMN,TOTAL\_ROW\_VERSIONS递增1
ALTER TABLE t1 DROP COLUMN C3, ALGORITHM=INSTANT;
INSERT INTO t1 values ("r3c1", "r3c2", "r3c4", "r3c5"); -- 数据三
SELECT NAME, TOTAL\_ROW\_VERSIONS FROM INFORMATION\_SCHEMA.INNODB\_TABLES WHERE NAME LIKE '%t1%';
+---------+--------------------+
| NAME | TOTAL\_ROW\_VERSIONS |
+---------+--------------------+
| test/t1 | 2 |
+---------+--------------------+
-- 重建表,TOTAL\_ROW\_VERSIONS重置为0
ALTER TABLE t1 force;
SELECT NAME, TOTAL\_ROW\_VERSIONS FROM INFORMATION\_SCHEMA.INNODB\_TABLES WHERE NAME LIKE '%t1%';
+---------+--------------------+
| NAME | TOTAL\_ROW\_VERSIONS |
+---------+--------------------+
| test/t1 | 0 |
+---------+--------------------+
注意:在执行一次INSTANT ADD/DROP语句后,表VERSION的值会自增1,而不是针对每次添加或删除的列进行自增。如果一条语句增加了n个列,减少了m个列,表VERSION仍然只会自增1。
列元数据
在进行ADD/DROP COLUMN操作后,列元数据将进行修改。可以在mysql.columns表中体现。
CREATE TABLE t1 (C1 char(10), C2 char(10), C3 char(10), C4 char(10));
INSERT INTO t1 values ("r1c1", "r1c2", "r1c3", "r1c4"); -- 数据一
SET SESSION DEBUG = '+d,skip\_dd\_table\_access\_check';
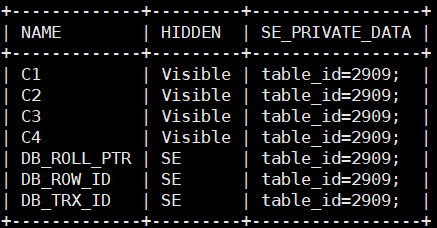
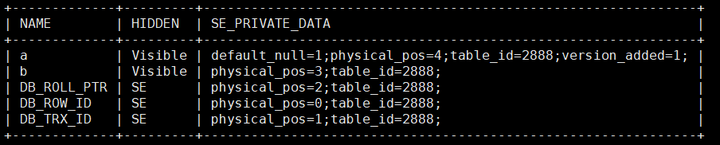
SELECT NAME, HIDDEN, SE\_PRIVATE\_DATA FROM mysql.columns WHERE table_id = (SELECT ID FROM mysql.tables WHERE NAME = 't1');
![]()
图2 列元数据查询结果
![]()
图3 磁盘数据分布
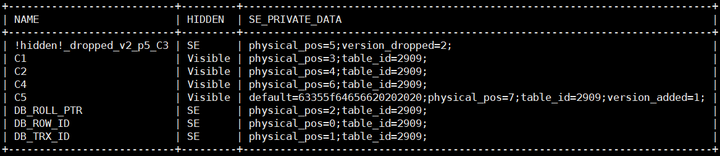
新建表列元数据如上图所示,HIDDEN列表示可见性。三个系统列的可见性为SE,代表INNODB可见,SERVER层不可见。SE_PRIVATE_DATA中也只记录着table_id。
下面将进行INSTANT ADD COLUMN操作。
ALTER TABLE t1 ADD COLUMN C5 CHAR(10) DEFAULT "c5_def" FIRST, ALGORITHM=INSTANT;
INSERT INTO t1 values ("r2c1", "r2c2", "r2c3", "r2c4", "r2c5");
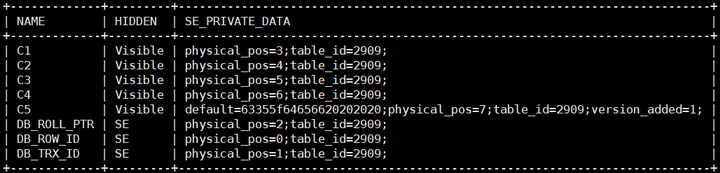
SELECT NAME, HIDDEN, SE\_PRIVATE\_DATA FROM mysql.columns WHERE table_id = (SELECT ID FROM mysql.tables WHERE NAME = 't1');
![]()
图4 列元数据查询结果
![]()
图5 磁盘数据分布
原有列变化(DB_ROLL_PTR、DB_ROW_ID、DB_TRX_ID、C1、C2、C3、C4)
- SE_PRIVATE_DATA中新增了physical_pos,表示列在record中的相对物理位置。为何是相对物理位置,后续说明。
ADD列变化(C5)
存储列的默认值,对于缺少该列的数据(如数据一),解析返回时将使用默认值。
- SE_PRIVATE_DATA中physical_pos
新增列的physical_pos为原表physical_pos最大值加1,说明该列的物理位置在行尾,此特性与新增列是否指定位置无关。
- SE_PRIVATE_DATA中version_added
值为本次INSTANT操作后表的VERSION,对于本例,添加后的表的VERSION值从0到1,故version_added记录为1。
下面将进行INSTANT DROP COLUMN操作
![]()
图6 列元数据查询结果
![]()
图7 磁盘上数据分布
DROP列变化(C3/ !hidden!_dropped_v2_p5_C3)
name
列元数据中C3列的名字已经修改为了 !hidden!_dropped_v2_p5_C3。v2代表在表version为2的时候删除的,p5表示此列的physical_pos为5。
可能有人会问:C3列不是被删除了么,为啥在元数据中还要保留C3列?另外,为什么要改名为 !hidden!_dropped_v2_p5_C3,而不直接沿用C3的名字?
那是因为部分record(数据一、数据二)中还有此列数据,解析record时需要所有列元数据,所以C3列的元数据需要保留。而关于改名成 !hidden!_dropped_v2_p5_C3,是因为C3列在逻辑上被删除了,后续若添加同名列(重新添加C3列),那么应该要添加成功。于是就换成由删除版本信息以及当前物理位置信息共同构成的一个名字。
hidden
将被删除列的可见性设置为SE,对存储引擎可见,但是对server层不可见,和DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID一样。因此,在Innodb层解析出该列数据后,这些数据不会返回到server层。
SE_PRIVATE_DATA中version_dropped
本次INSTANT操作后,表的VERSION更新为新的值。对于本例,删除列后的表的VERSION值从1变成2,故version_dropped记录为2。
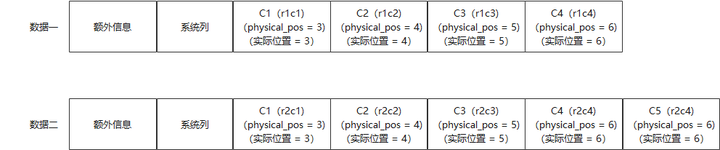
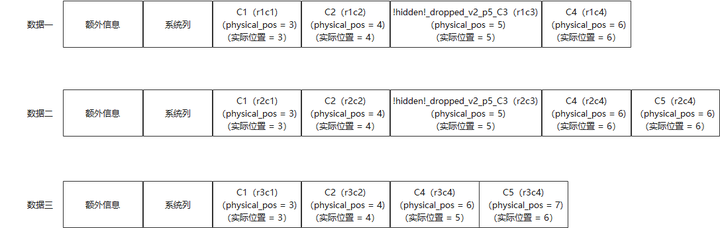
可以看到数据三C4列的physical_pos值为6,但是因为数据三中没有C3列的数据,所以,C4列数据实际在位置5。这说明physical_pos记录的是相对物理位置,要结合其他元信息才能确定该record中列的具体物理分布情况。
列元数据修改总结:
1. 经过instant操作后,所有列都将新增一个physical_pos字段记录的相对物理位置。
2. 对于instant add的列,新增version_added字段来记录添加后的表version值,并且列的physical_pos值为当前表最大的physical_pos值加1,与该列实际添加的位置无关。
3. 对于instant drop的列,元数据将被保留,但列名会进行修改名字,并将hidden属性设置为SE。
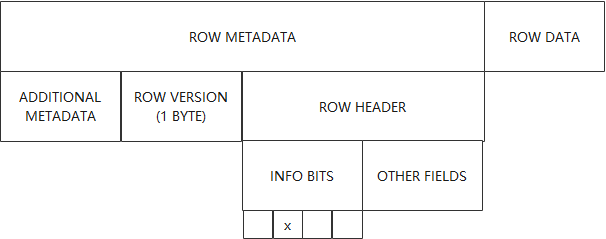
行格式
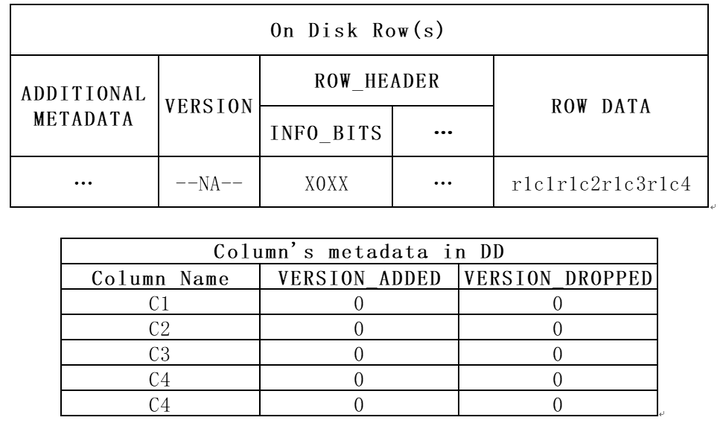
INSTANT思路是,对于磁盘中的每一行record,使用不同的元数据去解析。元数据修改如上文所述。但如何确定record对应元数据哪一个版本呢?所以需要修改行格式,确保在每条新产生的record中记录当前表VERSION信息。
![]()
图8 Instant修改后的行格式
本次修改包括:
VERSION BIT
INFO BITS是行格式原有字段,之前VERSION BIT所在的第二个比特位未被赋予含义。故已有的record此处值都为0。
本次实现规定:
ROW VERSION
本次实现规定:
注:如果表的VERSION不为0,那么表示该表曾经进行过INSTANT ADD/DROP操作,且之后未被重建。
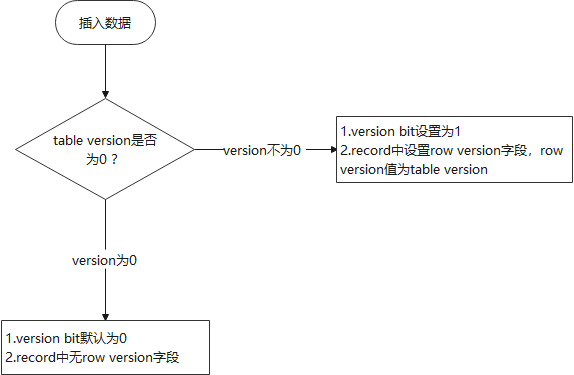
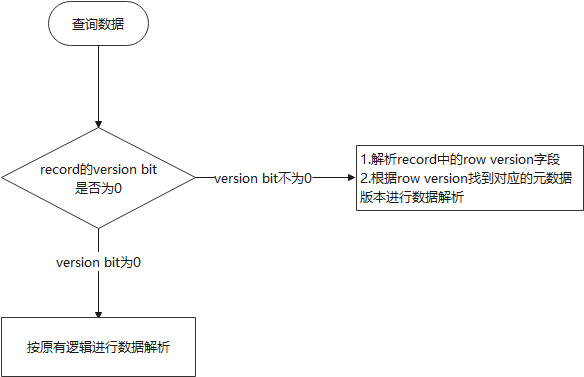
下面两图(图9和图10)体现插入和查询时如何使用version bit和row version。
![]()
图9 插入数据流程
![]()
图10 查询数据流程
INSTANT任意位置实现
在列元数据中提到:
1. 进行INSTANT操作后,列元数据中会维护一个physical_pos字段,用于记录该列在行中的相对物理位置。
2. 对于INSTANT ADD的列,physical_pos值都为原表最大值加1,说明新列的物理位置在行尾。
CREATE TABLE t1 (b int);
ALTER TABLE t1 ADD COLUMN a INT FIRST, ALGORITHM = INSTANT;
INSERT INTO t1 VALUES(1, 2); -- 数据一
SET SESSION DEBUG = '+d,skip\_dd\_table\_access\_check';
SELECT ID INTO @ID FROM mysql.tables WHERE NAME = 't1';
SELECT NAME,HIDDEN,SE\_PRIVATE\_DATA FROM mysql.columns WHERE TABLE_ID = @ID;
![]()
图11列元数据
从physical_pos可知,数据一的实际存储如下,b列数据在a列前面。
![]()
图12 磁盘数据分布
而我们期待的返回,a列应该在b列前面(a列添加时有FIRST关键字)。
![]()
图13 表查询结果
故需要维护一个逻辑位置和物理位置的对应关系。在 dict_index_t 结构体中新增名字为 fields_array 的成员。t1表的fields_array如下:
DB\_ROW\_ID: fields_array\[0\] = 0 物理和逻辑位置都是0
DB\_TRX\_ID: fields_array\[1\] = 1 物理和逻辑位置都是1
DB\_ROLL\_PTR: fields_array\[2\] = 2 物理和逻辑位置都是2
a: fields_array\[4\] = 3 物理位置是4,逻辑位置是3
b: fields_array\[3\] = 4 物理位置是3,逻辑位置是4
有了这个对应关系,从record中解析出的数据,可以以正确的逻辑顺序返回。
5. 解析/返回record
列元数据中引入了VERSION_ADDED、VERSION_DROPPED。解析/返回一个record,可以依照下面的规则:
1. 解析数据时,忽略VERSION_DROPPED > 0的列(表示已经被删除);
2. 返回结果时,对于VERSION_ADDED > ROW_VERSION的情况(record中无此列数据),使用该列元数据中默认值。
CREATE TABLE t1 (C1 CHAR(10), C2 CHAR(10), C3 CHAR(10), C4 CHAR(10));
INSERT INTO t1 VALUES ("r1c1", "r1c2", "r1c3", "r1c4");
ALTER TABLE t1 DROP COLUMN C3, ALGORITHM=INSTANT;
ALTER TABLE t1 ADD COLUMN C5 CHAR(10) DEFAULT "C5d", ALGORITHM=INSTANT;
SELECT * from t1;
图示:
+----------------------------------+
| Columns' Metadata in DD |
+---------+------------------------+
| Version | C1 | C2 | C3 | C4 | C5 |
+---------+------------------------+
| 0 | E | E | E | E | - | +---------------------------+
+---------+------------------------+ | Default value of C5 in DD |
| 1 | E | E | ID | E | - | +---------------------------+
+---------+------------------------+ | C5d |
| 2 | E | E | - | E | IA | +---------------------------+
+---------+------------------------+ |
E => Existing Column |
ID => INSTANT Dropped Column |
IA => INSTANT Added Column |
|
+----------------+-----+-----+-----+-----+ |
| V0 row on disk | r1c1| r1c2| r1c3| r1c4| |
+----------------+-----+-----+-----+-----+ |
| | x | +-----------+
| | x | |
V V V V
+-----------------+------+------+------+------+
| Row fetched | r1c1 | r1c2 | r1c4 | C5d |
+-----------------+------+------+------+------+
6. 用例总图解
新建表,插入数据一
CREATE TABLE t1 (C1 char(10), C2 char(10), C3 char(10), C4 char(10));
INSERT INTO t1 values("r1c1", "r1c2", "r1c3", "r1c4");
![]()
图14 数据和列元数据
![]()
ADD COLUMN,插入数据二
ALTER TABLE t1 ADD COLUMN C5 CHAR(10) DEFAULT "c5_def", ALGORITHM=INSTANT;
INSERT INTO t1 values ("r2c1", "r2c2", "r2c3", "r2c4", "r2c5");
![]()
图15 数据和列元数据
DROP COLUMN,插入数据三
ALTER TABLE t1 DROP COLUMN C3, ALGORITHM=INSTANT;
INSERT INTO t1 values ("r3c1", "r3c2", "r3c4", "r3c5");
![]()
图16 数据和列元数据
7. 总结
Instant 算法的原理大致如上。实现特点总结:
1. 修改元数据,不修改原有的数据,让ADD/DROP COLUMN操作的时间缩短到秒级;
2. 维护元数据版本,并修改行格式,让record找到对应的元数据版本进行解析;
3. 维护列的物理位置和逻辑位置的对应关系,以确保能够按照正确顺序将数据返回客户端。
INSTANT ADD/DROP COLUMN功能同样存在一些小问题,MySQL 8.0.29版本推出Instant算法最新实现后,一开始遇到了不少bug,导致社区也认为该版本是不稳定的,到8.0.33版本之后才逐渐稳定。我们在MySQL 8.0.37版本进行测试时,也发现2个bug,并已向社区反馈。
[1] https://bugs.mysql.com/bug.php?id=116035
[2] https://bugs.mysql.com/bug.php?id=115890
社区的改进极大优化了ADD/DROP COLUMN的效率,希望通过本文的介绍,读者对最新的实现有进一步的了解,欢迎交流。
参考:https://blogs.oracle.com/mysql/post/mysql-80-instant-add-drop-columns
点击关注,第一时间了解华为云新鲜技术~